Paper列表:
[v1] Going Deeper with Convolutions, 6.67% test error, http://arxiv.org/abs/1409.4842
[v2] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, 4.8% test error, http://arxiv.org/abs/1502.03167
[v3] Rethinking the Inception Architecture for Computer Vision, 3.5% test error, http://arxiv.org/abs/1512.00567
[v4] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning, 3.08% test error, http://arxiv.org/abs/1602.07261
大体思路:
Inception v1(ILSVRC14):
1、传统的ConvNet是将Convulution layer stack在一起,而Inception最大的改变就是时Inception模块叠加的形式构造网络。按论文里面说就是,用Inception(稠密的可利用的组件)近似一个稀疏结构。
将1x1,3x3,5x5的conv和3x3的pooling,stack在一起,一方面增加了网络的width,另一方面增加了网络对尺度的适应性.
主要特点是提高了网络内部计算资源的利用率。
结构如下图:
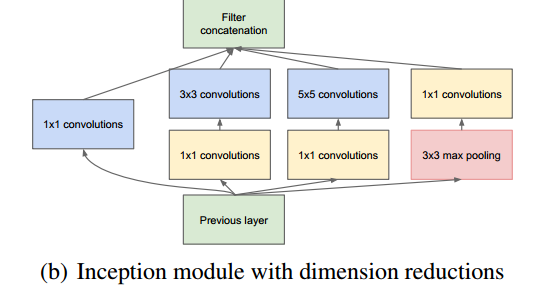
2、作者以Inception为基本构造块构造成了GoogLenet。GoogLenet有两个主要特点:
(1)在低层时候仍然用传统的方式,高层用Inception块叠加。(论文中说这可能反应了当前构造的不足)
(2)用Average pooling 替换传统的FC
(3)为了解决梯度弥散的问题,在4a 和4d的后面添加辅助loss,该loss仅在训练的时候以一定的weight参与梯度传递,而在test的时候不用。
网络结构:
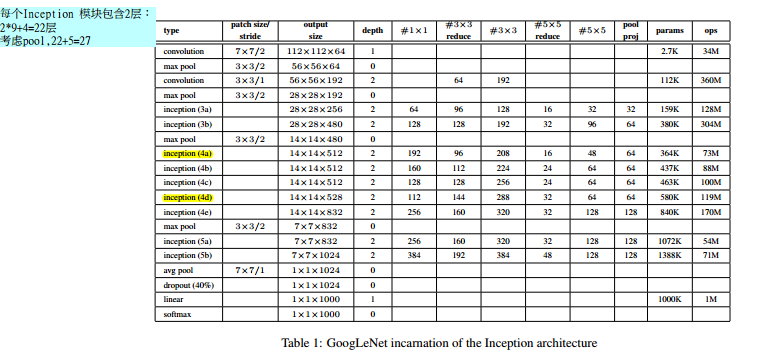
3、论文总结的或许导致实验效果好的一些因素
训练时
训练了7个模型,为了使问题更精细,一些模型在较小的crop上训练,一些模型则在大的crop上训练。
使模型训练较好的因素包括:
(1)图像各种尺寸patch的采样,这些patch 的size平均分布在图像区域的8%到100%间,长宽比例在3/4和4/3间。
(2)[8]的光照变化对于对抗过拟合有用。
(3)在后期使用随机差值进行图像的resize
测试时
1、训练7个相同的模型,其中包括一个较宽的版本,并且对结果进行集成。这些模型用相同的初始化和学习率测量,不同的是采样的方法不同和输入图像的顺序不同。
2、测试时更暴力的crop。
把图像resize成4个不同的尺度,使的短边分别是256,288,320和352.从这些resize后的图像中取左中右的方块。对每一个方块,取4个角落,中间的224*224crops,以及整个方块的224*224的resize,同时对这patch镜像。这样每个图像提取出的patch数是:4*3*6*2=224.
然而,似乎这种crop不是必须的。
3.softmax概率在多个crops和所有分类器上进行平均,获得最终的预测
paper1
Inception-v2:
第4个版本把这个版本称为Inception-v2,但是看到在作者的第三篇paper里面称这个版本为BN-inception.
在v1的基础上,进行了改进,一方面了加入了BN层,减少了Internal Covariate Shift(内部neuron的数据分布发生变化),使每一层的输出都规范化到一个N(0, 1)的高斯,另外一方面学习VGG用2个3x3的conv替代inception模块中的5x5,既降低了参数数量,也加速计算;
论文阅读:happynear 的博客
网络结构: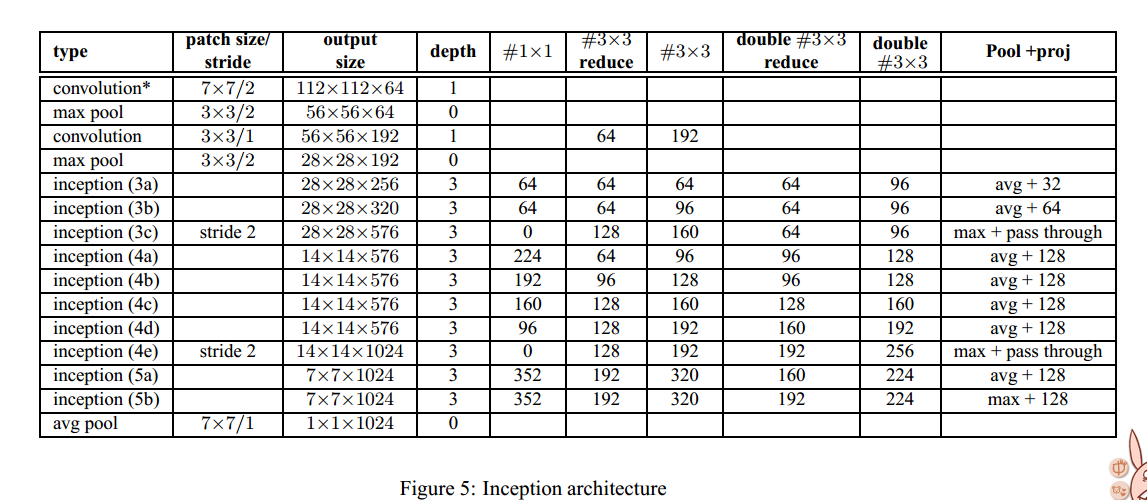
Figure 5 documents the changes that were performed compared to the architecture with respect to the GoogleNet archictecture. For the interpretation of this table, please consult (Szegedy et al., 2014). The notable architecture changes compared to the GoogLeNet model include:
• The 5×5 convolutional layers are replaced by two consecutive 3×3 convolutional layers. This increases the maximum depth of the network by 9 weight layers. Also it increases the number of parameters by 25% and the computational cost is increased by about 30%.
• The number 28×28 inception modules is increased from 2 to 3.
• Inside the modules, sometimes average, sometimes maximum-pooling is employed. This is indicated in the entries crresponding to the pooling layers of the table.
• There are no across the board pooling layers between any two Inception modules, but stride-2 convolution/pooling layers are employed before the filter concatenation in the modules 3c, 4e.
Our model employed separable convolution with depth multiplier 8 on the first convolutional layer. This reduces the computational cost while increasing the memory consumption at training time.(不明白)
Inception-v3:
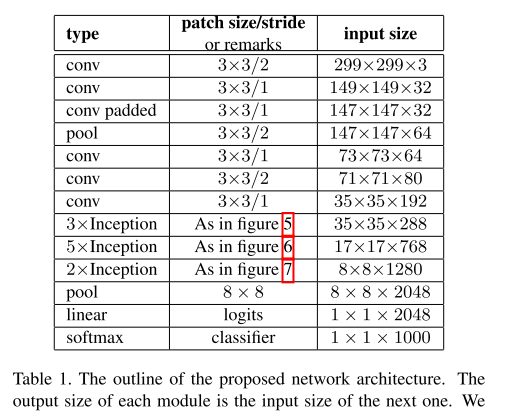
(1)7*7的卷积层替换成了3个3*3的卷积
(2)第一块Inception变成了3个(同BN-Inception)
(3)第一块Inception是传统的
第二块Inception是 Fig.5. 5*5替换成两个3*3
第三块Inception是Fig.6. 1*n 和n*1
v3一个最重要的改进是分解(Factorization),将7x7分解成两个一维的卷积(1x7,7x1),3x3也是一样(1x3,3x1),这第一个样的好处,既可以加速计算(多余的计算能力可以用来加深网络),又可以将1个conv拆成2个conv,使得网络深度进一步增加,增加了网络的非线性,还有值得注意的地方是网络输入从224x224变为了299x299,更加精细设计了35x35/17x17/8x8的模块;
具体来讲:
训练的技巧增加了:
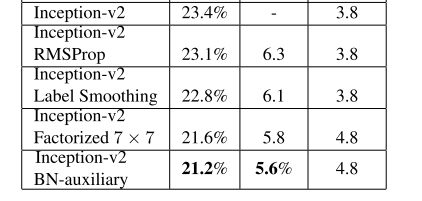
上图增加的内容是累加的,最后一个就是Inception v3.
(1)RMSProp: 一种参数优化的方式
在caffe中,solver里面定义:
solver_type:RMSProp
关于solver_type,caffe一共提供六种:
Stochastic Gradient Descent (type: “SGD”),
AdaDelta (type: “AdaDelta”),
Adaptive Gradient (type: “AdaGrad”),
Adam (type: “Adam”),
Nesterov’s Accelerated Gradient (type: “Nesterov”) and
RMSprop (type: “RMSProp”)
详见:
http://www.cnblogs.com/denny402/p/5074212.html
(2)label smoothing
(3)Factorized 7*7
把第一个7*7的卷积层替换成了3个3*3的卷积(可是,前面定义的Inception-v2里面已经有了。。。。)
(4)BN-auxiliary:在辅助层的全连接层后面也进行BN操作。
Inception-v4 Inception-ResNet v1 Inception-ResNet v2:
研究了Inception模块结合Residual Connection能不能有改进?发现ResNet的结构可以极大地加速训练,同时性能也有提升,得到一个Inception-ResNet v2网络,同时还设计了一个更深更优化的Inception v4模型,能达到与Inception-ResNet v2相媲美的性能。
Paper列表:
[v1] Going Deeper with Convolutions, 6.67% test error, http://arxiv.org/abs/1409.4842
[v2] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, 4.8% test error, http://arxiv.org/abs/1502.03167
[v3] Rethinking the Inception Architecture for Computer Vision, 3.5% test error, http://arxiv.org/abs/1512.00567
[v4] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning, 3.08% test error, http://arxiv.org/abs/1602.07261
大体思路:
Inception v1(ILSVRC14):
1、传统的ConvNet是将Convulution layer stack在一起,而Inception最大的改变就是时Inception模块叠加的形式构造网络。按论文里面说就是,用Inception(稠密的可利用的组件)近似一个稀疏结构。
将1x1,3x3,5x5的conv和3x3的pooling,stack在一起,一方面增加了网络的width,另一方面增加了网络对尺度的适应性.
主要特点是提高了网络内部计算资源的利用率。
结构如下图:
2、作者以Inception为基本构造块构造成了GoogLenet。GoogLenet有两个主要特点:
(1)在低层时候仍然用传统的方式,高层用Inception块叠加。(论文中说这可能反应了当前构造的不足)
(2)用Average pooling 替换传统的FC
(3)为了解决梯度弥散的问题,在4a 和4d的后面添加辅助loss,该loss仅在训练的时候以一定的weight参与梯度传递,而在test的时候不用。
网络结构:
3、论文总结的或许导致实验效果好的一些因素
训练时
训练了7个模型,为了使问题更精细,一些模型在较小的crop上训练,一些模型则在大的crop上训练。
使模型训练较好的因素包括:
(1)图像各种尺寸patch的采样,这些patch 的size平均分布在图像区域的8%到100%间,长宽比例在3/4和4/3间。
(2)[8]的光照变化对于对抗过拟合有用。
(3)在后期使用随机差值进行图像的resize
测试时
1、训练7个相同的模型,其中包括一个较宽的版本,并且对结果进行集成。这些模型用相同的初始化和学习率测量,不同的是采样的方法不同和输入图像的顺序不同。
2、测试时更暴力的crop。
把图像resize成4个不同的尺度,使的短边分别是256,288,320和352.从这些resize后的图像中取左中右的方块。对每一个方块,取4个角落,中间的224*224crops,以及整个方块的224*224的resize,同时对这patch镜像。这样每个图像提取出的patch数是:4*3*6*2=224.
然而,似乎这种crop不是必须的。
3.softmax概率在多个crops和所有分类器上进行平均,获得最终的预测
paper1
Inception-v2:
第4个版本把这个版本称为Inception-v2,但是看到在作者的第三篇paper里面称这个版本为BN-inception.
在v1的基础上,进行了改进,一方面了加入了BN层,减少了Internal Covariate Shift(内部neuron的数据分布发生变化),使每一层的输出都规范化到一个N(0, 1)的高斯,另外一方面学习VGG用2个3x3的conv替代inception模块中的5x5,既降低了参数数量,也加速计算;
论文阅读:happynear 的博客
网络结构:
Figure 5 documents the changes that were performed compared to the architecture with respect to the GoogleNet archictecture. For the interpretation of this table, please consult (Szegedy et al., 2014). The notable architecture changes compared to the GoogLeNet model include:
• The 5×5 convolutional layers are replaced by two consecutive 3×3 convolutional layers. This increases the maximum depth of the network by 9 weight layers. Also it increases the number of parameters by 25% and the computational cost is increased by about 30%.
• The number 28×28 inception modules is increased from 2 to 3.
• Inside the modules, sometimes average, sometimes maximum-pooling is employed. This is indicated in the entries crresponding to the pooling layers of the table.
• There are no across the board pooling layers between any two Inception modules, but stride-2 convolution/pooling layers are employed before the filter concatenation in the modules 3c, 4e.
Our model employed separable convolution with depth multiplier 8 on the first convolutional layer. This reduces the computational cost while increasing the memory consumption at training time.(不明白)
Inception-v3:
(1)7*7的卷积层替换成了3个3*3的卷积
(2)第一块Inception变成了3个(同BN-Inception)
(3)第一块Inception是传统的
第二块Inception是 Fig.5. 5*5替换成两个3*3
第三块Inception是Fig.6. 1*n 和n*1
v3一个最重要的改进是分解(Factorization),将7x7分解成两个一维的卷积(1x7,7x1),3x3也是一样(1x3,3x1),这第一个样的好处,既可以加速计算(多余的计算能力可以用来加深网络),又可以将1个conv拆成2个conv,使得网络深度进一步增加,增加了网络的非线性,还有值得注意的地方是网络输入从224x224变为了299x299,更加精细设计了35x35/17x17/8x8的模块;
具体来讲:
训练的技巧增加了:
上图增加的内容是累加的,最后一个就是Inception v3.
(1)RMSProp: 一种参数优化的方式
在caffe中,solver里面定义:
solver_type:RMSProp
关于solver_type,caffe一共提供六种:
Stochastic Gradient Descent (type: “SGD”),
AdaDelta (type: “AdaDelta”),
Adaptive Gradient (type: “AdaGrad”),
Adam (type: “Adam”),
Nesterov’s Accelerated Gradient (type: “Nesterov”) and
RMSprop (type: “RMSProp”)
详见:
http://www.cnblogs.com/denny402/p/5074212.html
(2)label smoothing
(3)Factorized 7*7
把第一个7*7的卷积层替换成了3个3*3的卷积(可是,前面定义的Inception-v2里面已经有了。。。。)
(4)BN-auxiliary:在辅助层的全连接层后面也进行BN操作。
Inception-v4 Inception-ResNet v1 Inception-ResNet v2:
研究了Inception模块结合Residual Connection能不能有改进?发现ResNet的结构可以极大地加速训练,同时性能也有提升,得到一个Inception-ResNet v2网络,同时还设计了一个更深更优化的Inception v4模型,能达到与Inception-ResNet v2相媲美的性能。