原文:http://cs229.stanford.edu/notes/cs229-notes1.pdf
1.有监督的学习
对选取的特征(feature),使用x(i)来代表,这是输入(input)。输出(output)用y(i)表示,这是我们尝试预测的部分。数对(x,y)就是训练集。我们的目标是找到一个函数h:x->y,这个函数能够很好的通过x预测出y,函数h称为假设(hypothesis).如图1所示。

图1
如果我们预测目标是一个连续的,这种学习问题叫做回归问题,如果预测目标是离散的,我们叫它分类问题。
1.1 线性回归
首先决定选取哪些特征(x1,x2,x3...),最初假设预测函数是一个线性的h(x)=θ0+θ1x1+θ2x2+...,这里θi是权重因子。
简化的写法(θ和x都是向量):
然后,给出训练集来确定权重。方式是让用h算出的数据尽量接近训练集中的y。
定义一个描述两者接近度的函数,叫做代价/损失函数(cost function),形式上有类似最小二乘的部分: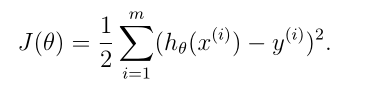
1.1.1 LMS算法
我们的目标是找到合适的θ,以让J(θ)最小化。

α称为学习速率。这是一个非常自然的算法,它重复地向J的最陡下降方向迈出了一步,假设只有一个测试用例(x,y),带入求导J(θ)后得到,详细求导过程见附1。
 这个式子就是LMS(Least Mean squares)规则,从式子中可以看出,θ更新的大小和误差项(y-h(x))成正比。当测试集有多个测试用例时,只需变成如下方式:
这个式子就是LMS(Least Mean squares)规则,从式子中可以看出,θ更新的大小和误差项(y-h(x))成正比。当测试集有多个测试用例时,只需变成如下方式:
重复直至收敛{
 }
}
上式是批量计算梯度下降的方法(batch gradient descent),也可以用另一种方法替代:

这种算法中,我们每一次使用训练测试用例时,我们只根据该测试用例的误差梯度更新参数,这种方式叫做随机梯度下降法(stochastic gradient descent)。与批计算梯度下降法相比,批计算需要读入所有的测试用例才能进行一次更新操作,如果测试用例数量很大会负担大,而随机梯度下降法的更新是立即开始的,通常得到接近最小的θ比批计算快,但要注意,它肯永远不会收敛到最小值,而是在最小值附近振荡,但在实践中,大多数最接近最小值的值都能很好的逼近真正的最小值。所以,当训练集较大时,常选用随机梯度下降法。
1.1.2 正规方程(the normal equations)
1.1.1梯度下降是一种方法,也可以不用这种迭代的方式,而采用这一节的方法:显式的计算J对每个θj的偏导数,求出偏导为零的点。
先要了解矩阵导数的概念,参见博客https://blog.csdn.net/blackyuanc/article/details/69849023
最终得到的正规方程(normal equations): ,权重矩阵θ可以表示为
,权重矩阵θ可以表示为

在特征维度少的时候,使用正规方程的方法计算通常会比梯度下降方法快。
1.1.3 概率解释(Probabilistic interpretation)
当面临回归问题时,为什么线性回归,特别是为什么最小二乘损失函数J可能是一个合理的选择?在这一节中,我们将给出一组概率假设,在此假设下,极大似然估计和最小均方差是同解的,最小二乘回归是一种非常自然的算法。参见博客:https://blog.csdn.net/blackyuanc/article/details/70145981和博客https://blog.csdn.net/qq_31589695/article/details/79824919
1.1.4 局部加权线性回归(LWR,Local weighed linear regression)
在求解h时,存在欠拟合和过拟合的情况,因此选择特征对于算法的良好性能非常重要,在这一节中,LWR的基本假设是测试集的数据十分充足,使得对于特征的选择不那么重要。
具体步骤参见博客:https://blog.csdn.net/blackyuanc/article/details/70162067
局部加权线性回归模型只关注于预测点附近的点(即局部的含义),而不考虑其他远离预测点的样本点。
LWR是一个非参数的算法,用这一方法做预测时,需要保留整个的训练数据集,每次预测得到不同的参数,即参数是不固定的。而参数化算法需要拟合的参数是固定有限的,当拟合完成后,训练集数据也无需保留。
1.2 分类和逻辑回归(classfication and logistic regression)
分类问题类似回归问题,只不过现在我们要预测的y是少量离散值,首先关注二值化分类问题,这里要判断的y只有两个取值,0和1
1.2.1 逻辑回归
忽略y是离散值,我们可以尝试使用之前的线性回归方法去给定x预测y,但是这种方式给出来的表现不佳,因为y必然是两个值中的一个,为了满足这个,选择下面的hθ(x)
 其中,
其中,

g(z)也叫做sigmoid function或者逻辑函数(logistic function),函数图像如下图所示,值介于0和1之间,而且它的导数易于计算g'(z)=g(z)(1-g(z))。

经最大似然法拟合参数以及一系列求导变化后,数学过程参见https://blog.csdn.net/blackyuanc/article/details/70167912,得到

这一更新方法和LMS相似,区别只在这里的hθ(x)是一个θTx(i)的非线性函数。
附解1:求导过程
