版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/hongbin_xu/article/details/83280821
原文:Going Deeper with Convolutions
Inception v1
1、四个问题
- 要解决什么问题?
- 提高模型的性能,在ILSVRC14比赛中取得领先的效果。
- 最直接的提高网络性能方法有两种:增加网络的深度(网络的层数)和增加网络的宽度(每层的神经元数)。这样的做法有如下两个缺点待改进:
- 构建更大的网络也意味着会有更多的参数,这也会让网络更容易过拟合。
- 同时也会需要更多的计算资源。
- 用了什么方法解决?
- 作者认为解决前面提到的那两个问题的根本方法是将全连接层,甚至是卷积层都替换为稀疏连接。
- 但是使用稀疏连接会浪费大量的计算资源。如果要有更高的计算性能,需要使用较为密集的矩阵运算。
- 因此,作者的想法是寻找一种方法,既能保持网络结构的稀疏性,又能利用密集矩阵的高计算性能。
- 大量文献表明可以将稀疏矩阵聚类为密集矩阵来提高计算性能,作者依此提出了Inception结构。
- 效果如何?
- 在ImageNet2014获得分类任务第一名,力压VGG。
- 将Inception迁移到其他视觉任务上也可以取得state-of-the-art的效果。
- 还存在什么问题?
- Inception主要是为计算机视觉任务设计的,迁移到其他领域不一定有效。
- Inception v1现在也算比较老的网络,主要借鉴它的思想(要用还是会选择Inception v3/v4的)。
2、论文概述
2.1、结构细节
- Inception的主要思想是:设计一个结构,这个结构可以使用密集的成分来近似模拟一个局部稀疏的卷积神经网络结构。
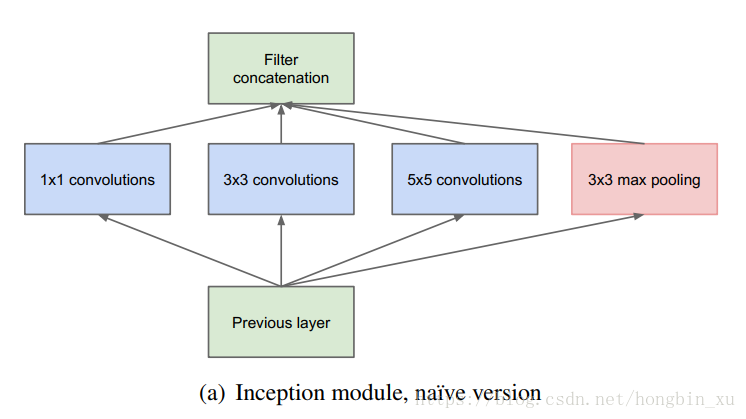
- 对Inception模块的说明:
- 采用几个不同的卷积核意味着具有不同大小的感受野,最后拼接在一起就意味着不同尺度特征的融合。
- 采用
、
和
的卷积核的目的是为了方便后面对齐。
- 假设卷积的步长 ,那么分别设定 ,那么卷积后可以直接得到相同维度的特征图,可以直接拼接在一起。
- 作者提到,pooling对于如今许多卷积神经网络的成功都有不可或缺的作用,所以他也在Inception内嵌入了 的max pooling。
- 网络越到后面,特征也越抽象。因为要将这些抽象特征进一步组合起来提取更高维的特征,网络不能只关注小范围内的特征信息了,所以需要让感受野大一些,看到更多的抽象信息。因此, 和 卷积的比例要增加。
- Inception模块还存在一个巨大的问题:那就是使用 卷积会带来大量的计算量。
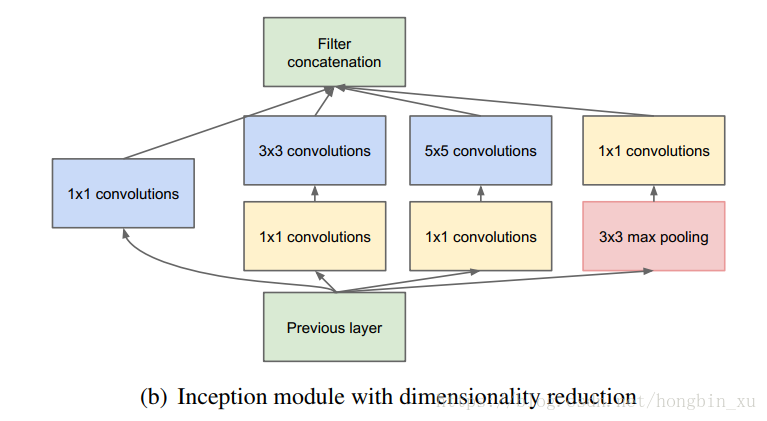
- 所以作者又借鉴了Network in Network论文中的方法,使用 卷积来降维,减少计算量。改进结构如下图:
2.2、GoogleNet结构
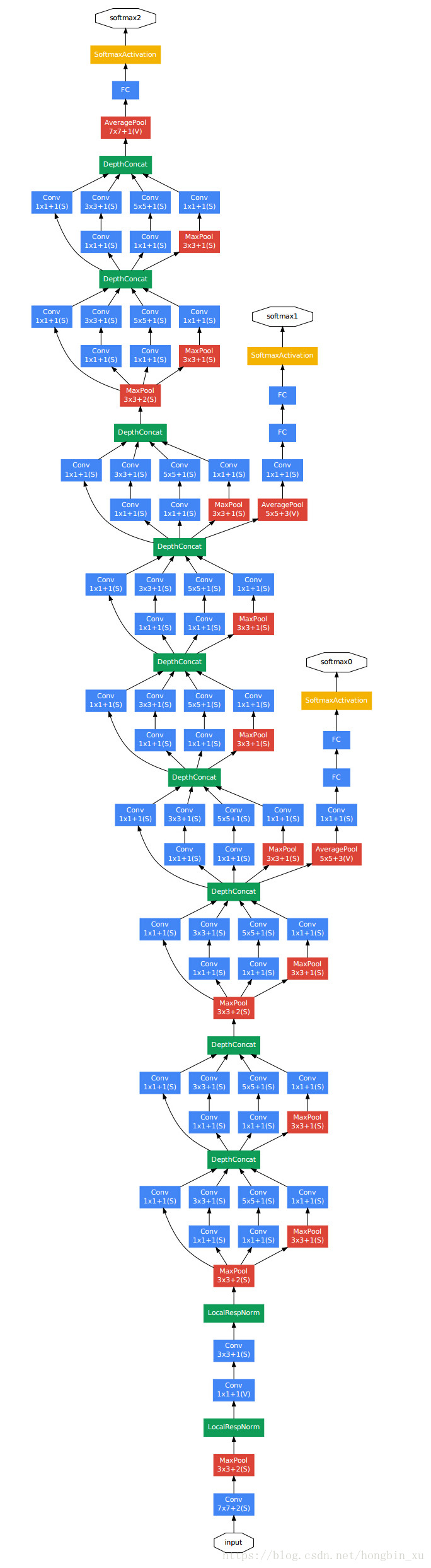
- GoogleNet结构说明:
- 采用Inception模块堆叠而成。
- 基于Network in Netw论文中的思想,在最后使用了average pooling来代替展开为全连接层的形式。实验也证明这样可以提高top-1准确率大概0.6%。
- 最后加的那个全连接层主要是为了便于大家将网络用于其他的数据集finetune。
- 网络中使用了dropout防止过拟合。
- 网络中还额外增加了两个辅助的softmax层。主要作用是,避免梯度消失,帮助梯度的传导。实际测试模型的时候,会将这两个softmax去除。