Inception v1 / GoogLeNet:Going Deeper with Convolutions
摘要:我们提出了一个名为Inception的深度卷积神经网络架构,它是ILSVRC 2014的冠军。Inception的最大特点是:通过精心设计,使得网络在计算量不变的前提下,深度和宽度得到了增加,从而提高了深度网络对于计算资源的利用。Inception的网络架构基于Hebbian原则和多尺度处理直觉设计的,这优化了Inceotion的架构。ILSVRC 2014中我们提交的22层深的GooLeNet是本研究的一个特例(参加了当年的分类和探测比赛)。
关键点:Inception module,辅助分类器
文章总结:
1.设计了Inception模块,用dense结构去近似sparse结构。
2.Inception内部1x1,3x3,5x5,pooling,一方面增加了网络宽度,另一方面增强了模型对尺度的适应性。
3.大量使用了1x1卷积,降低了模型的计算量。
4.低层仍使用传统卷积,高层使用Inception
5.用辅助分类器解决梯度传播问题
1.介绍
分类准确率和物体探测准确度的提高,不仅仅源于硬件提高、更大数据集和更大模型,而且来自于新思想、算法和网络架构。GoogLeNet使用的参数量是AlexNet的十二分之一的情况下,将准确率提高了许多。在探测任务中,性能提升主要来自于深度结构和经典的计算机视觉的结合,比如R-CNN算法。
另一个十分重要的因素是移动和嵌入式设备的发展,模型的内存使用量和计算量变得很关键。所以Inception架构在追求准确率的同时,保持模型inference时的计算量在1.5 billion次multiply-adds。所以Inceotion的提出不仅仅是为了准确率,同时也是为了实际应用。
Inception这个名字的灵感来自NIN和[we need to go deeper][3]这句话。本文中的deep的含义主要是两个方面:发明了Inception模块;增加了网络的深度。一般来说,Inception模块可以被看作12的一个合乎逻辑的实现,这其中灵感和指导思想主要来自于Arora et al的理论工作。
2. 相关工作
自从LeNet-5开始,卷积神经网络(CNN)有了一个典型的标准结构:堆叠卷积层(可选follow contrast normalization和max pool),然后跟一层或多层FC。基础结构的各种变种在图像分类任务中很流行,并且在MNIST、CIFAR和ImageNet分类比赛上取得了state of art。当前对于更大的数据集,当前的趋势是增加模型的深度和宽度,同时使用dropout来克服overfitting问题。
尽管注意到max-pooling导致准确的空间信息的丢失,但是AlexNet类似的网络也成功应用到了定位,物体识别,人的姿势估计任务上。受最近Serre等人在视觉皮层上的神经科学模型的启发(使用一系列不同大小的固定Gabor filter去处理多尺度),我们设计了Inception模块。更近一步,Inception层重复很多次,从而产生了一个22层深的模型(GoogLeNet)。
NIN网络是Lin等人提出的一种增加神经网络表示能力的一种方法。当NIN应用到卷积层之后,该方法可以被看成1x1卷积层followed ReLU,这使得它很容易集成到当前的CNN piplines中,在我们的网络中,大量使用了1x1卷积。但是,在我们的网络中,1x1卷积有两个目的:最重要的是,它作为一个降维模块去,可以降低计算量。这允许我们可以增加深度和宽度,却不降低网络的性能。
当前最好的物体探测方法是Regions with Convolutional Neural Networks(R-CNN)。R-CNN分解overall物体探测任务为两部分:去首先利用低层的线索(颜色,超像素的一致性)生成物体潜在的区域(不考虑类别),然后使用CNN分类器去识别这些区域的物体的种类。这种两步方法充分利用了:低层信息进行bounding box分割的准确度,和state of art模型的强大分类能力。在探测任务中,我们采用了一个相似的pipline,但是在两个步骤都有了提高,例如:multi-box prediction for higher object bounding box recall, and ensemble approach for better categorization of bounding box proposals。
3. 动机和更高层的考虑(Motivation and High Level Considerations)
最直接的提高深度神经网络的性能的方法是增加它的size。这包括增加深度(the number of levels)和宽度(the number of units at each level)。这是一个训练更高质量模型的容易且安全的方法,尤其是在有大量带标签的训练数据的情况下。但这个简单的解决方案带来了两个主要问题。
更大size一般意味着大量的参数,这使得加大后的网络更容易过拟合,尤其是带标签数据比较少的情况下。这很难,因为高质量的大数据集的制作需要技巧,并且费用很高。尤其是当expert human raters需要去分辨细微差别的种类。
均匀增加网络size(所有层都增大size)的另一个缺点是计算量的剧增。例如一个两层的卷积网络,均匀增加两层的filters的数量会导致计算量立方级的增长。所以计算量的高效分布是很有必要的。
解决这两个问题的最基本方法是将FC转为sparsely connected架构(即使在卷积网络中)。除了模拟生物系统,这也利用了Arora等人开创性的坚实的理论基础的优势。他们的结果说明
若果一个数据集的概率分布能够被一个大的稀疏的深度神经网络表示,那么最优网络的拓扑能够被一层一层的构建by分析最后一层activations的相关性的统计和聚类输出高度相关的神经元。尽管没有进行严格的数学推导,但是这一描述和著名的Hebbian准测是类似的:激活的神经元连接在一起,抑制的神经元连在一起。
退一步(on the downside),今天的计算硬件是非常不高效的,当涉及到非均匀的稀疏数据结构的计算时。当前的视觉方面的机器学习系统在空间域上一用稀疏性by卷积。但是卷积可以看成一系列的局部FC。所以稀疏矩阵应该被聚类,转为密集矩阵。所以,可将类似的方法应用到non-uniform deep architectures的自动构建。
在假设输出的最优网络拓扑构建算法中去尝试用可理解的dense结构来代替稀疏结构的过程中,第一作者提出了Inception架构。在两次尝试后,作者便看到了明显的性能改善(有点运气)。在微调学习速率,超参数和改进训练策略之后,得到了现在的Inception架构。
一个需要注意的地方是:尽管Inception架构在视觉上取得了成功,但它值得思考,性能提升是否来真的自于设计时的指导思想。虽然Inception架构取得了成功,但是自动构建系统仍值得进一步研究。
4.架构信息
Inception架构的理念基于寻找怎么用可理解、可用的dense架构近似最优局部稀疏结构。1x1卷积用于将稀疏转为密集。1x1,3x3,5x5的大小是为了方便对齐而不是必须。池化在现在的各种模型中很重要,所以加了池化。
下面是Inception模块的图:
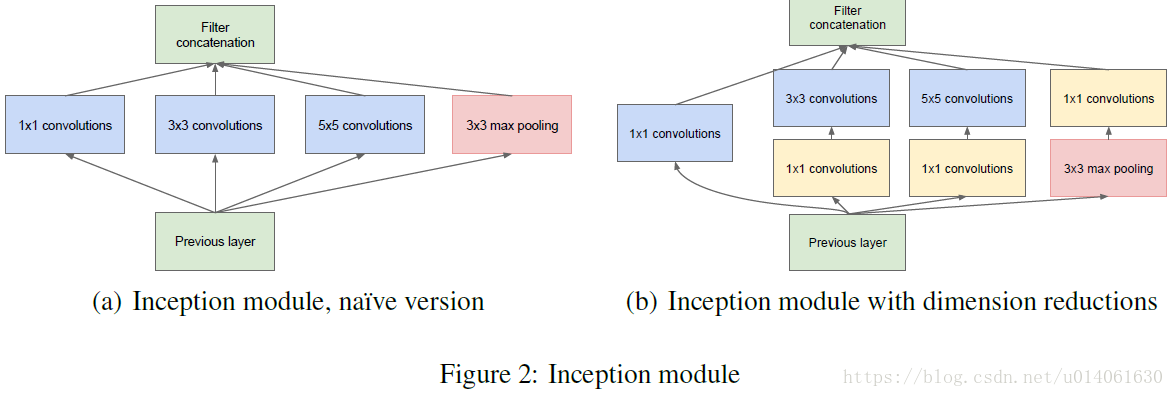
上面的架构(至少naive版本)有一个很大的问题:即使5x5卷积的计算量很大(当前层有很多channel时)。这个问题随着max-pooling的加入,变得更明显。所以作者在b中加了1x1卷积,减少计算量。
由于训练时的内存efficiency,所以只在高层使用Inception模块,低层仍然使用传统的卷积配置。
这个架构的 最主要特点是,在计算量不显著变化的情况下,它允许增加网络宽度(这主要归功于1x1卷积)。另一个特点是,它将多尺度考虑了进去。
Inception架构对于计算资源的高效利用允许增加网络尺寸(深度、宽度),同时几乎不增加计算量。并且Inception的推理速度很快。
5.GoogLeNet
作者在ILSVRC2014提交的模型是GoogLeNet。这个名字是为了纪念LeNet-5。作者也训练了更深更宽的网络,但性能稍差,把该模型和最好的进行了集成,以提高准确率。
GoogLeNet的网络配置:
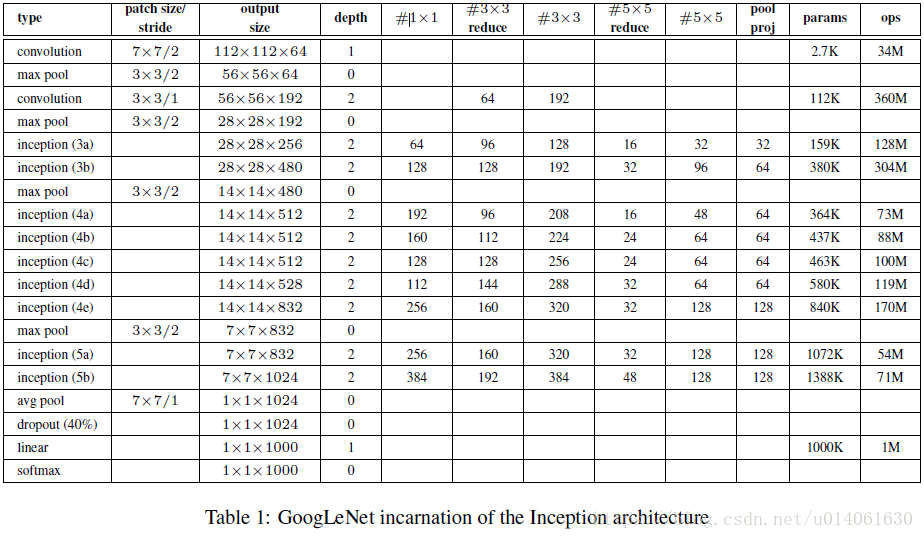
GoogLeNet共22层(计算pool层,总计27层)
下面是GoogLeNet的架构图:
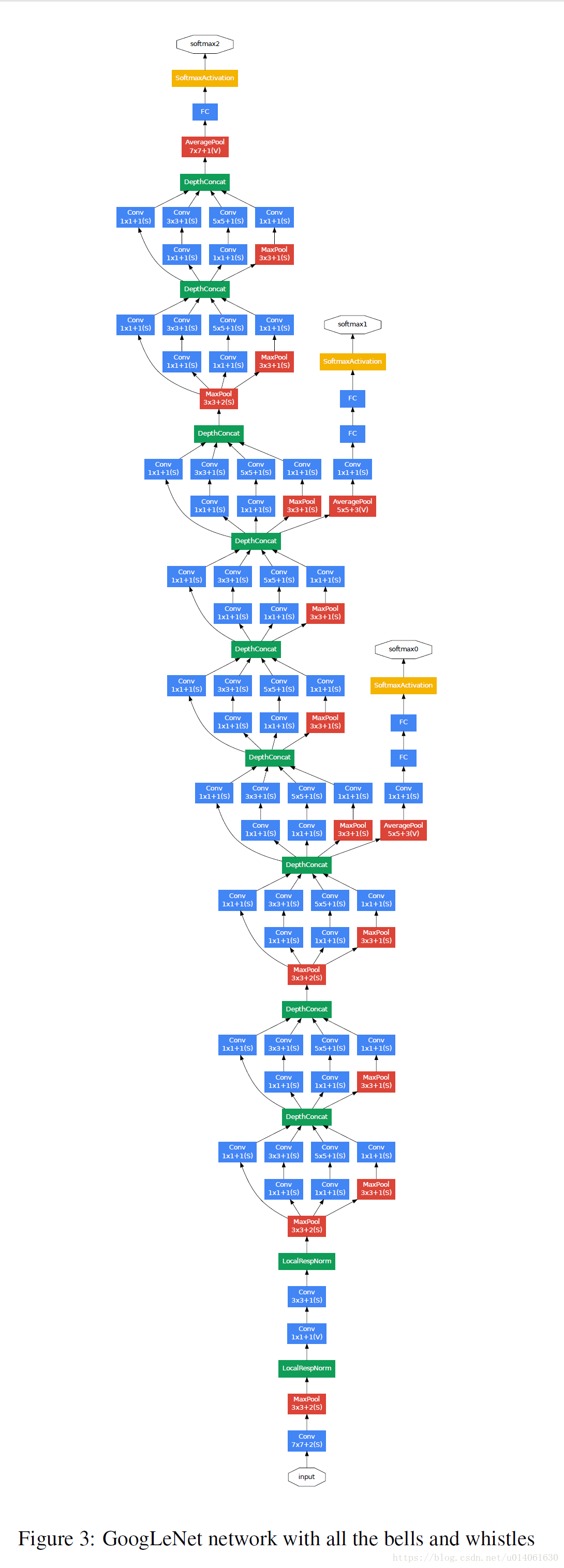
网络这么深,梯度怎么合理的反向传播,作者给网络额外增加了两个分类器(Inception 4a和4d输出)。训练时,将额外的两个分类器的loss乘以0.3加到最后的cost上,inference时,去除额外的分类器。(增加额外的分类器就是为了解决梯度反向传播的问题)
两个额外分类器的配置如下:
A average pooling with 5x5 filter size and stride 3. resulting in an 4x4x512 output for the (4a), and 4x4x528 for the (4d) stage.
A 1x1 conv with 128 filters and ReLU
A FC with 1024 units and ReLU
A dropoout layer with 70% ratio of dropped outputs
A linear layer with softmax as classifier (predicting the same 1000 classes as the main classifier, but removed at inference time)
6.训练策略
训练使用的是TensorFlow的前身DistBelief。硬件使用的是CPU。优化算法使用的是异步梯度下降with 0.9 momentum。学习速率设定每8 epoch下降4%。Polyak averaging被使用去创建inference的模型。
训练了7个模型,为了使问题更精细,一些模型在较小的crop上训练,一些模型则在大的crop上训练。
使模型训练较好的因素包括:
1.图像各种尺寸patch的采样,这些patch 的size平均分布在图像区域的8%到100%间,长宽比例在3/4和4/3间。
2.另外Andrew Howard的photometric distortions对于克服过拟合很有用。
3.resize时内插方法随机使用bilinear, area, nearest neighbor and cubic, with equal probability。
测试时
1、训练7个相同的模型,其中包括一个较宽的版本,并且对结果进行集成。这些模型用相同的初始化和学习率测量,不同的是采样的方法不同和输入图像的顺序不同。
2、测试时更暴力的crop。
把图像resize成4个不同的尺度,使的短边分别是256,288,320和352.从这些resize后的图像中取左中右的方块。对每一个方块,取4个角落,中间的224*224crops,以及整个方块的224*224的resize,同时对这patch镜像。这样每个图像提取出的patch数是:4*3*6*2=224.
然而,似乎这种crop不是必须的。
3.softmax概率在多个crops和所有分类器上进行平均,获得最终的预测
下面给出TensorFlow实现的GoogLeNet
首先给出Inception module的代码:
#coding:utf-8
#inception_modules.py
'''
Inception module
'''
import tensorflow as tf
relu = tf.nn.relu
def inception_naive(inputs,
sub_chs,
scope='inception_naive'):
'''
sub_chs: sub channels
'''
[sub_ch1,sub_ch2,sub_ch3] = sub_chs
with tf.variable_scope(scope):
x = inputs
sub1 = tf.layers.Conv2D(sub_ch1, [1,1], padding='SAME', activation=relu)(x)
sub2 = tf.layers.Conv2D(sub_ch2, [3,3], padding='SAME', activation=relu)(x)
sub3 = tf.layers.Conv2D(sub_ch3, [5,5], padding='SAME', activation=relu)(x)
sub4 = tf.layers.MaxPooling2D([3,3], 1, padding='SAME')(x)
x = tf.concat([sub1,sub2,sub3,sub4], axis=-1)
return x
def inception(inputs,
sub_chs,
scope='inception'):
'''
sub_chs: sub channels
'''
[sub_ch1, sub_ch2, sub_ch3, sub_ch4] = sub_chs
with tf.variable_scope(scope):
x = inputs
sub1 = tf.layers.Conv2D(sub_ch1, [1,1], padding='SAME', activation=relu)(x)
_sub2 = tf.layers.Conv2D(sub_ch2[0], [1,1], padding='SAME', activation=relu)(x)
sub2 = tf.layers.Conv2D(sub_ch2[1], [3,3], padding='SAME', activation=relu)(_sub2)
_sub3 = tf.layers.Conv2D(sub_ch3[0], [1,1], padding='SAME', activation=relu)(x)
sub3 = tf.layers.Conv2D(sub_ch3[1], [5,5], padding='SAME', activation=relu)(_sub3)
_sub4 = tf.layers.MaxPooling2D([3,3], 1, padding='SAME')(x)
sub4 = tf.layers.Conv2D(sub_ch4, [1,1], padding='SAME', activation=relu)(_sub4)
x = tf.concat([sub1,sub2,sub3,sub4], axis=-1)
return x
if __name__ == '__main__':
x = tf.placeholder(tf.float32, [192, 28, 28, 3])
y = inception_naive(x, [64, 128, 32])
assert y.get_shape().as_list()==[192,28,28,227]
print('inception_naive is ok')
y1 = inception(x, [64, [96,128], [16,32], 32])
assert y1.get_shape().as_list()==[192,28,28,256]
print('inception is ok')下面给出GoogLeNet的实现:
#coding:utf-8
'''
Inception v1
'''
import tensorflow as tf
relu = tf.nn.relu
import inception_modules as modules
def print_activation(x):
print(x.op.name, x.get_shape().as_list())
def inference(inputs,
num_classes=10,
is_training=True,
dropout_rate=0.4):
'''
inputs: a tensor of images
num_classes: the num of category.
is_training: set ture when it used for training
dropout_prob: the rate of dropout during training
'''
caches = []
x = inputs
print_activation(x)
# conv1
x = tf.layers.Conv2D(64, [7,7], 2, activation=relu, padding='SAME', name='conv1')(x)
print_activation(x)
# pool1
x = tf.layers.MaxPooling2D([3,3], 2, padding='SAME', name='pool1')(x)
print_activation(x)
# lrn1
x = tf.nn.local_response_normalization(x, name='lrn1')
print_activation(x)
# conv2
x = tf.layers.Conv2D(64, [1,1], 1, activation=relu, padding='SAME', name='conv2')(x)
print_activation(x)
# conv3
x = tf.layers.Conv2D(192, [3,3], 1, activation=relu, padding='SAME', name='conv3')(x)
print_activation(x)
# lrn2
x = tf.nn.local_response_normalization(x, name='lrn2')
print_activation(x)
# pool3
x = tf.layers.MaxPooling2D([3,3], 2, padding='SAME', name='pool3')(x)
print_activation(x)
with tf.variable_scope('inception3'):
# inception_3a
x = modules.inception(x, [64, [96,128], [16,32], 32], scope='inception_3a')
print_activation(x)
# inception_3b
x = modules.inception(x, [128, [128,192], [32,96], 64], scope='inception_3b')
print_activation(x)
# pool4
x = tf.layers.MaxPooling2D([3,3], 2, padding='SAME', name='pool4')(x)
print_activation(x)
with tf.variable_scope('inception4'):
# inception_4a
x = modules.inception(x, [192, [96,208], [16,48], 64], scope='inception_4a')
caches.append(x)
print_activation(x)
# inception_4b
x = modules.inception(x, [160, [112,224], [24,64], 64], scope='inception_4b')
print_activation(x)
# inception_4c
x = modules.inception(x, [128, [128,256], [24,64], 64], scope='inception_4c')
print_activation(x)
# inception_4d
x = modules.inception(x, [112, [144,288], [32,64], 64], scope='inception_4d')
print_activation(x)
caches.append(x)
# inception_4e
x = modules.inception(x, [256, [160,320], [32,128], 128], scope='inception_4e')
print_activation(x)
# pool5
x = tf.layers.MaxPooling2D([3,3], 2, padding='SAME', name='pool5')(x)
print_activation(x)
with tf.variable_scope('inception5'):
# inception_5a
x = modules.inception(x, [256, [160,320], [32,128], 128], scope='inception_5a')
print_activation(x)
# inception_5b
x = modules.inception(x, [384, [192,384], [48,128], 128], scope='inception_5b')
print_activation(x)
# avg_pool
_ksize = x.get_shape().as_list()[1]
x = tf.layers.AveragePooling2D([_ksize,_ksize], 1, name='avg_pool')(x)
print_activation(x)
# dropout
x = tf.layers.Dropout(dropout_rate, name='dropout')(x)
print_activation(x)
# linear+softmax
logits = tf.layers.Conv2D(num_classes, [1,1], 1,
activation=tf.nn.softmax, name='linear-softmax')(x)
print_activation(logits)
return logits, caches
def build_cost(logits, labels, scope='costs'):
with tf.variable_scope(scope):
cost = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits=logits, labels=labels), name='xent')
return cost
def build_sub_cost(cache, labels, scope='sub_costs'):
num_classes = labels.get_shape().as_list()[-1]
with tf.variable_scope(scope):
x = cache
x = tf.layers.AveragePooling2D([5,5], 3, name='avg_pool')(x)
x = tf.layers.Conv2D(128, [1,1], 1, activation=relu, name='conv')(x)
_ksize = x.get_shape().as_list()[1]
x = tf.layers.Conv2D(1024, [_ksize,_ksize], 1, activation=relu, name='fc')(x)
x = tf.layers.Dropout(0.7)(x)
logits = tf.layers.Conv2D(num_classes, [1,1], 1, activation=tf.nn.softmax, name='fc-softmax')(x)
cost = build_cost(tf.layers.flatten(logits), labels)
return cost
def build_train_op(cost, lrn_rate=0.001, scope='train'):
with tf.variable_scope(scope):
train_op = tf.train.AdamOptimizer(lrn_rate).minimize(cost)
return train_op
if __name__ == '__main__':
mode = 'train'
with tf.variable_scope('inputs'):
images = tf.placeholder(tf.float32, [None,224,224,3])
labels = tf.placeholder(tf.float32, [None, 1000])
logits, caches = inference(inputs=images, num_classes=1000)
logits = tf.layers.flatten(logits)
print('inference is ok!')
if mode=='train':
with tf.variable_scope('costs'):
cost = tf.add_n([build_cost(logits, labels),
build_sub_cost(caches[0], labels, scope='sub_cost1')*0.3,
build_sub_cost(caches[1], labels, scope='sub_cost2')*0.3])
else:
cost = build_cost(logits, labels)
print('build_cost is ok!')
train_op = build_train_op(cost, lrn_rate=0.001)
print('build_train_op is ok!')
sess = tf.Session()
tf.summary.FileWriter('./',sess.graph)注意:使用本博客的代码,请添加引用
[3]: We Need to Go Deeper:The world of We Need to go Deeper was heavily inspired by the works of Jules Verne, with 20,000 Leagues Under the Sea in particular being a heavy influence on our game’s universe. What would it be like to be a crew member aboard the Nautilus? To be exploring the deep, facing the wrath of a giant squid one moment, and uncovering the lost city of Atlantis the next?