背景:
VGG到GoogleNet等网络的演变证明了深度对于神经网络来说是至关重要的,ImageNet数据集挑战上的神经网络的深度也从16演变到了30+,深度的提升给网络带来了性能的提高,即越深越好。
这就引出了一个问题,是否可以通过简单的堆叠网络来得到越深的网络呢?
这里就得想到深层网络训练时存在一个经典障碍——梯度消失或梯度爆炸,而这个障碍已经很大程度上通过初始归一化(initial normalization)和中间层的归一化(BN)解决了,使得深层网络能够通过SGD等优化方式拟合。
于是便可以通过叠加更多的层来得到更深层的网络。
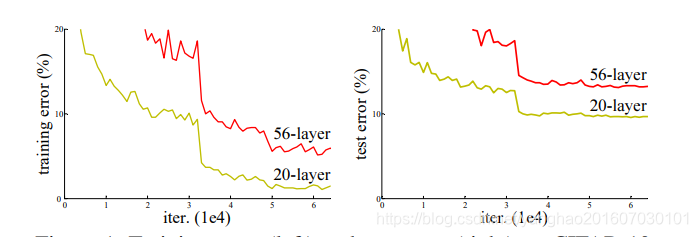
图1:简单的堆叠网络得到的20层和56层个不同深度的网络(plain network)在训练集和测试集上的错误率。
可以看见,56层的反而比20层的还差。这就有点不应该了,理论上来讲我越深即使不必你浅的网络更好,但至少不应该更差啊。比如在和浅层网络相同的那些层采用一样的权重,然后后面叠加一些恒等映射的层,这样至少不会比浅层更差。于是作者想到问题可能就是出现在恒等映射比较难拟合出来。
于是作者换了个思路,既然堆叠的网络直接拟合恒等映射比较难,那我就不直接拟合恒等映射,转而用堆叠的网络去拟合一个残差映射,间接的实现恒等映射。
即假设原本要拟合的一个潜在的映射函数是 H ( x ) H(x) H(x),用堆叠的网络去拟合另一个映射函数 F ( x ) : = H ( x ) − x F(x) := H(x)−x F(x):=H(x)−x。这样原本要拟合的映射函数就等价于 F ( x ) + x F(x)+x F(x)+x(这里假设 x x x和 F ( x ) F(x) F(x)维度相同)。这里的 x x x就是输入,网络的学习就变成了去学习 F ( x ) F(x) F(x)。在极端情况下,如果真的实现恒等映射才能最优,可以通过让堆叠网络去学习让 F ( x ) F(x) F(x)趋近于0来实现,这比让网络直接学习实现 H ( x ) = x H(x)=x H(x)=x这样的恒等映射容易多。
上述的 F ( x ) + x F(x)+x F(x)+x可以通过一个shortcut connection来实现,具体见下图。

图2.残差学习的原理图。x分支不需要额外的参数和复制计算,简单的实现恒等映射,并把结果加到堆叠网络的输出上。
如此一来,网络便克服了深层网络难以训练的问题,采用了shortcut来实现。
该模型的理论支撑:多个非线性层可以逐渐拟合一个复杂函数,那么多个非线性层同样也可以拟合这里我们的映射函数 F ( x ) F(x) F(x)。
note:如果x和 F ( x ) F(x) F(x)的维度不同,则x通过1×1卷积变换得到相同的维度。
网络结构:

图3.左边为VGG-19网络。中间为34层的普通网络(plain network),右边是34层残差网络。
中间的34层普通网络的设计受VGG网络启发,二者构造方式类似,网络基本采用的3×3卷积,并且遵循两个设计原则:
- 对于同样尺寸的特征图输出,网络层要有一样多的卷积核数量。
- 如果特征图尺寸减半,则要让特征图通道数(卷积核数量)增倍,以保持每层有相同的计算复杂度。
网络最后以一个全局平均池化层,一个带有softmax的1000维度的全卷积层结尾。
残差网络的设计则相当于是在中间普通网络的基础上加了shortcuts结构。
这里shortcut结构分两类:
一类是简单实现恒等映射的——identity shortcuts,如图3右边那个图上的实线;
还有一类是跨越两个通道数不同的层,因此需要增加通道数的——如图中虚心表示的。而增加通道数有两种方式,一种直接给增加的那些通道补0(zero-padding shortcuts),这种方式无额外参数;还有一种通过1×1卷积来增加通道数(projection shortcuts)。实验表面shortcuts的结构对结果影响不是特别大,作者的实现是增加通道的地方用projection shortcuts,其余地方直接用identity shortcuts。
残差块的改进:
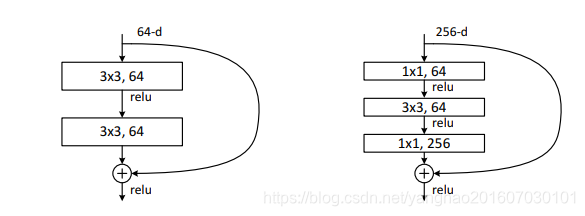
图4.两种残差函数 F ( x ) F(x) F(x)的结构,左边为residual building blocks,里面是简单的两个3×3卷积堆叠;右边为residual “bottleneck” building block,由两个1×1卷积加一个3×3卷积组成,1×1卷积起到降维和升维作用,即3×3卷积操作前先降维,减少计算量,计算完了再升维,这种方式能减少计算量,还能减少参数。
note:当网络的残差函数采用的“bottleneck” building block结构,那么shortcut应该采用identity shortcuts,残差结构对这个比较敏感。
用于目标检测的结果:
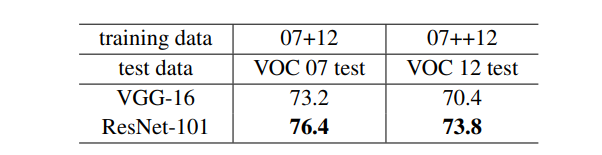
07+12表示PASCAL VOC2007的trainval数据集加MS COCO2012的trainval数据集,07++12表示PASCAL VOC2007的trainval+test数据集加MS COCO2012的trainval数据集。