(学习笔记)吴恩达深度学习课程第一课—神经网络与深度学习
视频链接:https://www.bilibili.com/video/BV164411m79z?p=8&spm_id_from=pageDriver
第一周 深度学习概述
一、什么是神经网络
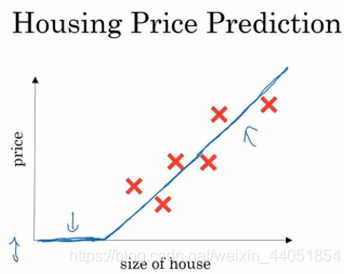
在房价预测问题中,我们根据训练数据训练出一条如上图中的曲线,来尽可能拟合这些数据,然后就可以该曲线来根据房屋大小预测房价。这个拟合房价的曲线函数,就可以看成一个非常简单的神经网络。
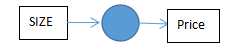
size作为输入,price是输出,而中间的小圆就是一个独立的神经元,该神经元完成的任务就是输入size,完成线性计算,取不小于0的值,最后得到输出的预测price。而复杂一点的神经网络,就是把这样的单个神经元堆叠起来形成的。
(上面的曲线所表示的函数,起始为0,后面转变为一条直线,这样的函数被称作ReLU函数)
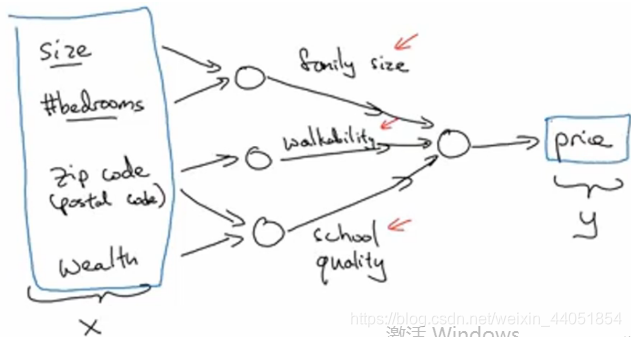
上图的每一个圆可能都表示一个ReLU函数,或是其他非线性的函数(基于房屋面积和卧室数量来估计家庭人口,基于邮编可以估计步行化程度,基于邮编也可以估计附近学校的质量),事实上房价和人们关注什么,有很大关系。在该例中,家庭人口、步行化程度、学校质量都可以帮助我们预测房价,这就是一个使用多神经元的神经网络。
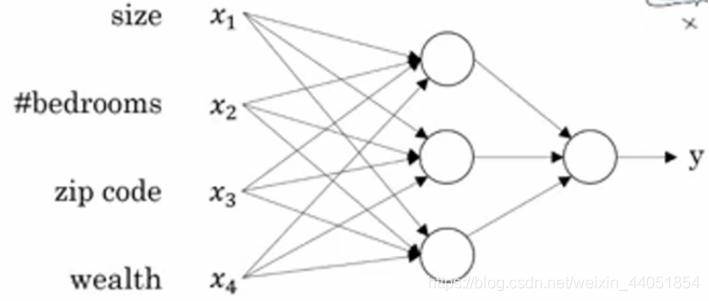
在已知这些输入的特征的前提下,神经网络的工作就是预测对应的房价。而图中的圈圈也被称为神经网络的隐藏单元,负责计算输入进来的数据,最终得到预测房价y。
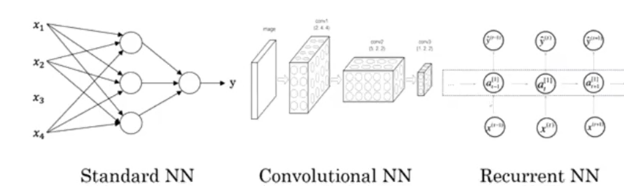
二、用神经网络进行监督学习
监督学习,需要给机器一组含有标签的训练集。所谓含有标签,就是告诉机器,这个输入属于哪个类,机器通过在训练集中训练,最终得到一个可以用来预测的函数,而无监督学习则没有这个标签。以下为神经网络进行监督学习的应用列举。
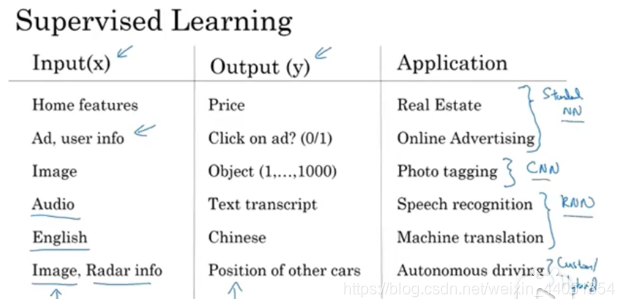
下图中从左到右依次是标准的神经网络,卷积神经网络(CNN)和循环神经网络(RNN)。CNN主要应用于图像处理,而RNN主要应用于处理一维序列数据。
机器学习也被应用于结构化数据和非结构化数据。结构化数据是数据的数据库,例如在房价预测中,你可能有一个数据库或者数据列,告诉你房间大小、卧室数量…这就是结构化数据,每个特征都有着清晰的定义。与之相反的就是非结构化数据,比如音频、图像,相比于结构化数据,计算机其实很难理解非结构化数据,而通过深度学习、神经网络,现在的计算机能够更好地理解和解释非结构化数据,语音识别、图像识别、自然语言文字处理等技术应运而生。
第二周 神经网络基础
一、二分分类
二分类问题例如,输入一张图片,判断是不是猫,是则输出1,不是就输出0。

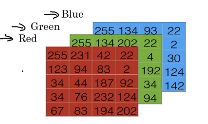
计算机是如何表达一张图片的?
计算机保存一张图片,需要保存三个独立矩阵,分别对应**红(R)、绿(G)、蓝(B)**三个颜色通道,例如,如果输入图片是64×64像素的(长宽各有64个像素),就有三个64×64的矩阵,把这三个矩阵中的所有像素亮度值放进一个特征向量X中,就可以用X来表示这一张图片:
x=(255,231,…,255,134,…,255,134,…)T ,如果图片是64×64的,那么向量X的总维度就是12288(即64×64×3),一般用nx或n来表示输入的特征向量的维度。
在二分类问题中,目标是训练出一个分类器,它以图片的特征向量x作为输入,预测输出的结果y是1还是0。
以下是课程中需要用到的一些符号:
(x,y):表示一个单独的样本,例如x是一个图片的特征向量,y是1或0;
m:表示训练集由m个训练样本构成;
(x(1),y(1)):表示样本1的输入和输出,依次类推;
X:可以用来表示训练集中所有x组成的矩阵,X=(x(1),x(2),…,x(m)),该矩阵有nx行m列;
Y:可以用来表示所有y组成的矩阵,Y=(y(1),y(2),…,y(m)),该矩阵有1行m列。
二、Logistic回归
Logistic回归算法,是一种广义的线性回归分析模型,在监督学习问题中用于预测某事发生的概率。在上述的二分类问题中,输入一张猫图,用x表示,我们可得到输出y^ =P(y=1|x),我们希望y^ 告诉我们这是一张猫图的概率:
- x是一个nx维向量;
- Logistic回归的参数w也是一个nx维的向量,而b是一个实数;
- 所以,已知x、w、b,我们可以使用线性方程计算出y^ =wTx+b。
以上是我们做线性回归的常规做法,但这并不是一个很好的二分类算法,因为我们希望y^ 是y=1的概率,所以y^ 应该介于0和1之间,但是这很难实现,因为wTx+b的值可能比1大,也可能是负值,这样的概率是没有意义的 ,所以,在logistic回归中,我们对wTx+b这个量使用sigmoid函数,即:
y^ =σ(wTx+b)
sigmoid函数就是下图这样从0到1的平滑曲线:
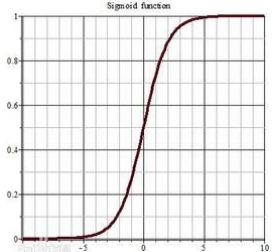
我们用z来表示(wTx+b),上图的横坐标表示的就是z,则:y^ =σ(z),事实上σ(z)=1/(1+e-z),可观察得到,如果z很大,σ的值是很接近1的,与上图的表达是一致的。
通过sigmoid函数的处理,z值是个远大于1的数时,得到的概率就接近1,z值是个负数时,得到的概率就接近0,解决了上文的概率无意义的问题。