1. 论文思想
在其它条件都满足的(数据充足且足够好)的情况下,增加模型的尺寸以及计算量会带来实质上的优势,但是可供计算的资源总是有限的,特别是在移动设备上,并不能无节制的增加模型的尺寸。例如,在VggNet模型中使用的参数量是AlexNet参数量的三倍,实际取得的效果也是好于AlexNet的。在之前的Google-Net中采用了优化之后的Inception-V1结构以及去掉全连接层等方式使得模型的参数量为500W数据量,相比VggNet的6000W数量及的参数量,后者是前者的12倍。
2. 通用设计准则
这里给出基于大规模各式各样卷积网络实践的准则。这些准则是推测性质的,需要后期的实验去评估他们的精度以及可用的领域。在实际中偏移这些准则过多会导致网络恶化,而修正这些偏差通常会使得网络更优。
(1)避免网络表达瓶颈,特别是网络结构的前期。对于深度学习网络可以使用一个无环图进行表示,这就对网络中信息的流向做了明确的规定。通常来说从网络的输入端到最后的输出端网络的表达尺寸是缓慢减小的。
(2)更高维度的表示在网络中更容易局部处理。在卷积网络中增加每个图块的激活允许更多解耦的特征。所产生的网络将训练更快
(3)空间聚合可以通过更低维度的植入来实现,这个过程中不会损失过多或是不会损失表达的能力。例如,在使用大尺寸卷积的时候,将其输入维度减小,并不会对预期带来不利的影响。我们假设,如果在空间聚合上下文中使用输出,则相邻单元之间的强相关性会导致维度缩减期间的信息损失少得多。鉴于这些信号应该易于压缩,因此尺寸减小甚至会促进更快的学习。
(4)平衡网络的宽度与深度。网络的最佳性能体现是由每个阶段的滤波器组数量以及网络的深度取平衡得到的。同时增加网络的深度以及滤波器数量会使得网络性能提升。但是,在一定的计算量前提下亮着共同增加会使得网络达到最优提升。因而就需要在一定的计算量前提下在网络深度以及滤波器的数量上去的一个均衡值。
3. 大滤波器尺寸卷积的因式分解
GoogleNet的大量初始好处都是来自于降维,可以视为在卷积层上的因式分解,这时在计算效率层面的一中特殊案例。其在 的卷积核之后接 的卷积。在视觉任务中,我们希望激活层的邻近输出是高度相关的。因而,我们可以预期,他们在聚合之前被减少,这将导致局部表达具有相似性
3.1 因式分解到更小的卷积
大的卷积核(例如,
或是
)会带来不协调的计算开销。例如,
的卷积核是
大小卷积核参数的
倍。因而,使用
大小的卷积带来的计算量消耗是大于
的。且
大小的卷积核在模型前期的时候可以用来感受更大的视野,也是有其存在的价值与意义。针对这样的情况可以对其使用两个
大小的卷积核来代替,减少参数量。其运行示意图如下:
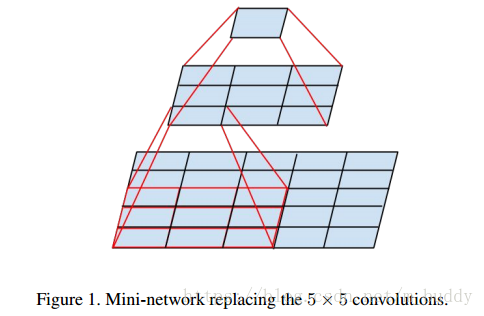
下图是原论文中采用的Inception结构:
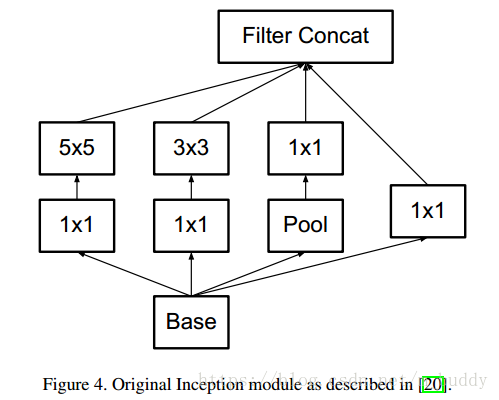
使用因式分解之后得到的结构:
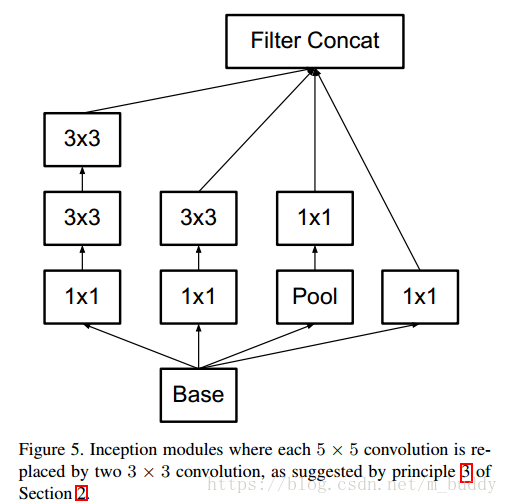
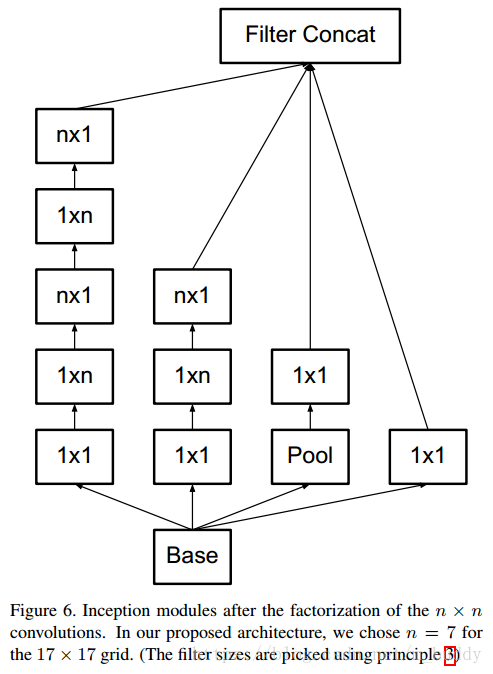
3.2 空间因式分解到部队称的卷积
在上面的内容中将大于
大小的可以因式分解为一系列
大小的卷积核。那么
大小的卷积核是否可以分解成为更小的卷积核连接呢?答案是肯定的,文章中使用
大小的卷积核作为替换,就如下图所示:
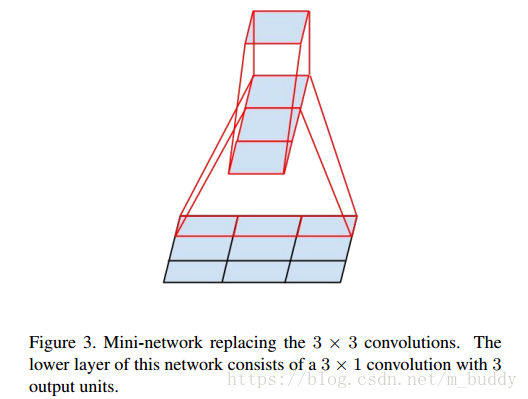
在上图中原本
大小的卷积可以通过级联
与
的卷积实现相同的感受视野。而且比原来的参数量节省了
的参数量。当然这种思路可以推广到任意的
的卷积核上去。如下图所示:
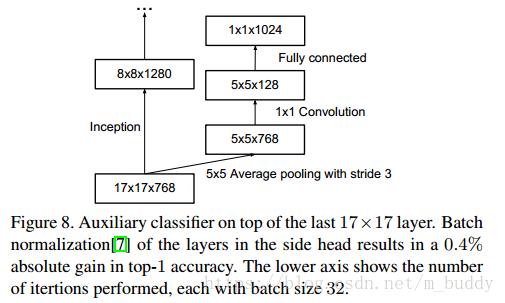
4. 附加损失函数使用
在之前的GoogleNet论文中提到添加附加损失函数会给网络带来附加的梯度信息,从而避免了梯度消失的问题。在论文中发现辅助损失函数并不能帮助网络尽早收敛,但是会使得网络获得更高一些的精确率。并认为附加损失函数的加入最网络加入了正则约束。
5. 有效的网格尺寸减少
传统上,卷积网络使用一些池化操作来缩减特征图的网格大小。为了避免表示瓶颈,在应用最大池化或平均池化之前,需要扩展网络滤波器的激活维度。例如,开始有一个带有
个滤波器的
网格,如果我们想要达到一个带有
个滤波器的
网格,我们首先需要用
个滤波器计算步长为1的卷积,然后应用一个额外的池化步骤。这意味着总体计算成本由在较大的网格上使用
次运算的昂贵卷积支配。一种可能性是转换为带有卷积的池化,因此导致
次运算,将计算成本降低为原来的四分之一。然而,由于表示的整体维度下降到
,会导致表示能力较弱的网络,这会产生一个表示瓶颈。见下图

上图中,减少网格尺寸的两种替代方式。左边的解决方案违反了第2节中不引入表示瓶颈的原则1。右边的版本计算量昂贵3倍
我们建议另一种变体,其甚至进一步降低了计算成本,同时消除了表示瓶颈(见下图),而不是这样做。我们可以使用两个平行的步长为2的块:PP和CC。PP是一个池化层(平均池化或最大池化)的激活,两者都是步长为2,其滤波器组连接下图所示。
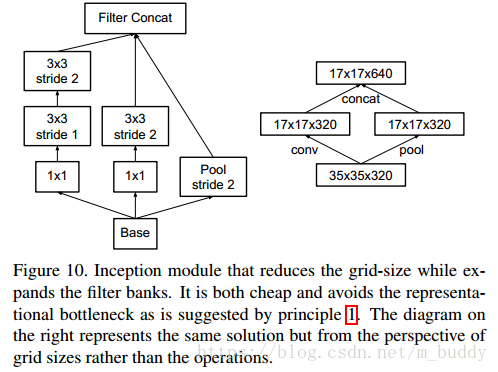
缩减网格尺寸的同时扩展滤波器组的Inception模块。它不仅廉价并且避免了原则1中提出的表示瓶颈。右侧的图表示相同的解决方案,但是从网格大小而不是运算的角度来看。