YOLO算法思路分析
YOLO如何进行物体检测
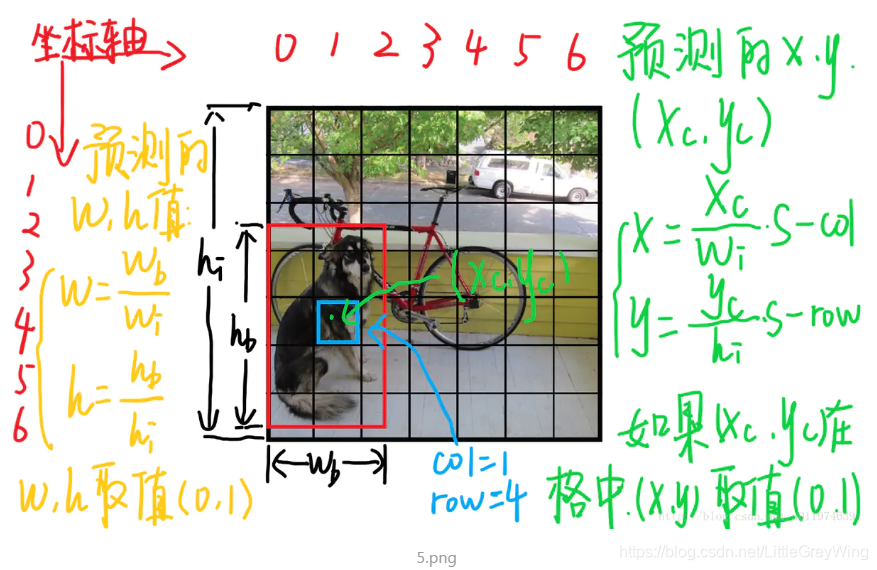
1.总体流程 如下图,先将输个图像分为S*S窗格(grid cell),每个窗格用来检测一个物体,这里说的检测一个物体是说中心落在该窗格的物体。每个grid cell 预测两个bounding box(实际上是B个,这里B=2),这里说的bounding box 又是指以该窗向外延伸的bounding box,每一个box有5个参数来表示: x,y,w,h,confidence,其中x,y,w,h用来表示box的位置,confidence则是表示其置信度。并且如果检测到该box内有物体,还要对其进行各类(类别数设为C)物体的概率进行预测。

2.bounding box
假设图片的宽和高分别为w_i,h_i
5个参数的理解:
-
x,y: x,y是物体中心在该grid cell的相对坐标,具体计算如下:
如上图中蓝色为我们选择的框他在整个图中的坐标为(1,4)(从0开始算),假设物体中心点的绝对坐标是(x_c,y_c),那么x = (x_c/w_i) * S - 1 y = (y_c/h_i)S - 4 ,其实效果就是先把绝对坐标对应到切分成SS块之后重新定义后的坐标系上的坐标,这样以后再减去grid cell的左上角顶点坐标这样就把x,y对应到以grid cell左上角为原点的一个坐标系中,grid cell的面积为1,所以x,y的取值都在[0,1]中 -
w,h:注意w和h不是grid cell的长宽,因为他们的大小已经在均分之后被确定了,w和h是指将窗格扩展成为不同bbox之后各个bbox的长和宽,而为了将其也进行坐标转换,直接求对应实际长度占原图的比例即可。w = w_b/w_i, h = h_b/h_i 其中w_b代表bbox的宽度,w_i是原图的宽度
-
confidence:
该置信度由两项相乘所得,第一是窗格内是否有物体,第二是bbox和ground truth的交并比:
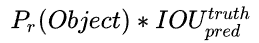
如果格子内有物体那么第一项为1否则为0,后一项则是一般的交并比 -
类别的条件概率
它的表达式为: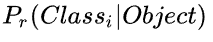
即在窗格内有物体时,它是某一类别的概率,在测试的时候就需要加上这样的概率,结果变成:
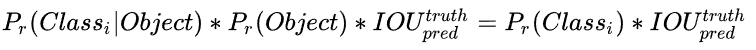
于是最终就变成了下面这样:
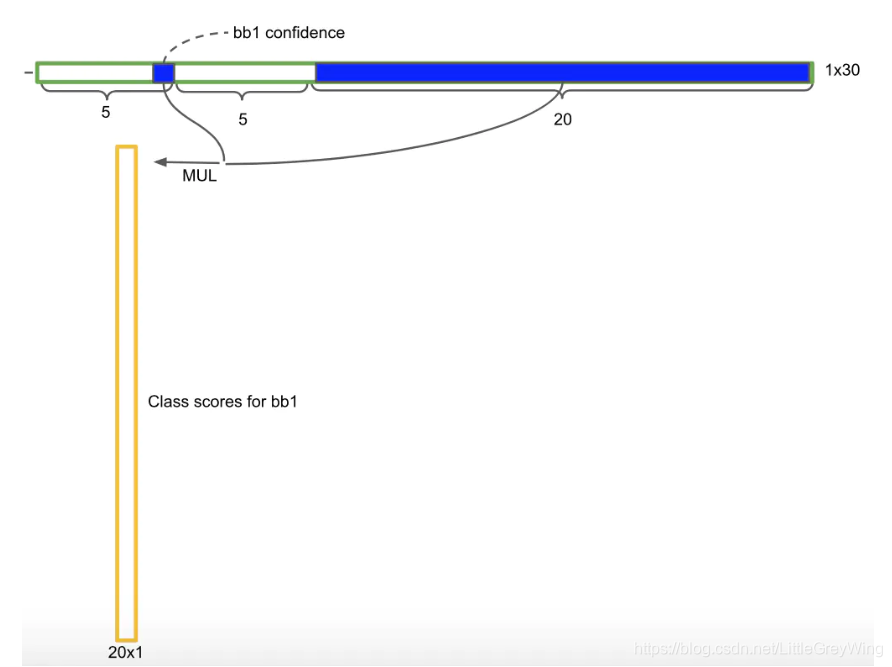
前5项为一个bbox的相关参数,其中第五个是置信度,他本来是由一个bbox的值和一个是否有物体的概率相乘,那么此时如果把它再和右边的20种类的条件概率分别相乘,那就得到了最终的概率(MUL表示相乘操作)
3.网络架构
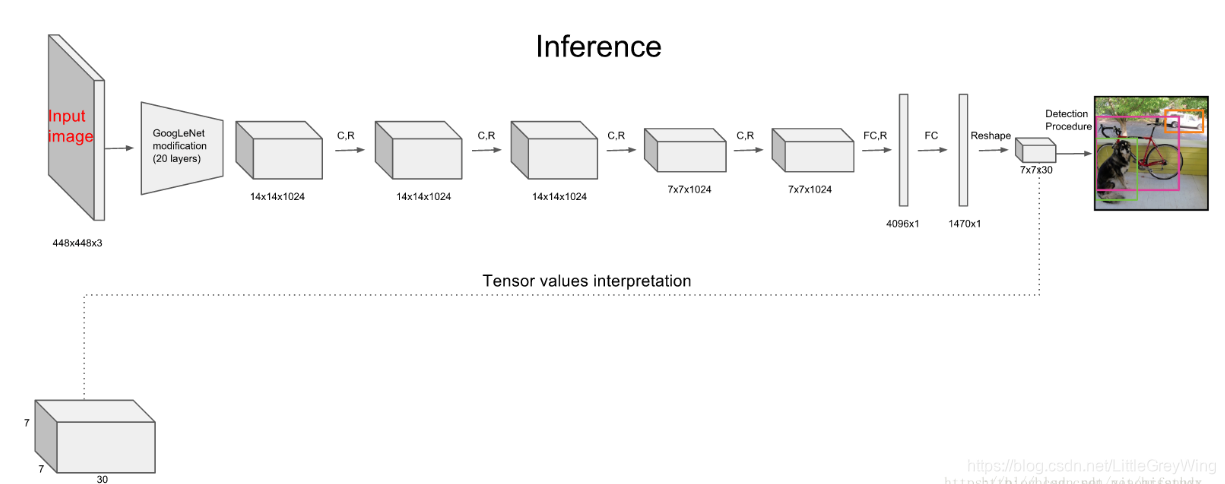
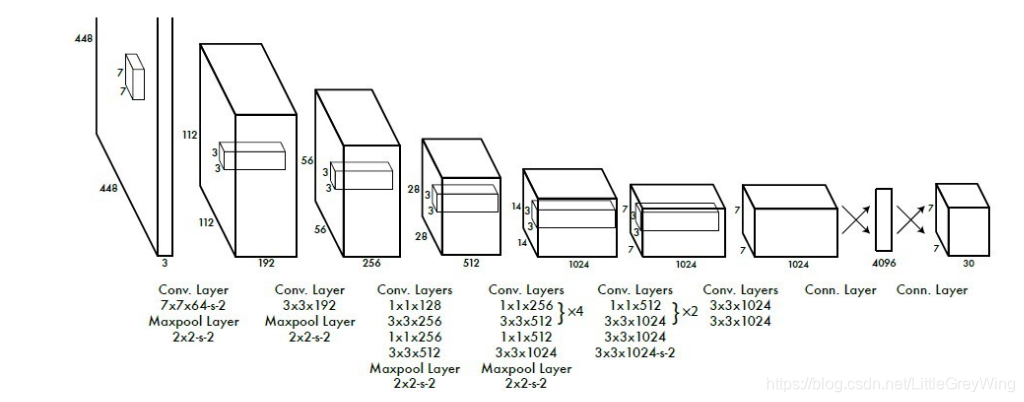
YOLO系统包括24个卷积层和2个全连接层,卷积层提取特征,全连接层预测图像位置及物体类别的概率,网络模型如下:

4.损失函数
损失函数的图示大致如下:
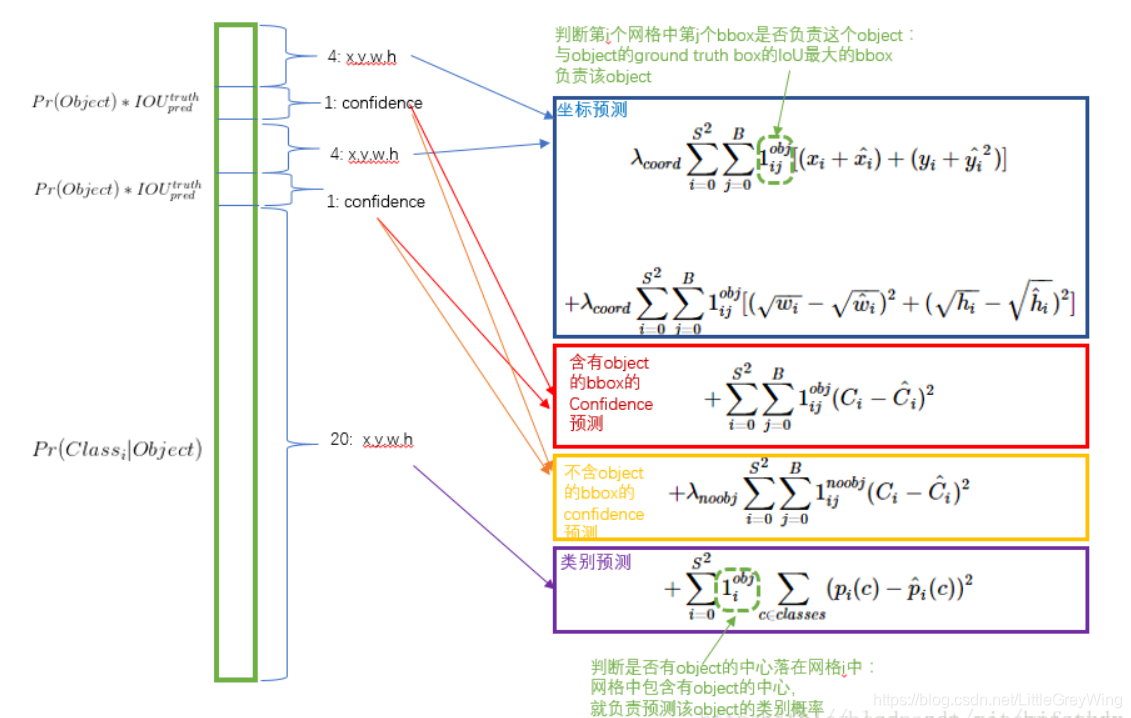
(博主从网络中获得上图,不过其有一处错误在于第一个式子关于x和y的损失应该是减号)
简单来说就是把损失分成了如上图的四块,第一块是bbox回归的部分,其中w和h的回归是为了缩小对小物体回归时的误差影响(但这样做了仍不是太好),第二块是对窗格内有物体时的置信度的loss,只有当有物体时这一项才不为0,第三块是对窗格内没有物体时的置信度的loss计算,只有当这一块内没有物体时这一项才不为0,而C则是预测的置信度,减去的是实际的置信度,而实际的置信度则在有物体时为1,没物体时为0。最后一块就是一个分类的loss。前面的一些系数则是调整各类loss的权重,例如大部分框其实都是背景,如果有物体的置信度loss和没物体的置信度loss有了相同的权重显然不合适。
YOLOv2的改进
-
在每个卷积层之后添加BN层,这样有助于规范化模型
-
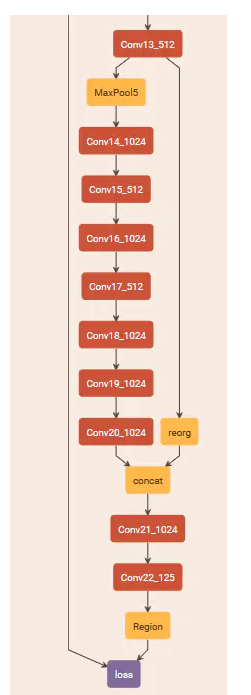
移除了全连接层,这样不会有后边的SS(B5+C)的结构而是在77channels的位置停下,而为了后面的计算方便,其又抛弃了前面的一个池化层,这样使得到这一步是1313channels的情况,并从此开始借鉴Faster RCNN 的RPN网络,开始选取anchor,并且利用anchor来进行边界框的预测,于是YOLOv2使得可以预测的范围从原来的772变到了1313*num_anchors个,这样就使得可以预测的框大幅增加。另外,之前的全连接层会丢失一部分空间信息,而在利用了anchor后会更加容易学习。
-
聚类算法确定anchor比例
在Faster RCNN中,anchor的比例是手动设定的,如果提前设定的anchor能够更加合理那么模型可以更容易学习。YOLOv2于是采用了k-means聚类算法对训练集中的边框进行了聚类分析,因为聚类的目的是让预测框和ground truth的IOU更好,所以聚类分析时选用的box和聚类中心的box之间的IOU值作为我们的距离指标:
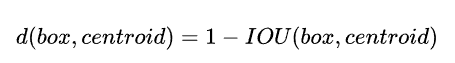
这样在聚类之后进行分析就可以选取更加合适的anchor比例 -
新的卷积网络模型:Darknet-19,有19个卷积层和5个maxpooling层,这里不多阐述
-
Direct location prediction
由于采用了anchor的策略,那么偏移量可以由Faster RCNN的论文可得出来:
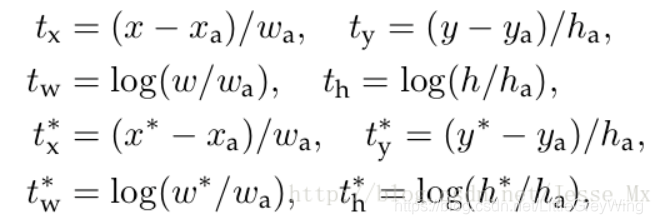
这里我们只看前两行就可以了,这里的x,w等参数都是实际的坐标和实际的长度,那么反推回去可以根据差值得到预测值的x,y:
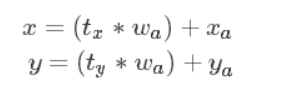
这样会发现假如t_x等于1那么预测框就是当前anchor往右平移整个anchor的宽度之后得到的另一个框,于是根据t_x的不同取值,预测框会在很大程度上出现问题,诸如超出图像边界的问题。为此,YOLOv2采取了不同的措施:
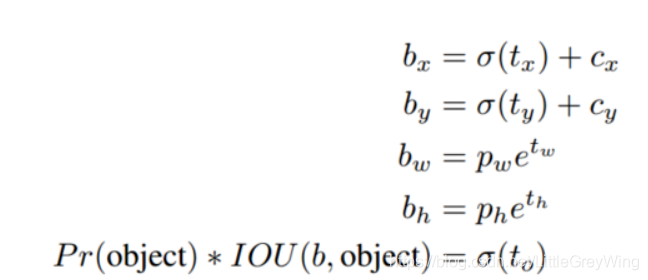
其中c_x和c_y为当前grid cell左上角的相对坐标,而每个cell的尺度作为1,p_w和p_h则是一个相对的长宽,这和YOLOv1中的思路完全一致,b则是相应的预测值。t是相应的差值,他的取值由之前提到过的置信度乘以概率取得。

这样将预测框限制到了一定位置,使得其更加可靠且可控 -
细粒度特征
个人理解就是把浅层网络特征和深层网络特征相连接,从而可以提取更加全面的特征,该方法把2626512的特征图转换为13132048的特征图,这样就可以和之后的13131024的特征图相连接,在这个13133072的特征图上进行后续的预测,他有更好的细粒度特征 -
多尺度训练
之前的YOLO anchor box LO是448448的固定输入,现在加入了anchor舍弃了一个pooling层会变成416416并且没有全连接层只有卷积层和池化层那么就可以动态调整(检测任意大小的图片),为了使它更具有鲁棒性,那么就可以动态调整。于是作者在每经过10次训练(10个epoch后)就随机选择新的图片尺寸,YOLO使用的降采样参数为32,那么就用32的倍数进行池化,出现了诸如320,352,…608的图片,最终最小的尺寸是320320,最大的是608608,接着就按照输入尺寸调整网络进行训练。这意味着同一个网络可以预测不同尺寸的图片,在小尺寸图片上YOLOv2运行更快,速度和精度都比较满意。 -
损失函数
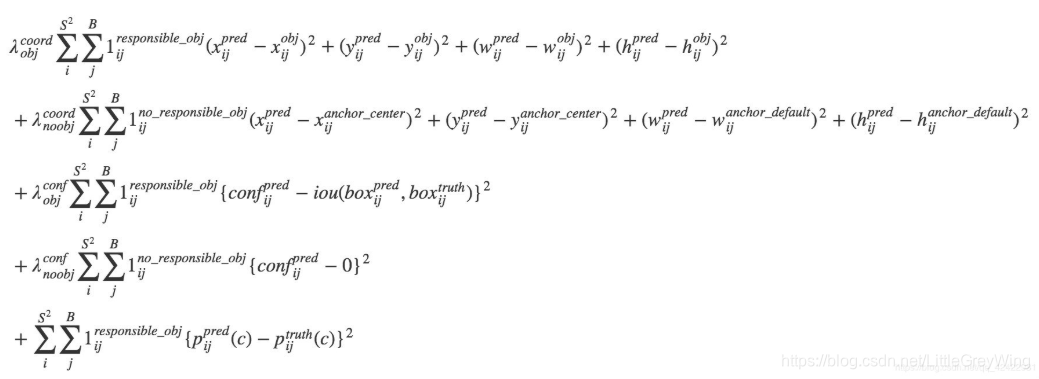
YOLOv3的改进
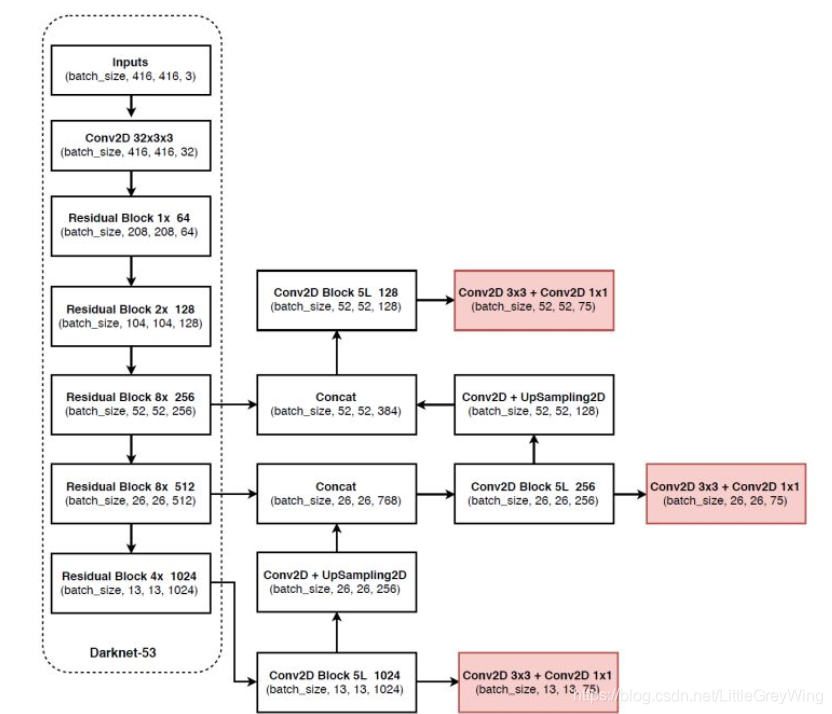
- 使用残差模型,包含53个卷积层因此称为Darknet-53
- 另外是采用FPN架构来实现多尺度检测
-
- 损失函数
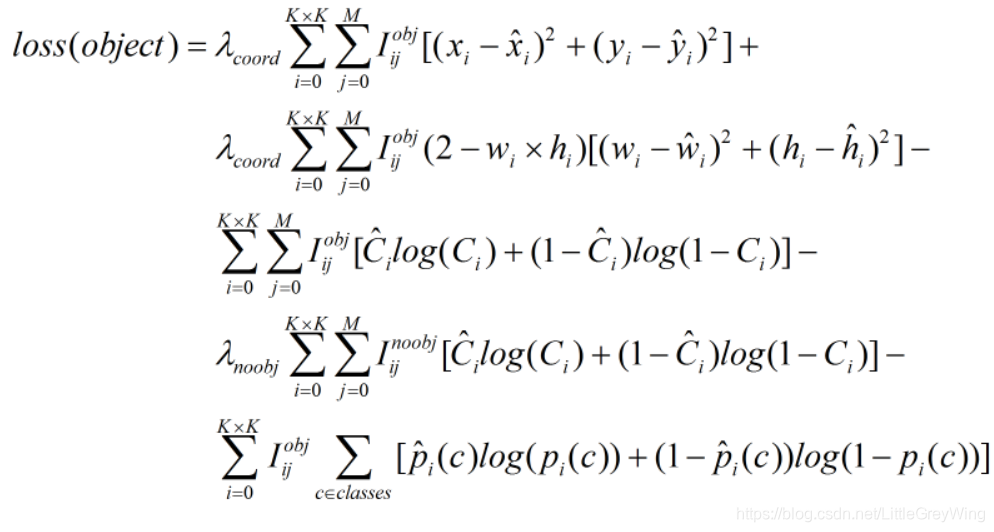
YOLOv3的损失函数采用了多个逻辑回归,softmax不适合多标签分类,而用多个独立的 下降 准确率logistic分类器
资料参考:
YOLO系列函数损失函数理解
YOLO文章详细解读
目标检测算法之YOLOv2损失函数详解
yolov1论文理解与学习
Face Paper: YOLOv2论文详解
目标检测|YOLOv2原理与实现(附YOLOv3)
如有错误之处还请大家指出~