Inception目的是为了增加网络深度和宽度的同时减少参数
论文地址:
[v1] Going Deeper with Convolutions, 6.67% test error
http://arxiv.org/abs/1409.4842
Inception v1的网络,将1x1,3x3,5x5的conv和3x3的pooling,堆叠在一起,一方面增加了网络的width,另一方面增加了网络对尺度的适应性;
由图:
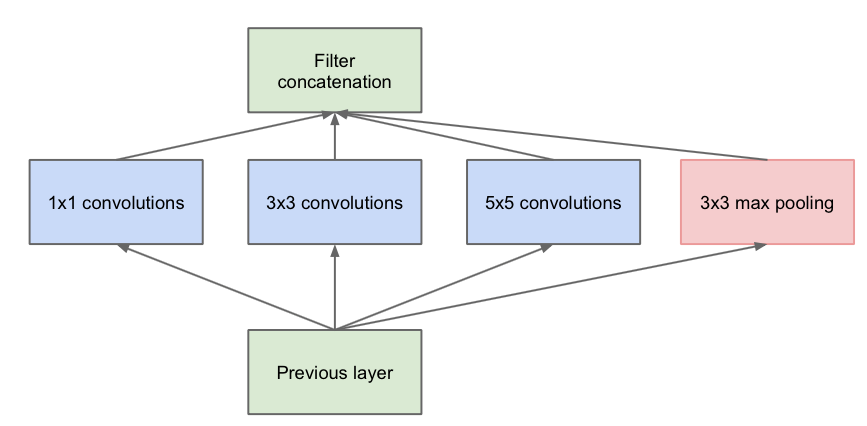
演化为:
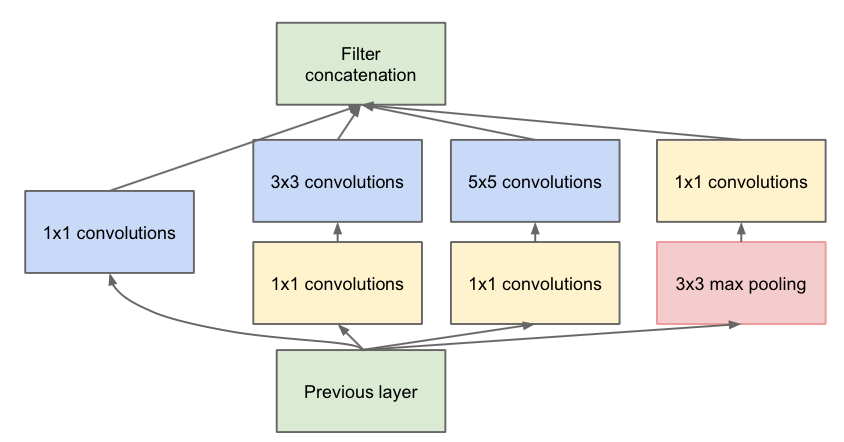
第一张图是论文中提出的最原始的版本,所有的卷积核都在上一层的所有输出上来做,那5×5的卷积核维度需要和previous layer保持一致,导致计算量很大,特征图厚度很大。为了避免这一现象提出的inception具有如下结构,在3x3前,5x5前,max pooling后分别加上了1x1的卷积核降低5x5卷积核维度,也就是Inception v1的网络结构。
举个例子:
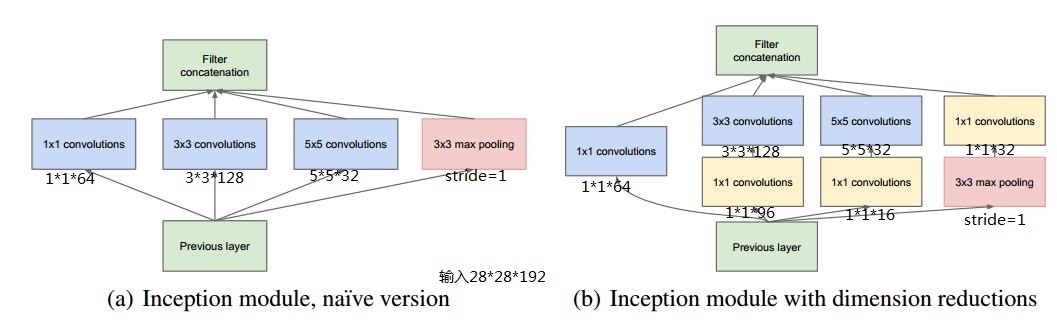
假设previous layer的大小为28*28*192,则:
对于图a:
weights大小为:1*1*192*64+3*3*192*128+5*5*192*32=387072
输出featuremap大小为:28*28*64+28*28*128+28*28*32+28*28*192=28*28*416
对于图b:
weights大小为:1*1*192*64+(1*1*192*96+3*3*96*128)+(1*1*192*16+5*5*16*32)+1*1*192*32=163328
输出featuremap大小为:28*28*64+28*28*128+28*28*32+28*28*32=28*28*256
Inception v1的亮点:
1.卷积层共有的一个功能,可以实现通道方向的降维和增维,至于是降还是增,取决于卷积层的通道数(滤波器个数),在Inception v1中1*1卷积用于降维,减少weights大小和feature map维度。
2.1*1卷积特有的功能,由于1*1卷积只有一个参数,相当于对原始feature map做了一个scale,并且这个scale还是训练学出来的,无疑会对识别精度有提升。
3.增加了网络的深度
4.增加了网络的宽度
5.同时使用了1*1,3*3,5*5的卷积,增加了网络对尺度的适应性
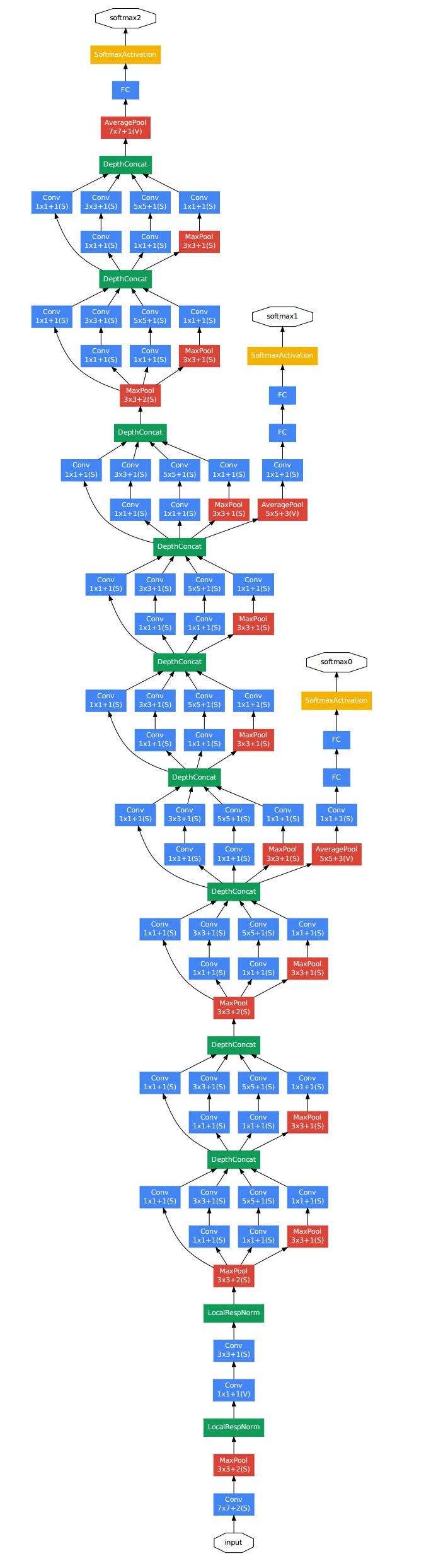
GoogleNet的结构图:
参考: