Real-time Object Detection with YOLO, YOLOv2 and now YOLOv3 - YOLO
https://medium.com/@jonathan_hui/real-time-object-detection-with-yolo-yolov2-28b1b93e2088
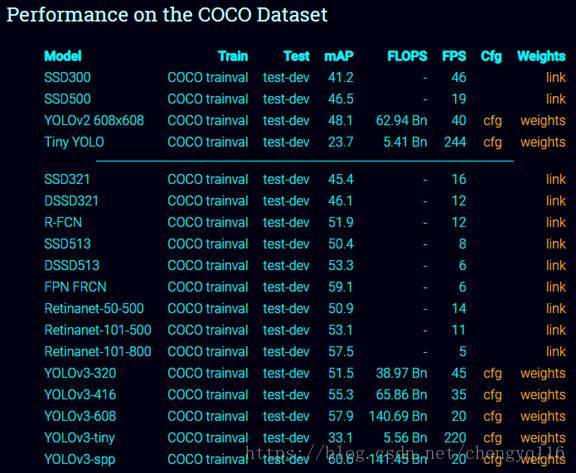
You only look once (YOLO) is an object detection system targeted for real-time processing. We will introduce YOLO, YOLOv2 and YOLO9000 in this article. For those only interested in YOLOv3, please forward to the bottom of the article. Here is the accuracy and speed comparison provided by the YOLO web site.
https://pjreddie.com/darknet/yolo/
https://medium.com/@jonathan_hui/real-time-object-detection-with-yolo-yolov2-28b1b93e2088
A demonstration from the YOLOv2.
https://www.youtube.com/watch?v=VOC3huqHrss&feature=youtu.be
Let’s start with our own testing image below.

The objects detected by YOLO:

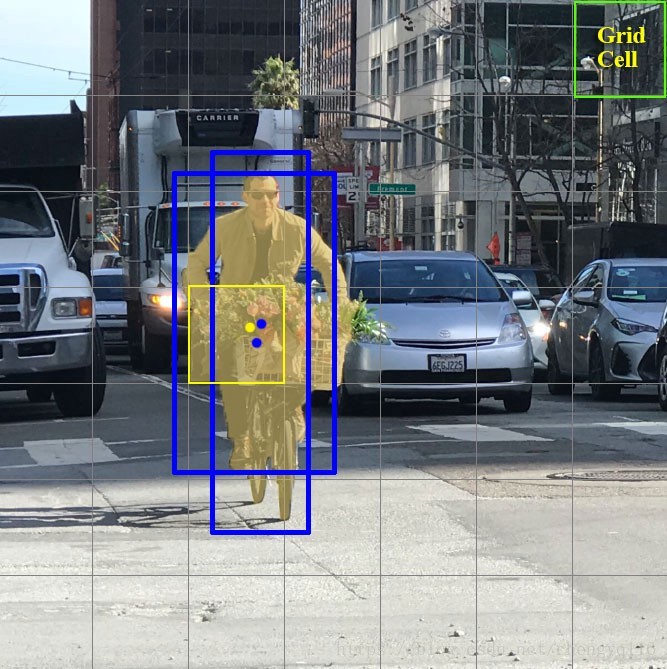
Grid cell
网格单元
For our discussion, we crop our original photo. YOLO divides the input image into an S × S grid. Each grid cell predicts only one object. For example, the yellow grid cell below tries to predict the “person” object whose center (the blue dot) falls inside the grid cell.

Each grid cell predicts a fixed number of boundary boxes. In this example, the yellow grid cell makes two boundary box predictions (blue boxes) to locate where the person is.
However, the one-object rule limits how close detected objects can be. For that, YOLO does have some limitations on how close objects can be. For the picture below, there are 9 Santas in the lower left corner but YOLO can detect 5 only.

For each grid cell,
- it predicts B boundary boxes and each box has one box confidence score,
- it detects one object only regardless of the number of boxes B,
- it predicts C conditional class probabilities (one per class for the likeliness of the object class).
To evaluate PASCAL VOC, YOLO uses 7 × 7 grids (S × S), 2 boundary boxes (B) and 20 classes (C).
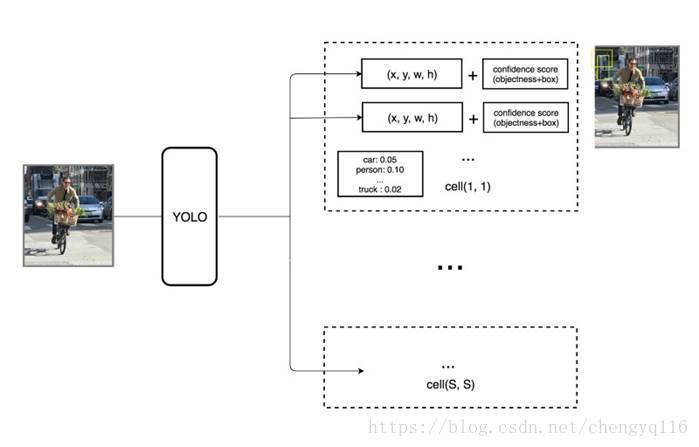
Let’s get into more details. Each boundary box contains 5 elements: (x, y, w, h) and a box confidence score. The confidence score reflects how likely the box contains an object (objectness) and how accurate is the boundary box. We normalize the bounding box width w and height h by the image width and height. x and y are offsets to the corresponding cell. Hence, x, y, w and h are all between 0 and 1. Each cell has 20 conditional class probabilities. The conditional class probability is the probability that the detected object belongs to a particular class (one probability per category for each cell). So, YOLO’s prediction has a shape of (S, S, B × 5 + C) = (7, 7, 2 × 5 + 20) = (7, 7, 30).
The major concept of YOLO is to build a CNN network to predict a (7, 7, 30) tensor. It uses a CNN network to reduce the spatial dimension to 7 × 7 with 1024 output channels at each location. YOLO performs a linear regression using two fully connected layers to make 7 × 7 × 2 boundary box predictions (the middle picture below). To make a final prediction, we keep those with high box confidence scores (greater than 0.25) as our final predictions (the right picture).

The class confidence score for each prediction box is computed as:
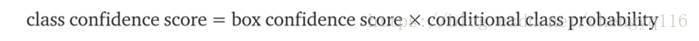
It measures the confidence on both the classification and the localization (where an object is located).
We may mix up those scoring and probability terms easily. Here are the mathematical definitions for your future reference.

Network design
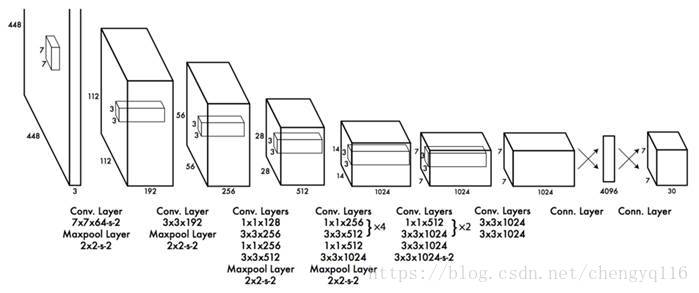
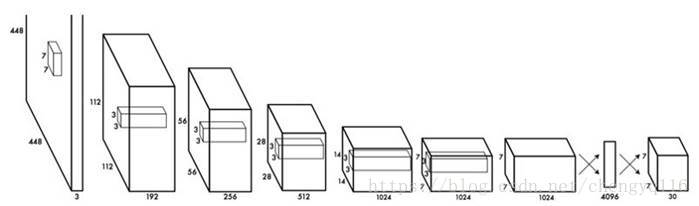
YOLO has 24 convolutional layers followed by 2 fully connected layers (FC). Some convolution layers use 1 × 1 reduction layers alternatively to reduce the depth of the features maps. For the last convolution layer, it outputs a tensor with shape (7, 7, 1024). The tensor is then flattened. Using 2 fully connected layers as a form of linear regression, it outputs 7 × 7 × 30 parameters and then reshapes to (7, 7, 30), i.e. 2 boundary box predictions per location.
A faster but less accurate version of YOLO, called Fast YOLO, uses only 9 convolutional layers with shallower feature maps.
Loss function
YOLO predicts multiple bounding boxes per grid cell. To compute the loss for the true positive, we only want one of them to be responsible for the object. For this purpose, we select the one with the highest IoU (intersection over union) with the ground truth. This strategy leads to specialization among the bounding box predictions. Each prediction gets better at predicting certain sizes and aspect ratios.
YOLO uses sum-squared error between the predictions and the ground truth to calculate loss. The loss function composes of:
- the classification loss.
- the localization loss (errors between the predicted boundary box and the ground truth).
- the confidence loss (the objectness of the box).
Classification loss
If an object is detected, the classification loss at each cell is the squared error of the class conditional probabilities for each class:

Localization loss
The localization loss measures the errors in the predicted boundary box locations and sizes. We only count the box responsible for detecting the object.

We do not want to weight absolute errors in large boxes and small boxes equally. i.e. a 2-pixel error in a large box is the same for a small box. To partially address this, YOLO predicts the square root of the bounding box width and height instead of the width and height. In addition, to put more emphasis on the boundary box accuracy, we multiply the loss by λcoord (default: 5).
Confidence loss
If an object is detected in the box, the confidence loss (measuring the objectness of the box) is:

If an object is not detected in the box, the confidence loss is:

Most boxes do not contain any objects. This causes a class imbalance problem, i.e. we train the model to detect background more frequently than detecting objects. To remedy this, we weight this loss down by a factor λnoobj (default: 0.5).
Loss
The final loss adds localization, confidence and classification losses together.
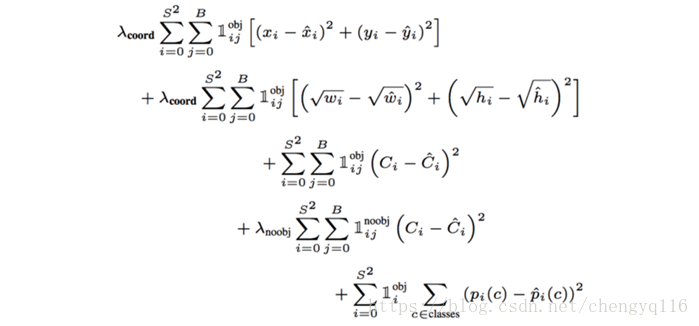
Inference: Non-maximal suppression
YOLO can make duplicate detections for the same object. To fix this, YOLO applies non-maximal suppression to remove duplications with lower confidence. Non-maximal suppression adds 2- 3% in mAP.
Here is one of the possible non-maximal suppression implementation:
1. Sort the predictions by the confidence scores.
2. Start from the top scores, ignore any current prediction if we find any previous predictions that have the same class and IoU > 0.5 with the current prediction.
3. Repeat step 2 until all predictions are checked.
Benefits of YOLO
- Fast. Good for real-time processing.
- Predictions (object locations and classes) are made from one single network. Can be trained end-to-end to improve accuracy.
- YOLO is more generalized. It outperforms other methods when generalizing from natural images to other domains like artwork.
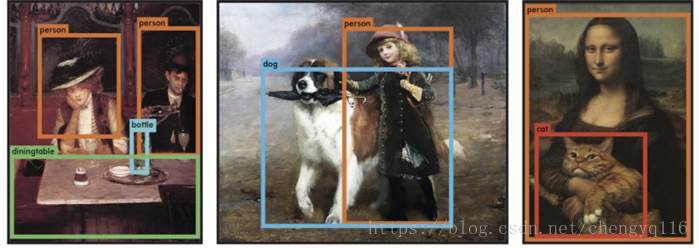
Region proposal methods limit the classifier to the specific region. YOLO accesses to the whole image in predicting boundaries. With the additional context, YOLO demonstrates fewer false positives in background areas.
YOLO detects one object per grid cell. It enforces spatial diversity in making predictions.
Wordbook
grid cell:网格单元
Santa Claus [ˈsæntə klɔ:z]:圣诞老人
linear regression:线性回归
square root:平方根,二次根
References
https://medium.com/@jonathan_hui/real-time-object-detection-with-yolo-yolov2-28b1b93e2088