前言:
{
在写了YOLO的笔记(https://mp.csdn.net/postedit/82634004)后,我又看到了它的几个更新,目前更新到了YOLOv3。我就来看看都在哪些方面做了改进。
文章地址:https://arxiv.org/pdf/1612.08242.pdf(YOLOv2)
}
正文:
{
在第一节,作者引入了YOLO9000,一个已经在多个数据集上训练好的,能检测超过9000种物体的分类器。这个分类器就是训练好的YOLOv2。
第二节,第三节和第四节介绍了新模型好在哪里。
正如上次YOLO笔记(https://mp.csdn.net/postedit/82634004)里的分析,YOLO容易出现定位误差。YOLOv2有了以下改动,表2:

在YOLOv2中,输入图像的高和宽都翻了倍;
全连接层被去除了;
原来是直接输出box的相关属性,现在加入了anchor box,输出与anchor box关联的属性;
在数据集上进行k-means聚类以选择anchor box,聚类中使用的距离为
网络输出的框属性被改为:
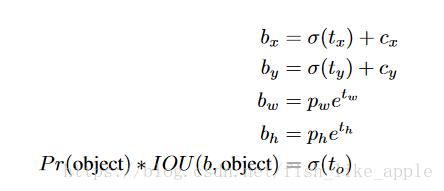

由于网络上全是卷积结构,输入尺寸可变,训练也是用不同尺寸的输入,不同图片尺寸的识别的效果为表3:

并且添加了新的结构,和残差网络(ResNet)里的Identity Mappings类似,在网络的最后出现了跨级连接。
特征提取网络被换成了一个新的网络-Darknet-19,其结构如表6:

这个网络是独立的特征提取网络,速度不错,可以用于分类,并且作者还给出了相应的训练方法(用于分类和用于检测)。
值得一提的是,YOLOv2可以使用分类的训练数据和面部检测的训练数据。当使用分类的训练数据进行训练时,反向传播只涉及其一部分。
模型的类别输出被改变了。在ImageNet上,输出如图5中的WordTree1k:

可以看到,输出不再是one-hot向量,输出的类型也不再是单独的一个类。通过这种方法,多个标签之间产生了练习,数据集也可以被联合起来训练一个模型。图6介绍了使用Wordnet把COCO和ImageNet的所有标签类型融合后结果:

可以通过这种数据组合来训练一个通用的模型(YOLO9000就是这样训练的)。
表7是YOLO9000在ImageNet上的部分检测表现:

可以看到,对器件的识别效果不好。作者也解释到,在训练YOLO9000时只使用了ImageNet的分类数据,并且COCO中也没有这些器件。
在第五节,作者做了总结,并且表明接下来打算改进数据融合的策略和方法。
}
结语:
{
不光是目标检测,似乎Darknet的分类效果也还行(在速度得到保证的情况下)。新的标签融合方法也可以用于迁移学习。
由于本人能力有限,可能有理解不到位的情况,欢迎指点。
}