版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/hongbin_xu/article/details/84304135
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
ShuffleNet v1
1、四个问题
- 要解决什么问题?
- 为算力有限的嵌入式场景下专门设计一个高效的神经网络架构。
- 用了什么方法解决?
- 使用了两个新的操作:pointwise group convolution(组卷积)和channel shuffle。
- 根据这两个操作构建了ShuffleUnit,整个ShuffleNet都是由ShuffleUnit组成。
- 效果如何?
- 在ImageNet分类和MS COCO目标检测任务上取得了比其他轻量化模型更高的准确率,如MobileNet v1。
- 在ARM设备上,ShuffleNet的速度比AlexNet快了13倍。
- 还存在什么问题?
- 超参数如组卷积的组数以及通道压缩比率等需要根据实际情况决定,不同任务下需要自行调整。
- 网络实时性并不能单纯以浮点计算量来衡量,还存在memory access cost(MAC)等因素的干扰,并不能仅仅根据计算量就认为ShuffleNet是最快的。
2、论文概述
2.1、简介
- 作者发现,一些state-of-the-art的模型架构,如Xception、ResNeXt等,使用在小型网络模型中效率都比较低。这是因为使用大量的 卷积会消耗大量计算资源。为此,提出了pointwise group convolution来减少计算复杂度。
- 使用组卷积也会带来一些副作用,因为组卷积切断了组内通道与组外通道之间的联系,仅仅能从组内通道提取特征信息。为此,论文中又提出了 channel shuffle,来帮助信息在各通道之间流通。
2.2、相关工作
- 高效模型设计:
- GoogLeNet
- SqueezeNet
- ResNet
- SENet
- NASNet
- 组卷积(group convolution):
- 最初由AlexNet提出,应用在2块GPU上并行处理。
- Xception中提出了深度可分离卷积(depthwise separable convolution)。
- MobileNet中也使用到了深度可分离卷积。
- Channel Shuffle
- 此前的文献中较少提及channel shuffle操作。
- 模型加速
- 目标是再保证模型准确率的前提下尽可能加速前向推理过程。
- 常见方法:
- 网络剪枝。
- 量化和分解。
- 知识蒸馏。
2.3、Channel Shuffle for Group Convolutions
- 在小型网络中,逐点卷积(pointwise convolution)不仅会占用较多计算资源并且还会让通道之间具有过多复杂的约束,这会显著地降低网络性能。在较大的模型中使用pointwise convolution也许相对好一些,然而小模型并不需要过多复杂的约束,否则容易导致模型难以收敛,并且容易陷入过拟合。
- 一个解决办法是:通道间稀疏连接(channel sparse connections)。使用组卷积可以一定程度上解决这个问题。
- 但是,使用组卷积也会带来副作用:信息只会在组内流通,组间不会有信息交互。为此,还需要使用channel shuffle来解决信息不流通的问题。
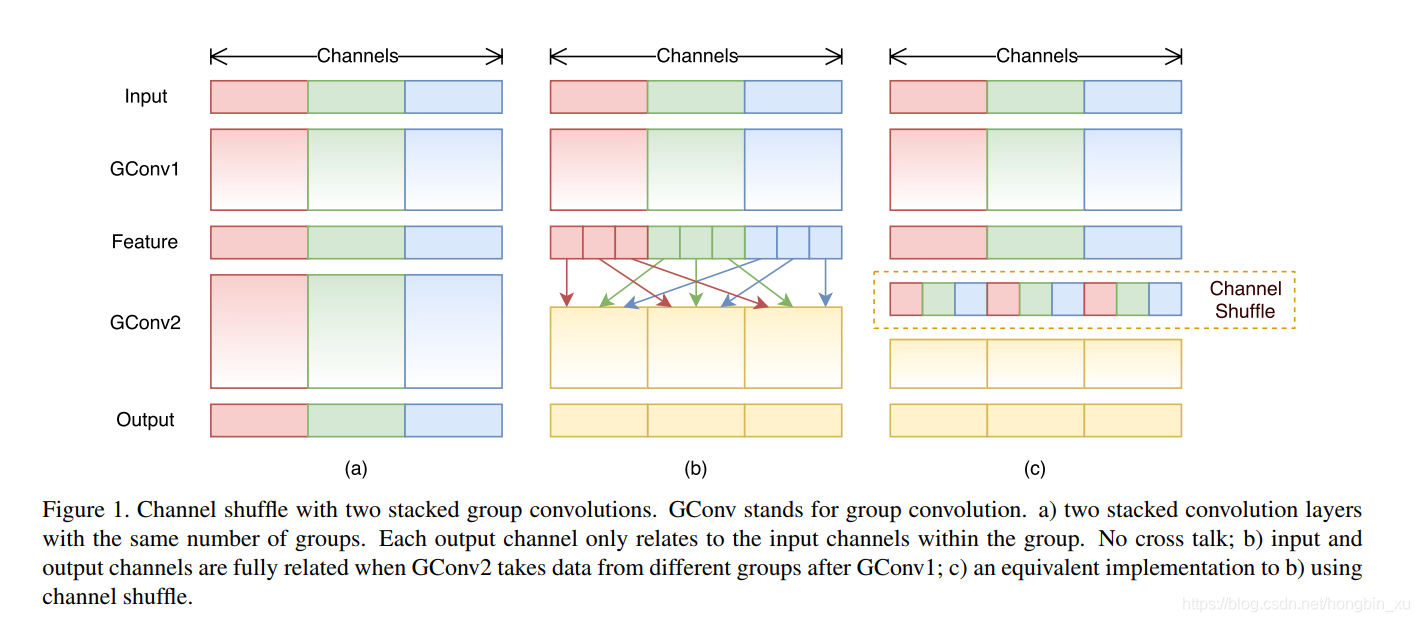
- channel shuffle操作:
- 假设一个卷积层上有 组,每组有 个通道,最后输出就有 个通道。
- reshape成 。
- 转置成 。
- 展开(flatten),再分成 组,作为下一层的输入。
2.4、Shuffle Unit
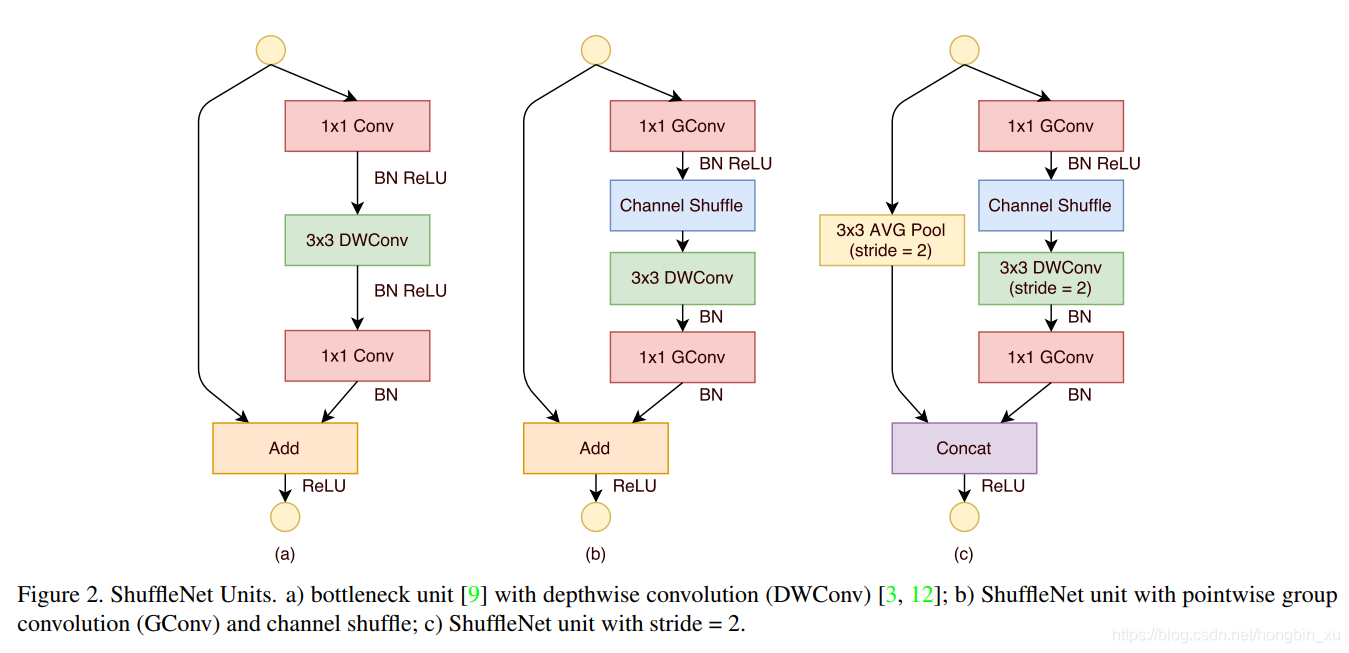
- 图(a)是残差卷积模块,标准 卷积转换为深度可分离卷积与 卷积的组合。中间加上BN和ReLU,构成基本单元。
- 图(b)是Shuffle Unit,将图(a)中的第一个 卷积替换成 组卷积(GConv)和channel shuffle组成的单元。
- 图©是用于降采样的Shuffle Unit,深度可分离卷积的步长改为2,为了适配主分支的feature map,在shortcut上加上了步长也为2的平均池化(AVG Pool )。
- 虽然深度可分离卷积可以减少计算量和参数量,但在低功耗设备上,与密集的操作相比,计算/存储访问的效率更差。故在ShuffleNet上只在bottleneck上有使用深度可分离卷积,尽可能的减少开销。
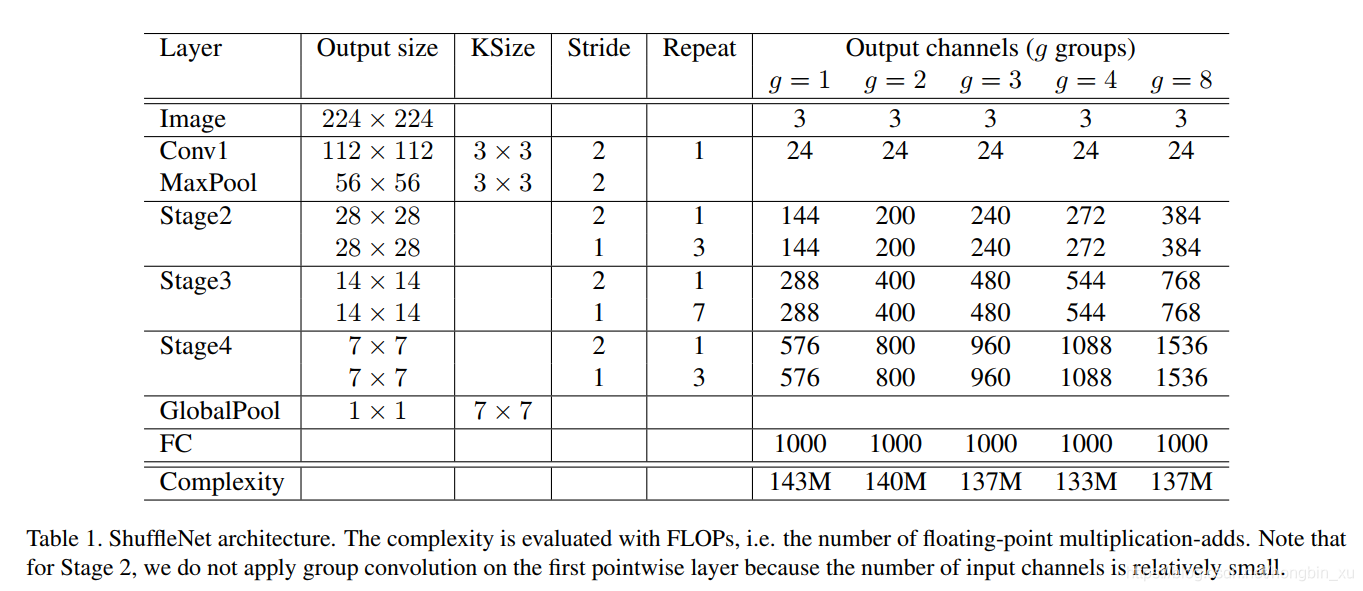
2.5、网络架构
2.6、实验
- Pointwise Group Convolutions
- 从结果来看,有组卷积的一致比没有组卷积(g=1)的效果要好。注意组卷积可获得更多通道间的信息,我们假设性能提高受益于更多的feature map通道数,这也有助于我们对更多信息进行编码。并且,较小的模型的feature map通道也更少,这意味着能更多地从增加feature map上获益。
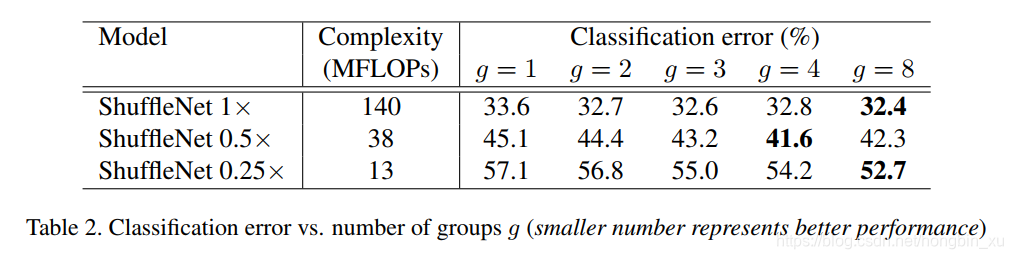
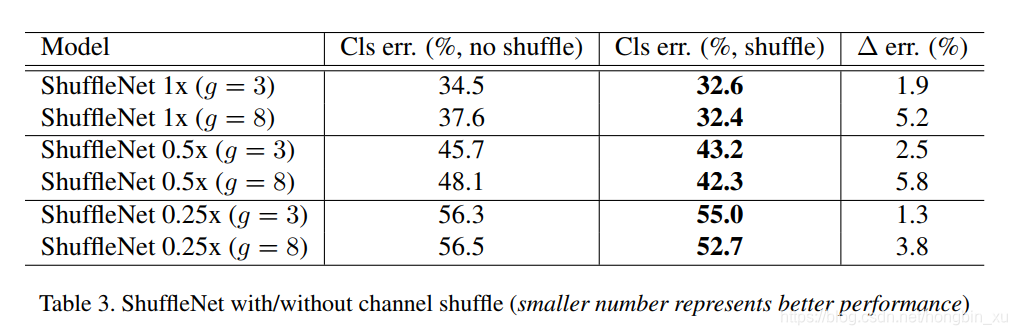
- Channel Shuffle vs. No Shuffle
- Comparison with Other Structure Units

- Comparison with MobileNets and Other Frameworks
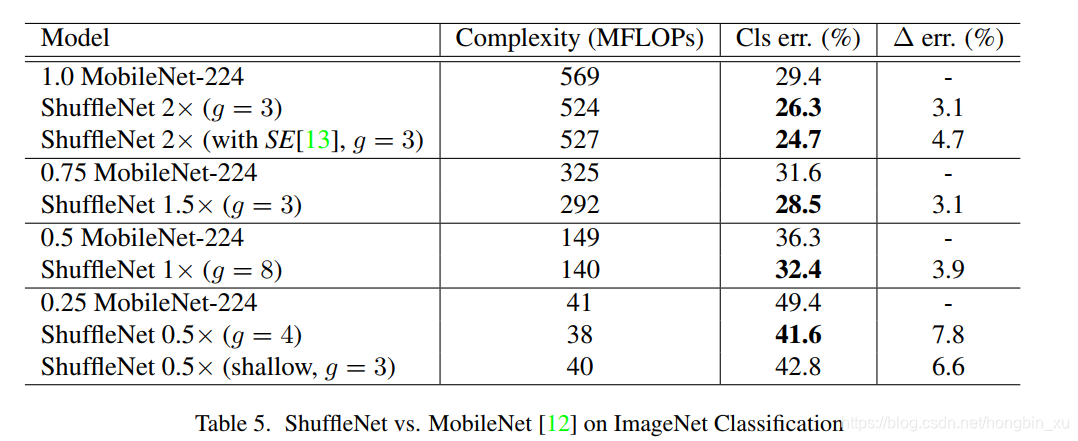
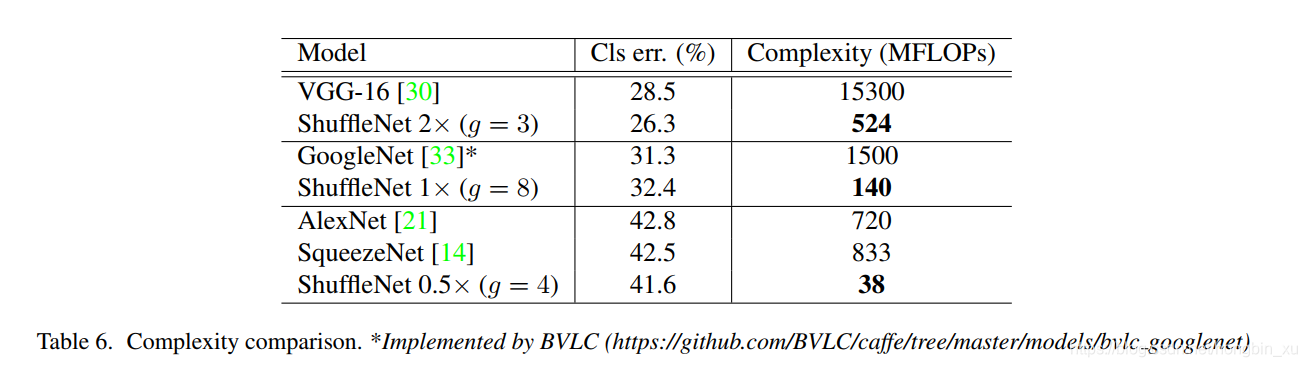
- Generalization Ability
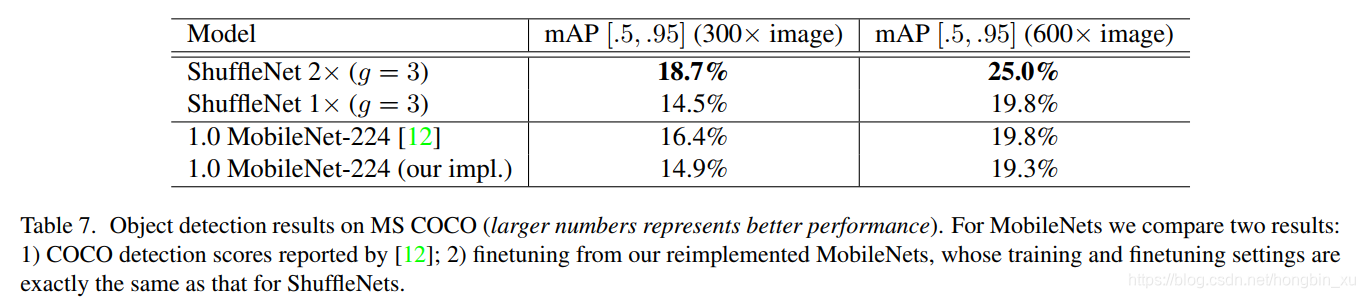
- 在MS COCO目标检测任务上测试ShuffleNet的泛化和迁移学习能力,以Faster RCNN为例:
- Actual Speedup Evaluation