前言:
{
这次记录YOLO的最新版本YOLOv3的相关改动,文章地址:https://arxiv.org/pdf/1804.02767.pdf。
}
正文:
{
第二节中提到了相关改变。
当与标签框非最佳匹配的框先验(box prior)的预测与标签框的覆盖没有超过一个阈值时,此预测只参与目标性得分的损失计算(即其目标性为0);并且当与标签框非最佳匹配的框先验的预测与标签框的覆盖超过一个阈值时,此预测不参与损失计算。即下式的最后一行被改变了,现在的标签目标性只有0和1。
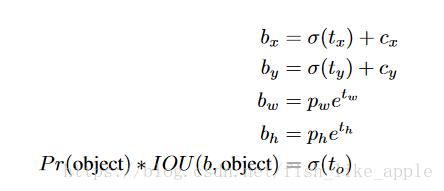
其中b为标准框的各种属性,t为网络输出的各种框属性,p为框先验的属性,即anchor box的高和宽,并且σ()为修正函数。
取消了类预测的softmax,现在每个框可以属于多个类了(用阈值来判定类?文章这里没说明。)。
使用了一种类似金字塔结构的结构,对最终特征图和前面某2层的经过上采样的特征图进行concate,以形成新的特征图,之后又加了几层卷积层,因此得到新的最终特征图。(这里有点不明白,文章上说对最终尺度还有额外的设计,但是所有尺度的预测不都是在一起的吗?)
特征提取网络变成了Darknet-53,如表1。
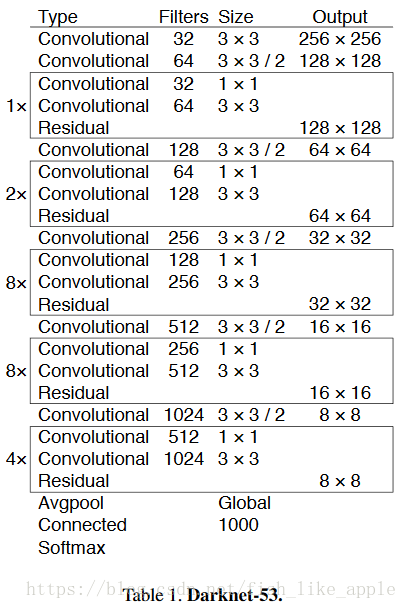
新特征提取网络更深,也使用了残差单元。此特征提取网络与其他特征提取网络的比较如表2。
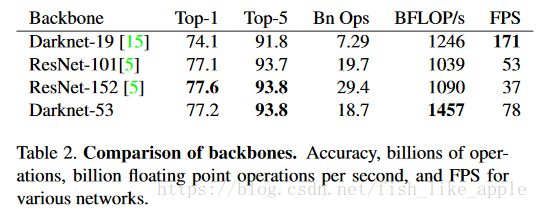
可见在保证效果的情况下,新特征提取网络也达到了较快的速度。
第三节说了YOLOv3的一些问题:1,不能很精确地定位,因为提高上述阈值会显著降低效果;2,之前是检测小目标有问题,现在是检测较大目标有问题,因为使用了类金字塔结构。
第四节提到了行不通的方法,有2个方面,1是输出的表示方式,2是损失函数。看样子输出的表示方式也是很重要的(尤其是选择线性形式还是对数形式)。
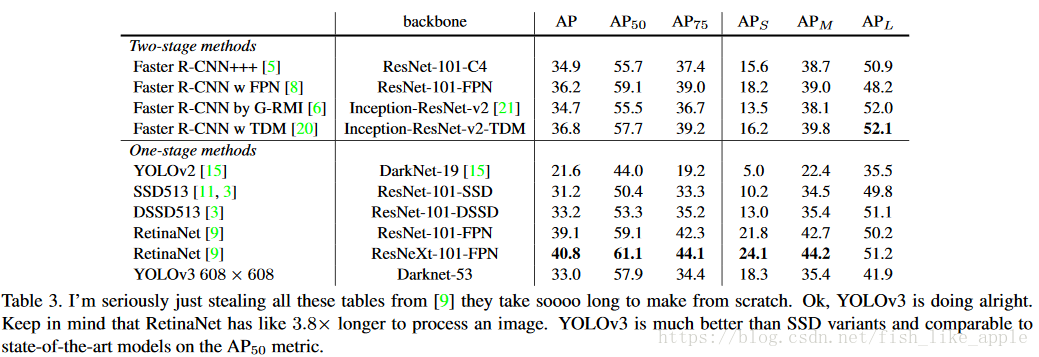
最后附上横向比较结果,见表3。
}
结语:
{
从表3可以看出,效果最好的目标检测结构是RetinaNet,如果不考虑速度的话,RetinaNet更值得考虑。
这篇文章的风格很随意,也很简洁,有耳目一新的感觉。
很多都是个人理解,如有不当欢迎指出。
}