原文地址

https://arxiv.org/abs/2006.09882
初识
目前的对比学习虽然是Online Learning,但它依赖于显式的正负样本选取(通常只有当负样本较多时效果才会好),并且需要进行成对比较(pairwise comparisions),导致对显存和计算量的要求非常高。虽然有一些工作利用负样本队列和动量编码器来减缓显存压力,但是它们还是需要进行成对比较。
这里提到的对比学习主要基于Instance Discrimination,将每张图像视为一个类,同一图像的不同view(增广后的结果)互相作为正样本对,其他图像均作为负样本。对比学习构造NCE loss,拉近正样本对间距离,推远负样本对间距离。在计算损失更新网络权重时,当然是每次更新时考虑的负样本越多越好(有研究表明是hard negative越多越好),所以对batch size的要求会比较高(越大越好),这就会受限于显存。
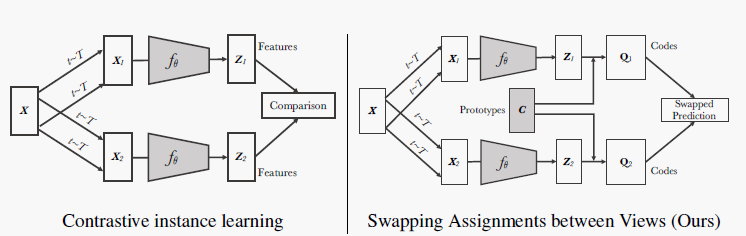
而本文提出的SwAV融合了"聚类+对比学习",使用聚类避免了直接与所有负样本进行pairwise comparison,而是直接与prototypes比较即可(可以在小batch size设置下进行学习),同时使用对比学习的框架来促进同一图像在不同视角下的一致性。具体来说,SwAV采用了一种交换式swapped的预测机制,从一个view下的表征预测另一个view下的code,下图就展示了对比学习与SwAV之间的异同。
此外,作者还提出了一个叫multi-crop的数据增广方法,同时构造多个不同分辨率的view(不增加显存和计算量),这在许多自监督学习方法上都能提点。最终作者提出的SwAV在使用ResNet-50作为backbone的基础上,在ImageNet数据集上达到了75.3%的top-1准确率,并在许多下游任务上超过了ImageNet预训练模型。
相知
整体架构
本文的目标就是利用聚类的思想在无监督条件下在线学习视觉表征,重点在于在线学习。为什么要强调在线学习呢?因为之前利用聚类进行表征学习主要是以离线的方式进行的,"聚类"和"学习"交替进行。并且每次聚类都需要遍历一遍数据集才能得到每幅图像对应的code,导致很难扩展在大数据集上(聚类时间太长)。
感兴趣的可以参考之前写过的Deep Clustering(和本文同一个作者),上文的
code可以理解为聚类预测结果,用于学习阶段的伪标签。
而本文提出的方法借助"对比学习"的框架,通过促进同一图像不同view的一致性来进行在线学习(不是直接去预测code,而是同时进行聚类+表征学习),这可以被视为"对比聚类分配(prototypes)“而不是直接"对比特征”。
SwAV的核心操作在于利用同一图像视图去预测另一个视图下的code,如下式所示, z t , z s z_t, z_s zt,zs为同一图像的两个不同视图,利用 z t z_t zt去预测 z s z_s zs视角下得到的code - q s q_s qs,同时用 z s z_s zs去预测 q t q_t qt。
其中
code指示了当前的聚类分配结果,即属于K个prototypes中的哪一个{c1, …, ck}.

具体细节
网络结构如下所示,给定图像 X X X,经过不同的增广变换 t t t得到两个视角下的增广图像 X 1 , X 2 X_1,X_2 X1,X2,经过编码器分别得到两个表征 z 1 , z 2 z_1,z_2 z1,z2(需要经过l2归一化映射到超球面上)。同时网络中存储着k个prototypes,表示为 C C C,可以利用 C C C和 z z z计算得到每个表征对应的code Q 1 , Q 2 Q_1,Q_2 Q1,Q2。再利用上面提到的交换预测形式,计算 Z 1 Z_1 Z1与 Q 2 Q_2 Q2的损失 + Z 2 Z_2 Z2与 Q 1 Q_1 Q1的损失。

文中使用损失函数为交叉熵,如下所示:对于表征 z t z_t zt和code - q s q_s qs, z t z_t zt先与 C C C做点乘,然后算softmax,得到预测 p t p_t pt,然后与 q s q_s qs计算交叉熵,其中τ为温度系数。

对训练集中图像的所有转换都采用上述"交换预测"的训练方式,会得到以下的损失函数,这个损失函数同时优化prototype和编码器特征来得到合适的表征 z z z:

那具体怎么得到code呢?即给定prototype集合 C C C和特征集合 Z Z Z,需要计算每个特征具体属于哪个prototype?SwAV参照SeLa的做法,将这个问题转换为最优运输(optimal transportation)来求解,如下式所示:

其中,Q就是最优运输的分配结果(code),H是熵函数,ε是一个超参数(文中设置得比较小),这是一个约束项,限制Q的结果不要太"激进"(这个表述可能有误,反正就是让Q的熵不要太低)。
但和SeLa不一样的是,整个算法是在线学习的,这也就意味着提供的 Z Z Z是基于batch的结果,然后每次前向的时候在线计算code。跟SeLa类似,增加一个约束项 - 将Q矩阵限制为transportation polytope,促使平均分配(equal partition),如下所示:

这个约束性不是很理解其具体原因,感兴趣的同学可以深入了解下SeLa这篇文章。但使用了这个约束项之后,可以促使每个batch中对每个prototype平均选择 B K \frac{B}{K} KB次。
然后就可以和SeLa一样,使用Sinkhorn-Knopp算法来快速求得近似解,作者在GPU上重新实现了Sinkhorn-Knopp算法,使得每次计算代价非常小(比如将4k个特征映射到3k个code上只需要35ms)。
此外,作者还讨论了是对Q矩阵进行离散化作为code好,还是连续比较好(简单理解就是hard label和soft label的区别),和SeLa不一样,在线聚类使用连续值作为code比较好(注意归一化)。
为了在小batch size上运行,为了算法能够顺利运行( Z Z Z集合不能比 C C C小),在具体实现时对于小batch size采用累积feature的方式,累积到足够大的 Z Z Z时再计算code。
类似于其他任务节省内存的方法,累积多个batch再进行更新。
Multi-crop
这是论文中提出的一个trick,与SwAV的算法没有太大关系,并且对于当前的自监督学习方法具有一定的通用性。
在之前的方法中,为了构造不同的view,首先会在原图上进行随机裁剪,然后再进行增广,然后互相作为正样本对。作者指出增加view的数量可以提升性能,但是也会增加显存的计算量。因此作者提出了multi-crop策略,使用两个标准分辨率的view,然后再加V个小分辨率的view,再送到网络中:

值得注意的是,最终只对标准分辨率的特征 z z z计算code。
部分实验
下面的表和图展示了SwAV在ImageNet数据集上进行自监督训练后,进行"Linear Classification"的性能。可以看到比当时最优的方法性能都要高不少,并且增加模型的宽度性能也会随之增长。

下表介绍了SwAV在下游任务的迁移性能,其性能均比ImageNet预训练模型的效果更好。

下表展示了使用小batch size的性能,仅使用大小为256的batch size进行训练,其性能也非常高。需要注意的是,使用小的batch size需要先累积多个batch的feature。这相比于使用负样本队列的Moco来说,存储的特征数量更小。

回顾
我们首先看SwAV这篇文章解决了什么问题:① 相比于SimCLR、MoCo这类对比学习方法来说,SwAV避免了大batch size,以及成对的特征对比,对负样本的需要量也没那么高。② 相比于DeepCluster和SeLa这两篇论文来说,SwAV避免了离线学习,而是进行在线聚类。作者也提到,SwAV可以解释为"swapping"机制的一种特例,当前批次的view去预测上一批次的code。
SwAV本质上是还是一种基于"聚类"的表征学习方法,并且参考了对比学习的框架提出了"swaped prediciton",最大的创新就是进行"Online Learning"。
为什么SwAV会work呢?因为从之前对比学习的工作来看,alignment和uniformity对于表征学习非常重要,alignment指的是正样本在特征空间足够接近,uniformity指的是所有特征应该尽可能均匀地分布在特征空间中。因此,之前的对比学习中需要正样本和负样本,而SwAV并没有显示对比负样本,不会导致模型崩塌吗?
答案是不会,因为SwAV虽然没有显示构造负样本和对比,但它其实本质是先对不同的特征进行了cluster划分,其中属于同一个cluster的特征会聚集在一起,而不同的cluster内的特征会互相推远。并且,作者并没有在特征空间上使用NCE损失(显示地拉近正样本间距离,推远负样本距离),而是构造了一个相互预测,使用同一图像下的不同view进行互相预测计算交叉熵损失。
但仅这样做还是会导致模型崩塌,因为存在一种捷径解:将所有的样本输出为同一个特征,所以作者在code分配时做了限制。利用SeLa提出的transportation polytope进行限制,强迫算法进行平均分配,并使用SK算法来快速计算code。
最后贴上整个算法的伪代码:

官方源码:https://github.com/facebookresearch/swav