Appearance-and-Relation Networks for Video Classification,CVPR2018
Two-tream网络效果好,但是太耗时;2Dconv+LSTM和其他方式的效果又不太好,主要是因为LSTM只能抓住高层次的模糊信息,不能抓住细粒度的运动信息。3Dconv的效果到目前为止也不太好。所以作者提出了一个新的网络结构---ARTNet,用叫做SMART的block去代替3D卷积操作。
SMART块结构如图:

一个SMART块由两个分支组成,共享输入,本文采用的是\(112 \times 112 \times 16\)帧输入。
表示为\(\mathbb{R}^{W \times H \times T \times C}\) 。
- 下面的分支主要通过常规的2D卷积逐帧提取空间信息;输出为\(\mathbb{R}^{{W}' \times {H}' \times {T}' \times {C}'}\) 。这里2D不涉及到时间,所以应该\(C={C}'\),但是论文中没有明确说,具体操作要看代码才知道。
- 上面的分支是2Dconv在时间域上的拓展,但是不同于3Dconv操作的希望同时获取时空信息,这里的设计为只获取空间信息。具体的操作是寻找适合表示相邻帧之间的小块区域x和y之间的relation的表示函数z。3D卷积的操作是\(z_k=\sum_{i}w_{ik}x_i+\sum_jw_{jk}y_j\)。但是这样的话就同时获取了content和relation信息,作者希望这个结构基本上只获取relation信息来提高性能,因为已经专门有一个分支去获取content信息了,所以作者提出了新的表达式\(z_k=\sum_{ij}w_{ijk}x_iy_j\),这样的z基本上就获取的是两个小块x和y之间的relation,但是这里存在的问题是参数太多了,文中说参数大概是像素点个数的立方(the number of parameters is roughly cubic in the number of pixels),我没太搞清楚立方是怎么来的。为了减少参数,作者把W分成了3部分,即\(W_{ijk}=\sum_{f=1}^Fw_{if}^xw_{jf}^yw^z_{kf}\)。所以\(z_k\)可以转化为
\[ \begin{aligned} z_k &=\sum_fw_{kf}^z\sum_iw_{if}^xx_i\sum_jw_{jf}^yy_i\\ &=\sum_fw_{kf}^z(\omega_f^{xT} \textbf{x} )(\omega_f^{xT}\textbf{y}) \end{aligned} \]
这里我没看懂是怎么推出来的,这里的思路是从[1]中获取的灵感,可能这篇论文会有更详细的推导。
这里\(z_k\)的表示和[2]中的能量模型的表达式很像,原表达式为
\[ \begin{aligned} z_k &=\sum_fw_{kf}(w_f^{xT}\textbf{x}+w_f^{yT}\textbf{y})^2 \\ &=\sum_fw_{kf}[2(w_f^{xT} \textbf{x})(w_f^{yT}\textbf{y})+(w_f^{xT})^2+(w_f^{yT})^2] \end{aligned} \]
文中说[3]证明了后面两个平方项对z的意义没有影响。这样的话就可以很轻松的用3D卷积来实现了。
(这里的转换我没有看懂,但是最后的结果看起来和之前的公式没有什么区别,只不过平方一下再乘了一个矩阵而已。另外这里的f我也没看懂是什么意思,论文中没有解释)
- 图中的3Dconv操作对应\(w_f^{xT}\textbf{x}+w_f^{yT}\textbf{y}\),Square对应平方操作,Cross channel pooling对应\(w_{kf}\)的乘积和。
- 两个分支的结果出来之后concatenate,然后reduce去压缩channel。两个分支的卷积核的个数和空间大小都是一样的,所有输出上路的U和下路的F的WHTC都是一样的,cross之后上路的C减半。
- SMARTblock的输出与一个3Dconv操作无异,所以可以用来代替3Dconv操作。
作者在ResNet18上替换实验,实验对比图如下:
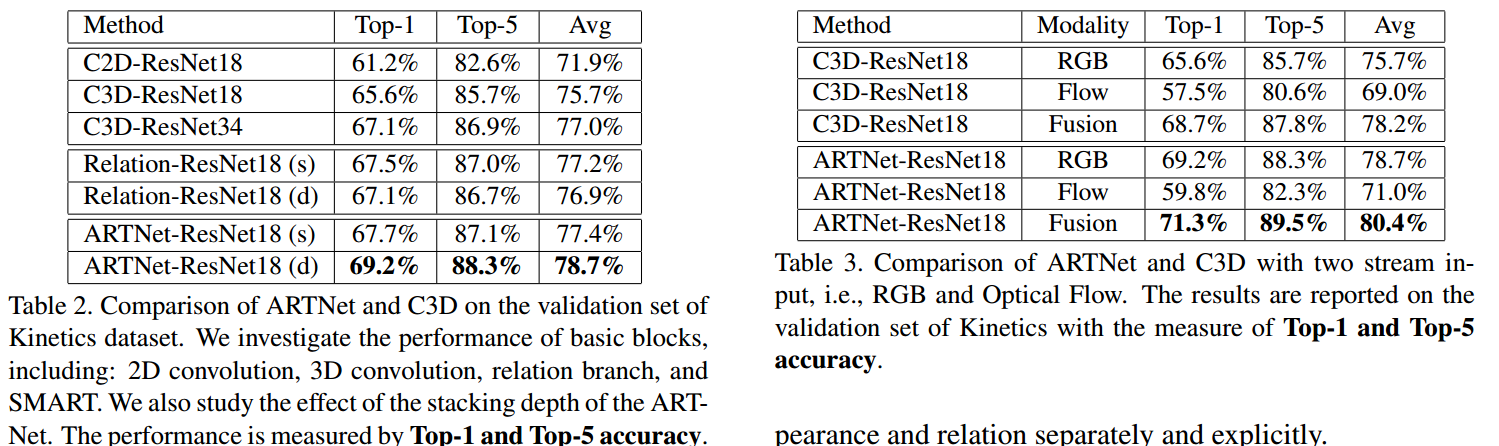
从Table2可以看出,3Dconv确实比2Dconv的效果要好,说明3Dconv确实能抓到运动信息,SMARTblock获得了最好的结果。纯Relation的堆叠效果不太好,说明还是缺乏空间信息,所以这个z的设计应该还是比较好的抓了运动信息。从Table3来看,ARTNet在two-tream上的提升远不如C3D的提升,说明这个结构的设计确实能有效的分别捕获静止空间特征和relation。
reference:
[1]R. Memisevic. Learning to relate images. IEEE Trans. Pattern Anal. Mach. Intell., 35(8):1829–1846, 2013.
[2]E. H. Adelson and J. R. Bergen. Spatiotemporal energy models for the perception of motion. J. Opt. Soc. Am. A,2(2):284–299, 1985.
[3]R. Memisevic. On multi-view feature learning. In ICML,2012.