本文是对 “Going Deeper With Convolution” 的论文创新点的解读和总结,笔者在去年对该论文进行了全文翻译,原文翻译可点传送门:《Going Deeper With Convolution》全文译解,但当时仅限于翻译,并未对其中细节和创新点进行详细剖析。经典的东西需要细细品味,本文主要解读该论文的新点,也即 GoogLeNet 的网络结构。
该论文发表于 CVPR 2015,由谷歌等单位提出,自2015年发表至今,已有接近1万的引用量,实为经典。GoogLeNet 在 ILSVRC 2014 上刷新了图像分类与检测的性能记录。通过合理地设计网路层次和每层的神经参数,在保持网络资源不变的前提下,通过人为手段增加了网络的宽度和深度。
注:博文中图表均来自论文原文
1. 网络结构
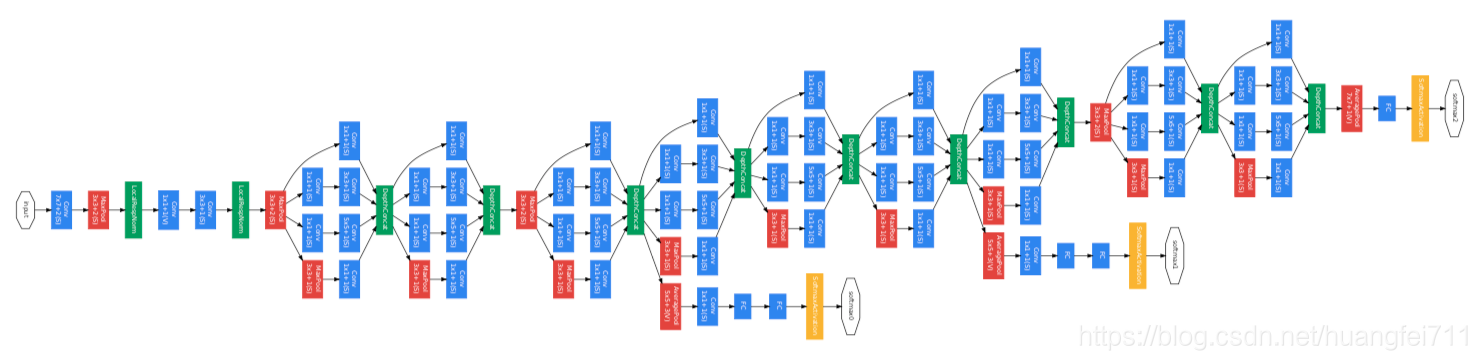
1.1 Inception module
GoogLeNet 用的参数比 AlexNet 少12倍,但准确率更高,Inception module 的使用无疑是网络性能提升的最主要因素。相对于传统的 VGGNet,单层卷积核的大小只有[3,3],在特征提取的时候功能较弱;而 Inception module 则是由[1,1]、[3,3]、[5,5]卷积核和一个[3,3]的 pooling 组成,如下图所示:
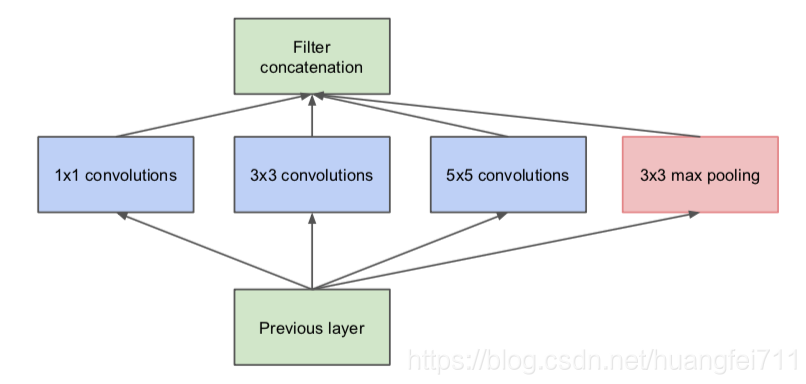
这样通过不同的卷积核就可以抽取不同尺寸的特征,大大增强了对传递数据的特征抽取。因为使用特征抽取时,传统的方式是在提取结束后使用池化层进行特征的进一步提取,必然会带来一层层的特征损失;而 Inception module 采用的是并行的模式,这样就在一定程度上对特征进行分拣,保留了更多的数据特征信息。
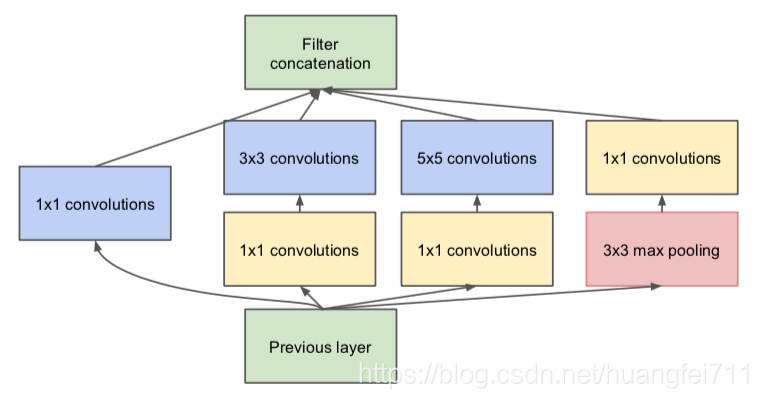
虽然采用这样的方式能够较传统的特征提取单元保留更多的信息,但是一个非常大的问题就是特征保留过多,在模型传递的过程中会耗费巨大的计算资源。即使使用[5,5]的卷积核进行抽样,一样会带来繁重的资源需求。因此为了解决这个问题,在原始的 Inception module 上采用了多个[1,1]大小的卷积核进行数据的降维,这样既可以减少信息损失,有减少了传递的卷积计算量。
这样修改后,可以使得 Inception module 获得较好的卷积提取能力,而不会随着深度的增加而提升很多的计算量。修改后的 Inception module 模型如下图所示:
1.2 两个辅助分类器
为了避免梯度消失,网络额外增加了2个辅助的 softmax 用于向前传导梯度。文章中说这两个辅助的分类器的 loss 应该加一个衰减系数,但看 caffe 中的 model 也没有加任何衰减。此外,实际测试的时候,这两个额外的 softmax 会被去掉。
