目录
论文地址:https://arxiv.org/pdf/1512.03385.pdf
视频:撑起计算机视觉半边天的ResNet【论文精读】_哔哩哔哩_bilibili
博文:李沐论文精读系列一: ResNet、Transformer、GAN、BERT_神洛华的博客-CSDN博客_transformer gan的论文
代码:7.6. 残差网络(ResNet) — 动手学深度学习 2.0.0 documentation
1 摘要
主要内容
深度神经网络很难训练,我们使用residual(残差结构)使得网络训练比之前容易很多。在ImageNet上使用了152层的ResNet,比VGG多8倍,但是计算复杂度更低,最终赢下了ImageNet2015的分类任务第一名。在cifar-10上训练100-1000层的网络。仅仅是把之前的网络换成残差网络,在coco数据集上就得到了28%的改进。同样也赢下了ImageNet目标检测、coco目标检测和coco segmentation的第一名。
主要图表
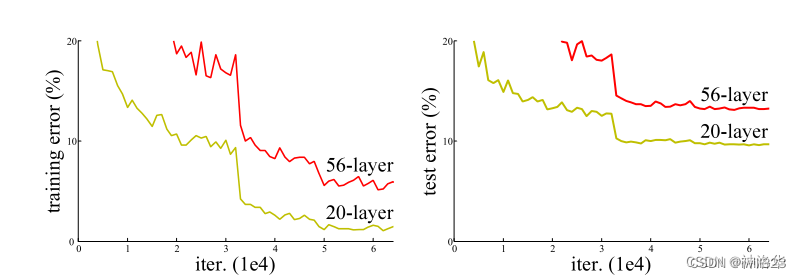
上面这张图是没有使用残差结构的网络训练误差和测试误差,结果显示更深的层训练误差和测试误差比浅层更高,即深层网络其实是训练不动的。下面这张图,使用resnet结构的网络效果对比图。可以看到右侧使用残差结构后,34层的网络训练和测试的误差都更低。

2 导论
2.1为什么提出残差结构
深度卷积神经网络是非常有效的,因为可以堆叠很多层,不同层可以表示不同level的特征。但是网络很深的时候很难优化,因为容易出现梯度消失或者梯度爆炸,解决办法一是一个好的网络权重初始化,使权重不能太大也不能太小;二是加入一些normalization,比如BN,这样可以校验每个层之间的输出,以及梯度的均值和方差,避免有些层太大或太小,这样比较深的网络是可以训练的(可以收敛)。但还有一个问题,深层网络性能会变差,精度也会变差。
深层网络性能变差,不是因为网络层数多、模型变复杂而过拟合,因为过拟合是训练误差低,测试误差高,而这里训练误差也变高了。那为什么会这样呢?从理论上来说,给一个浅层网络中加入一些层,得到一个深一些的网络,后者的精度至少不应该变差,因为后者至少让新加的层做到identity mapping,而其它层直接从前者复制过来。如果能将新添加的层至少训练成恒等映射(identity mapping),那么新模型和原模型将同样有效。同时由于新模型由于更复杂,因此可能得出更优的解来拟合训练数据集,降低训练误差。但是实际上,SGD优化器无法找到这个比较优的解。
所以作者显式地构造一个identity mapping,如果有些层学习效果不好,那么起码做到恒等映射,不要影响到后面层的学习,使得深层模型的精度至少不会变得更差。假设在原有层上添加一些新的层后,要学到的映射是 H(x) ,但是新的层不是直接学H(x) ,而是学习 H(x)−x,这部分用F(x)表示。即新加入的层学习残差函数F(x) = H(x) - x就行。模型的最后输出是F(x)+x。这种新加入的层就是residual。优化的目标成了F(x)。
结构如下图(右)所示:
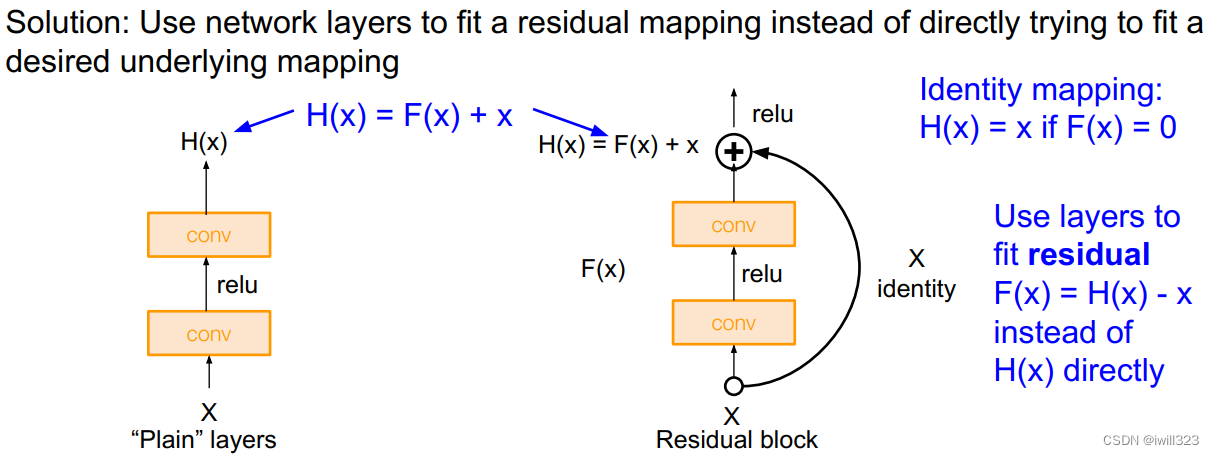
F(x)+x在数学上就是直接相加,在神经网络中是通过shortcut connections实现(shortcut就是跳过一个或多个层,将输入直接加到这些跳过的层的输出上)。shortcut其实做的是一个identity mapping(恒等映射),而且这个操作不需要学习任何参数,不增加模型的复杂度。就多了一个加法,也不增加计算量,网络结构基本不变,可以正常训练。
2.2 实验验证
在imagenet上做了一系列实验进行验证。结果表明,1)加了残差的网络容易优化,2)残差网络由于网络堆的更深,精度也会提高。
3 实验部分
3.1 不同配置的ResNet结构

对照下面ResNet34结构图:(3+4+6+3)=16个残差模块,每个模块两层卷积层。再加上第一个7×7卷积层和最后一个全连接层,一共是34层。
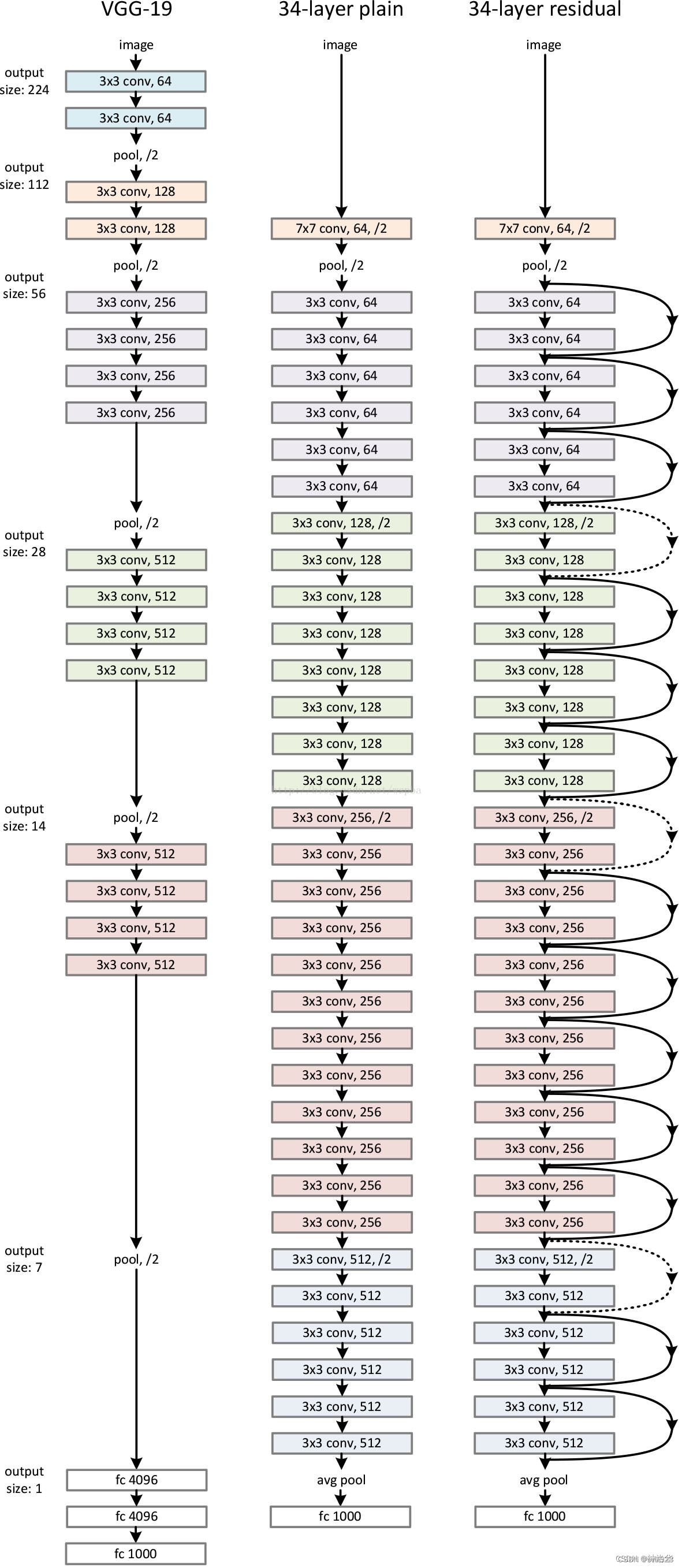
3.2 残差结构效果对比

three major observations:
- 34层比18层好,degradation problem解决了
- 使用残差收敛更快,收敛结果更好
- 对于18层,The 18-layer plain/residual nets are comparably accurate, but the 18-layer ResNet converges faster
3.3 残差结构中,输入输出维度不一致如何处理
A. pad补0,使维度一致;
B. 维度不一致的时候,使其映射到统一维度,比如使用全连接或者是CNN中的1×1卷积,使输出通道是输入的两倍。在resnet中,如果把输出通道数翻了两倍,输入的高和宽通常减半,因此1×1卷积stride=2
C. 不管输入输出维度是否一致,都进行投影映射。
下面作者对这三种操作进行效果验证。从下面结果可以看到,B和C效果差不多,都比A好。但是做映射会增加很多复杂度,考虑到ResNet中大部分情况输入输出维度是一样的(只有4个模块衔接时,通道数会变),作者最后采用了方案B。

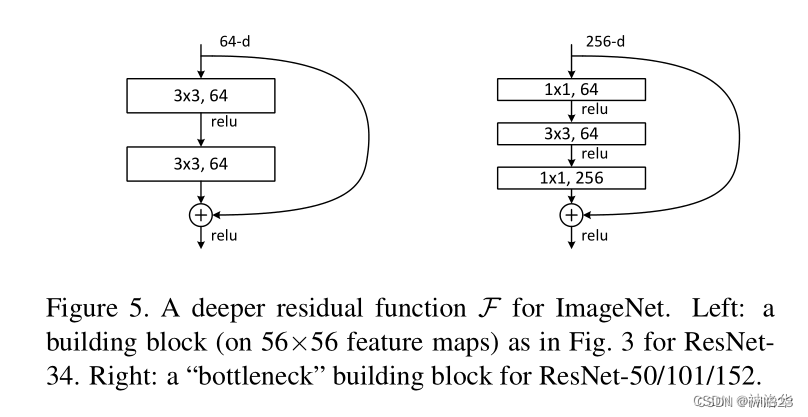
3.4 深层ResNet引入瓶颈结构Botleneck
在ResNet-50及以上的结构中,模型更深了,可以学习更多的模式,所以通道数也要变大。比如前面模型配置表中,ResNet-50/101/152的第一个残差模块输出都是256维,与64维相比,增加到4倍,而计算量要增加到16倍,划不来
设计了Bottleneck结构来提高效率。比如对于第一个模块,经过一个1×1卷积将输入从256维降为64维,然后做3×3卷积,经过一个1×1卷积再升维回256维。这样操作之后,复杂度和左侧图是差不多的。所以ResNet-50对比ResNet-34理论计算量变化不大。但是实际上1×1卷积计算效率没有别的卷积高,所以ResNet-50计算还是要贵一些。
4 代码实现
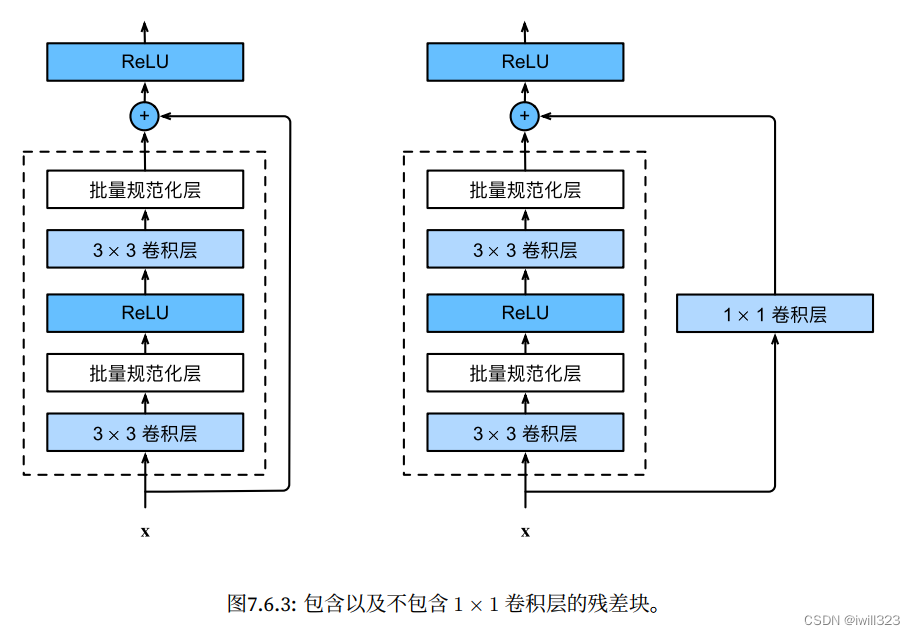
4.1 残差块
ResNet沿用了VGG完整的3×3卷积层设计。
- 残差块里首先有2个有相同输出通道数的3×3卷积层, 每个卷积层后接一个批量规范化层和ReLU激活函数。
- 如果2个卷积层的输出与输入形状一样,则通过跨层数据通路,将输入直接加在最后的ReLU激活函数前。
- 如果想改变通道数,就需要引入一个额外的1×1卷积层来将输入变换成需要的形状后,再做相加运算。
class Residual(nn.Module):
def __init__(self, input_channels, num_channels, use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)此代码生成两种残差块:(use_1x1conv=True/False)
- 步幅为2 ,高宽减半,通道数增加。所以shortcut连接部分会加一个1×1卷积层改变通道数
blk = Residual(3,6, use_1x1conv=True, strides=2)
blk(X).shapetorch.Size([4, 6, 3, 3])
- 步幅为1,高宽不变,将输入添加到输出(应用ReLU非线性函数之前)
blk = Residual(3,3)
X = torch.rand(4, 3, 6, 6)
Y = blk(X)
Y.shapetorch.Size([4, 3, 6, 6])
上述实现和pytorch有点差别。pytorch在实现的时候,use_1x1conv之后还做了bath norm:
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
用到的1X1卷积:
def conv1x1(in_planes: int, out_planes: int, stride: int = 1) -> nn.Conv2d:
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)4.2 ResNet模型
Full ResNet architecture:
- Stack residual blocks
- Every residual block has two 3x3 conv layers
- Periodically, double of filters and downsample spatially using stride 2 (/2 in each dimension)
- Additional conv layer at the beginning (stem)
- No FC layers at the end (only FC 1000 to output classes)
- In theory, you can train a ResNet with input image of variable sizes
- Global average pooling layer after last conv layer
ResNet的前两层跟GoogLeNet中的一样: 在输出通道数为64、步幅为2的7×7卷积层后,接步幅为2的3×3的最大汇聚层。 不同之处在于ResNet每个卷积层后增加了批量规范化层。
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))下面,ResNet使用4个由残差块组成的模块,每个模块使用若干个同样输出通道数的残差块。
- 对于第一个模块:输出通道数同输入通道数一致,所以不用使用1x1conv;由于之前已经使用了步幅为2的最大汇聚层,所以无须减小高和宽。
- 对于之后的每个模块:第一个残差块里,输出通道数同输入通道数不一致,所以要使用1x1conv;第一个残差块将上一个模块的通道数翻倍,并将高和宽减半。
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels,
use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
全局平均汇聚层,以及全连接层输出
net = nn.Sequential(b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(), nn.Linear(512, 10))观察一下ResNet中不同模块的输入形状是如何变化的
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t', X.shape)
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 128, 28, 28])
Sequential output shape: torch.Size([1, 256, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
AdaptiveAvgPool2d output shape: torch.Size([1, 512, 1, 1])
Flatten output shape: torch.Size([1, 512])
Linear output shape: torch.Size([1, 10])
每个模块有4个卷积层(不包括恒等映射的1×1卷积层)。 加上第一个7×7卷积层和最后一个全连接层,共有18层。 因此,这种模型通常被称为ResNet-18。 通过配置不同的通道数和模块里的残差块数可以得到不同的ResNet模型,例如更深的含152层的ResNet-152。 虽然ResNet的主体架构跟GoogLeNet类似,但ResNet架构更简单,修改也更方便。这些因素都导致了ResNet迅速被广泛使用
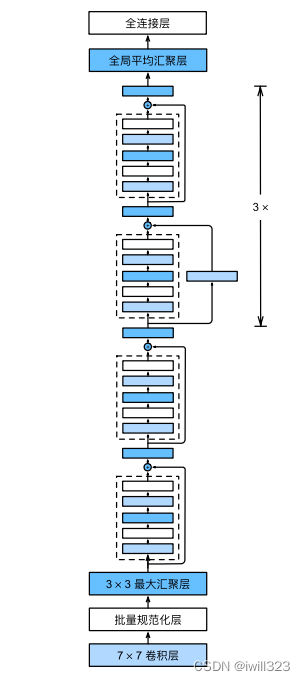
完整代码:
class Residual_Block(nn.Module):
def __init__(self, ic, oc, stride=1):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(ic, oc, kernel_size=3, padding=1, stride=stride),
nn.BatchNorm2d(oc),
nn.ReLU(inplace=True)
)
self.conv2 = nn.Sequential(
nn.Conv2d(oc, oc, kernel_size=3, padding=1),
nn.BatchNorm2d(oc)
)
self.relu = nn.ReLU(inplace=True)
if stride != 1 or (ic != oc): # 对于resnet18,or的两个条件一直,因为改变通道的时候,同时stride == 2
self.conv3 = nn.Sequential(
nn.Conv2d(ic, oc, kernel_size=1, stride=stride),
nn.BatchNorm2d(oc)
)
else:
self.conv3 = None
def forward(self, X):
Y = self.conv1(X)
Y = self.conv2(Y)
if self.conv3:
X = self.conv3(X)
Y += X
return self.relu(Y)
class ResNet(nn.Module):
def __init__(self, block = Residual_Block, num_layers = [2,2,2,2], num_classes=11):
super().__init__()
self.preconv = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
self.layer0 = self.make_residual(block, 64, 64, num_layers[0])
self.layer1 = self.make_residual(block, 64, 128, num_layers[1], stride=2)
self.layer2 = self.make_residual(block, 128, 256, num_layers[2], stride=2)
self.layer3 = self.make_residual(block, 256, 512, num_layers[3], stride=2)
self.postliner = nn.Sequential(
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(),
nn.Linear(512, num_classes)
)
def make_residual(self, block, ic, oc, num_layer, stride=1):
layers = []
layers.append(block(ic, oc, stride))
for i in range(1, num_layer):
layers.append(block(oc, oc))
return nn.Sequential(*layers)
def forward(self, x):
out = self.preconv(x)
out = self.layer0(out) # [64, 32, 32]
out = self.layer1(out) # [128, 16, 16]
out = self.layer2(out) # [256, 8, 8]
out = self.layer3(out) # [512, 4, 4]
out = self.postliner(out)
return out 5 训练和测试
训练方法
- 图像处理:
- The image is resized with its shorter side randomly sampled in [256, 480].
- A 224×224 crop is randomly sampled from an image or its horizontal flip, with the per-pixel mean subtracted.
- The standard color augmentation is used.
- Batch Normalization after every CONV layer and before activation
- Xavier initialization from He et al.
- SGD + Momentum (0.9) + Weight decay of 1e-5
- Learning rate: starts from 0.1, divided by 10 when validation error plateaus
手动调整,现在不用这种做法。李老师认为即使精度变化已经平了,也不能跳的太早,否则后期收敛无力。表面上看没有做什么事情,但是模型在微调,不过在宏观数据上看不出来,多训练一会是不错的选择
- Mini-batch size 256
- No dropout used
测试
the standard 10-crop testing:给到测试图片,随机或按一定规则采样10张图片,在每个子图上做预测,把结果做评价 。并且不是在一个分辨率上,而是在不同分辨率上采样{224,256,384,480,640}.
6 CIFAR-10 实验
为什么在cifar-10这样一个小的数据集上(32*32图片5w张)训练1202层的网络,过拟合也不是很厉害。为何transformer那些模型几千亿的参数不会过拟合,李沐认为是加了残差连接之后,模型内在复杂度大大降低了。理论上模型加一些层,模型也至少可以将后面的层学成恒等映射,使精度不会变差,也就是更容易训练出一个简单模型来拟合数据,所以加入残差连接等于是模型复杂度降低了
7 为什么残差网络有效
ResNet就是在CNN主干上加了残差连接,这样如果新加的层训练效果不好的话,至少可以fallback变回简单模型,所以精度不会变差。
作者猜想拟合残差f(x) = H(x) - x更加容易。当理想映射f(x)极接近于恒等映射时,残差映射易于捕捉恒等映射的细微波动,其实就是看本层相对前几层是否有大的变化,相当于是一个差分放大器的作用。
We hypothesize that it is easier to optimize the residual mapping than to optimize the original, unreferenced mapping
If the optimal function is closer to an identity mapping than to a zero mapping, it should be easier for the solver to find the perturbations with reference to an identity mapping, than to learn the function as a new one.
现在来看,ResNet训练的比较快,是因为梯度保持的比较好。下面g(x)是原来的层,f()是新加的层。增加了一个乘数,导致新加的层容易导致梯度消失,因为梯度一般较小(0-1的高斯分布)。加了残差连接,梯度包含了之前层的梯度(蓝色加号右侧项 ),这样不管加了多深,梯度会保持的比较大,训练结果不会太快“躺平”(train不动),SGD跑得多就训练的比较好。SGD的精髓就是,只要梯度比较大,就可以一直训练,反正有噪音,慢慢的总是会收敛,最后效果就会比较好用随机梯度下降来优化人生 - 知乎。并且由于梯度包含了之前学习到的那一项,所以残差网络学的快

论文推荐
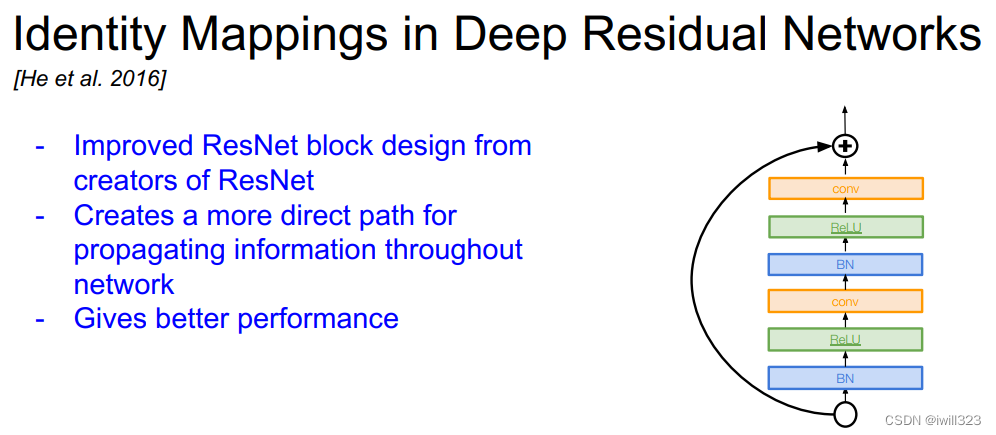
1、Identity Mappings in Deep Residual Networks
论文中给了非常多的ResidualBlock的设计。可以自己尝试去实现几种看看效果。

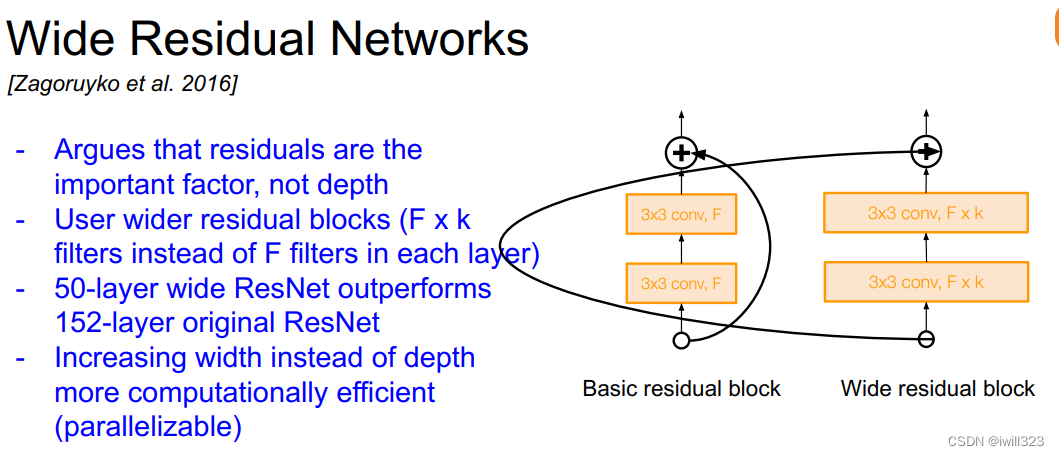
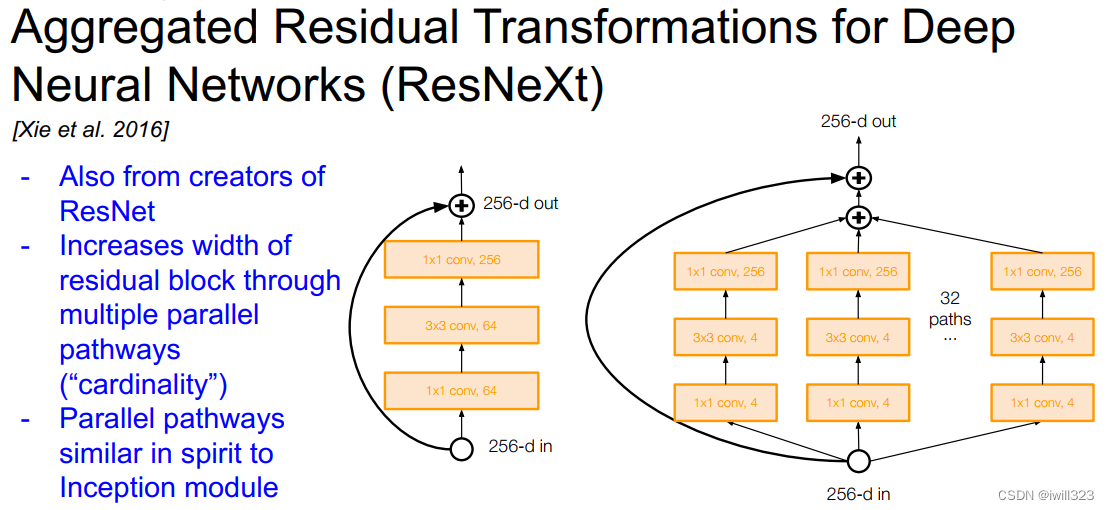
2、 Desely Connected Convolutional Networks
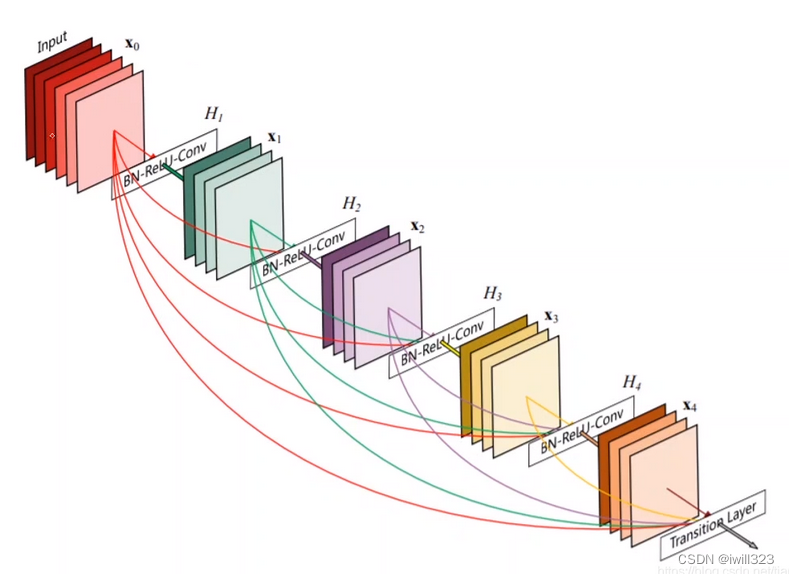
这也是一种值得探究的实现方式。