Real-time Object Detection with YOLO, YOLOv2 and now YOLOv3 - YOLOv3
https://medium.com/@jonathan_hui/real-time-object-detection-with-yolo-yolov2-28b1b93e2088
You only look once (YOLO) is an object detection system targeted for real-time processing. We will introduce YOLO, YOLOv2 and YOLO9000 in this article. For those only interested in YOLOv3, please forward to the bottom of the article. Here is the accuracy and speed comparison provided by the YOLO web site.
https://pjreddie.com/darknet/yolo/
https://medium.com/@jonathan_hui/real-time-object-detection-with-yolo-yolov2-28b1b93e2088
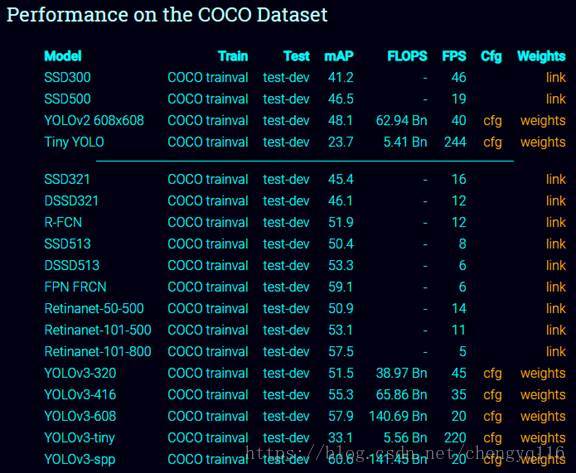
YOLOv3
https://www.youtube.com/watch?v=MPU2HistivI&feature=youtu.be
A quote from the YOLO web site on YOLOv3:
On a Pascal Titan X it processes images at 30 FPS and has a mAP of 57.9% on COCO test-dev.
Class Prediction
Most classifiers assume output labels are mutually exclusive. It is true if the output are mutually exclusive object classes. Therefore, YOLO applies a softmax function to convert scores into probabilities that sum up to one. YOLOv3 uses multi-label classification. For example, the output labels may be “pedestrian” and “child” which are not non-exclusive. (the sum of output can be greater than 1 now.) YOLOv3 replaces the softmax function with independent logistic classifiers to calculate the likeliness of the input belongs to a specific label. Instead of using mean square error in calculating the classification loss, YOLOv3 uses binary cross-entropy loss for each label. This also reduces the computation complexity by avoiding the softmax function.
Bounding box prediction & cost function calculation
YOLOv3 predicts an objectness score for each bounding box using logistic regression. YOLOv3 changes the way in calculating the cost function. If the bounding box prior (anchor) overlaps a ground truth object more than others, the corresponding objectness score should be 1. For other priors (anchor) with overlap greater than a predefined threshold (default 0.5), they incur no cost. Each ground truth object is associated with one boundary box prior only. If a bounding box prior is not assigned, it incurs no classification and localization lost, just confidence loss on objectness. We use tx and ty (instead of bx and by) to compute the loss.
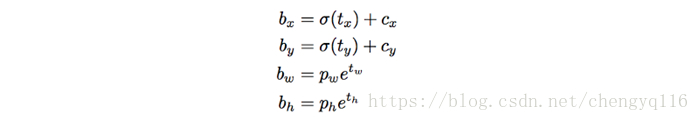
tw is generated from a sigma function. So the range is 0 to 1. The exponential function is likely because we want the bbox to have shape closer to the anchor box.
Feature Pyramid Networks (FPN) like Feature Pyramid
YOLOv3 makes 3 predictions per location. Each prediction composes of a boundary box, a objectness and 80 class scores, i.e. N × N × [3 × (4 + 1 + 80) ] predictions.
YOLOv3 makes predictions at 3 different scales (similar to the FPN):
- In the last feature map layer.
- Then it goes back 2 layers back and upsamples it by 2. YOLOv3 then takes a feature map with higher resolution and merge it with the upsampled feature map using element-wise addition. YOLOv3 apply convolutional filters on the merged map to make the second set of predictions.
- Repeat 2 again so the resulted feature map layer has good high-level structure (semantic) information and good resolution spatial information on object locations.
To determine the priors, YOLOv3 applies k-means cluster. Then it pre-select 9 clusters. For COCO, the width and height of the anchors are (10×13), (16×30), (33×23), (30×61), (62×45), (59× 119), (116 × 90), (156 × 198), (373 × 326). These 9 priors are grouped into 3 different groups according to their scale. Each group is assigned to a specific feature map above in detecting objects.
Feature extractor
A new 53-layer Darknet-53 is used to replace the Darknet-19 as the feature extractor. Darknet-53 mainly compose of 3 × 3 and 1 × 1 filters with skip connections like the residual network in ResNet. Darknet-53 has less BFLOP (billion floating point operations) than ResNet-152, but achieves the same classification accuracy at 2x faster.
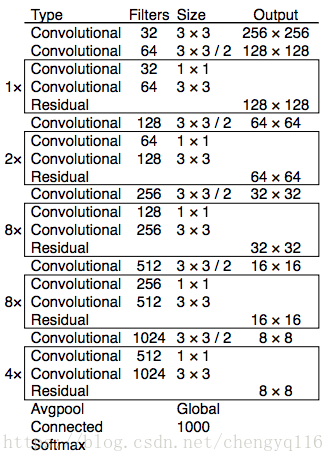
YOLOv3 performance
YOLOv3’s COCO AP metric is on par with SSD but 3x faster. But YOLOv3’s AP is still behind RetinaNet. In particular, AP@IoU=.75 drops significantly comparing with RetinaNet which suggests YOLOv3 has higher localization error. YOLOv3 also shows significant improvement in detecting small objects.
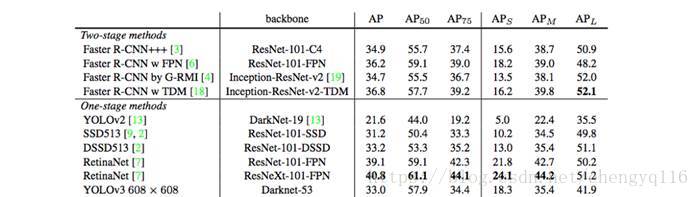
YOLOv3 performs very well in the fast detector category when speed is important.

Resources
SSD or YOLO all have problems to detect small objects comparing with regional based object detection. https://medium.com/@jonathan_hui/what-do-we-learn-from-single-shot-object-detectors-ssd-yolo-fpn-focal-loss-3888677c5f4d should have some explanation. The problem is the feature map they use has very low resolution and the small object features get too small to be detectable. YOLO3 applies FPN technique to address that problem.
The concept has some similarity with Faster R-CNN. Some quotes from the Faster R-CNN paper:
“We assign a positive label to an anchor that has an IoU overlap higher than 0.7 with any ground-truth box.
We assign a negative label to a non-positive anchor if its IoU ratio is lower than 0.3 for all ground-truth boxes. Anchors that are neither positive nor negative do not contribute to the training objective.”
Faster R-CNN compute the confidence loss from these 2 groups only. Faster R-CNN can have multiple positive anchors but in YOLOv3, just the top match. So the confusion is from:
“If a bounding box prior is not assigned to a ground truth object it incurs no loss for coordinate or class predictions, only objectness.”
I interpret it as: for the group with low confidence score, the label assigned is 0 and therefore we compute penalty for its confidence score not being 0.
YOLOv2 uses Darknet-19 and YOLOv3 uses Darknet-53 to extract features.
FPN addresses this multi-scale problem. https://medium.com/@jonathan_hui/understanding-feature-pyramid-networks-for-object-detection-fpn-45b227b9106c Take a look and it will explain some of the reason. BTW, SSD’s CONV4_3 is 38 x 38. So this resolution already triggers bad performance comparing with Faster R-CNN for small objects in COCO dataset.
This is a tradeoff between computation speed and accuracy. The selling point for single shot detector is speed. So they are very cautious about the speed and mAP tradeoff. In particular, very careful on what complexity may added to the detector. There is a survey paper from Google about how many proposals should make per cell. For regional based detectors, it turns out smaller than some research paper used.
We use visual tool to mark the boundary of objects in the training data (like https://github.com/puzzledqs/BBox-Label-Tool) and have program to convert them into the labels we want. We find the center of the bounding box and assign to the corresponding grid with prob=1.0. It is expensive and therefore they use public dataset like COCO. The confidence score (and objectness) is more like a probability rather than an unlimited range number.
FPN have 2 path, The bottom-up path is just like the regular CNN which reducing the spatial dimension in extracting features. The top-down is the reverse direction (similar to deconvolution). So in YOLO3, in the reverse direction, it goes back 2 layers (instead of 1) to generated the feature maps needed for object detection. If you are very interested in why single shot detector has problems dealing with small objects, the FPN article should explain the issue and propose the solution which YOLOv3 based on.
The removal of a pooling layer helps YOLO to detect smaller objects.
We train the model with the assumption that it has one object per cell. For example, we can label the training data that way and computing the loss function the same.
But in testing, is it legitimate to have one boundary box predicting cat and another for dog in the same grid cell (assuming YOLOv2 - not in v1) and the ground truth has dog and cat in the same grid also? The NMS described will work if this is more desirable behavior. Otherwise, you can do what you have in mind also. If you look at YOLOv3, they are actually not penalizing some predictions that have high confidence but not the best.
In some perspective, from YOLOv1 to v3, the one object per grid is more for the training mechanism.
For Faster R-CNN, the boundary box is predicted relative to anchors. And we do put some constraint on the value of delta x & y. But YOLOv2 switch to anchor box idea too. So the author claim is more a theoretically benefit rather than a solid proof.
I don’t think we can find the real answer easily since there are too many moving parts. I personally suspect one possible reason is that YOLO make fewer predictions.
As discussed above, after our initial training on images at 224 × 224 we fine tune our network at a larger size, 448. For this fine tuning we train with the above parameters but for only 10 epochs and starting at a learning rate of 10-3. At this higher resolution our network achieves a top-1 accuracy of 76.5% and a top-5 accuracy of 93.3%.
So this is slightly different from his claim early in the paper. But this is the implementation detail which may not be very significant in understand the idea. But Redmon is very good at detailing his improvement which I really appreciate. Many other paper is sometimes very hard to know their implementation details to replicate the result.
Wordbook
Titan [taɪtn]:n. 巨人,提坦,太阳神
pascal [‘pæsk(ə)l]:n. 帕斯卡 (压力的单位)
mutually exclusive:互相排斥的
cross-entropy:互熵,交叉熵
mean square error:均方误差,中误差,均方差
pyramid [‘pɪrəmɪd]:n. 金字塔,角锥体 vi. 渐增,上涨,成金字塔状 vt. 使…渐增,使…上涨,使…成金字塔状
semantic [sɪ’mæntɪk]:adj. 语义的,语义学的
By The Way,BTW:顺便,顺便提及
Amazon Mechanical Turk,MTurk:亚马逊土耳其机器人,亚马逊劳务众包平台
References
https://medium.com/@jonathan_hui/real-time-object-detection-with-yolo-yolov2-28b1b93e2088
https://github.com/experiencor/keras-yolo3
https://towardsdatascience.com/yolo-v3-object-detection-53fb7d3bfe6b