文章目录
概述
supervised Learning

- 这个过程被认为是监督的,一个算法从训练数据中学习,就像是一个老师在监督学生的学习过程一样。
- Classification和regreesion就是监督学习任务
回归与分类

- 如果要输出的结果是类别,categorical的,就是分类
- 如果要预测的是numeric,是连续的数据,就叫回归
举一个例子:

- 假设我们有一组数据,温度和湿度
- 我们作出假设:温度和湿度是有一定的关系的(这里之所以要做出假设,是因为回归拟合不能确定因果关系,可能数值上有关系,但是实际并无因果关系)
- 我们可以得到一个线性模型:

这个模型可以从training data中得到一个最好的w1,w2的参数值。然后我们可以得到一个关于temperature的拟合值,就是用w1,w2和humidity计算出来的。
错误率error rate

- 然后我们用计算的拟合值和真实值进行比较,计算出error rate。
- 上面用到的计算error rate的方法是SSE,错误平方的和。有很多方法这只是一种方法。
整体流程

N-fold Cross-validation

- 把数据随机分成N组,也就是N fold。
- 其中1组作为testing然后剩下的N-1作为training
- 然后比较N次的error rate(上面我们已经说过了),取平均值,然后最终得到overall error rate
小结
训练数据,得到模型,然后得到拟合值,然后根据n-fold cross-validation得到一个overall error rate
线性/非线性模型
概述
- “All models are wrong, but some are useful” [George Box]
- 数据挖掘中的模型建立,都是数据驱动的任务 data-driven
线性归回的基本模型:

- 这里我们留下了一个,**如何从training data中得到W的值,也就是w1,w2,w3…vector of model parameters.**的问题。
- 其实先行回归的本质,就是取探讨w的取值,怎么取值才能是的error rate最小
有的时候,线性模型不能解决所有问题:
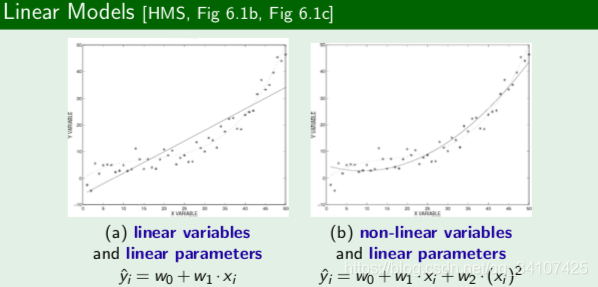
线性模型也可以是非线形模型,我们只有把x全部都平方,把 堪称一个新的变量x2就发现这还是个线性模型
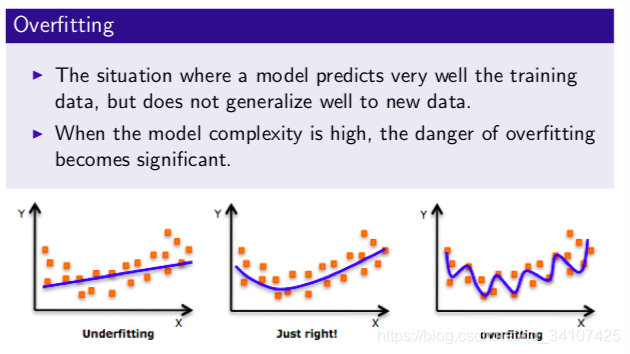
过拟合overfitting
mean of squared errors(MSE)
-
这是一个比较常用的error rate

-
这里也说了,选择W使得S(w)最小
-
我们叫S(w)为object function,通过object function计算得到error rate
如何计算w
之前我们知道了,回归的本质就是通过计算w来最小化S(w)。如何计算w呢?

Gradient 梯度下降

简单的说,就是先对w进行初始化,设置为0或者是一个随机数,然后计算error rate,然后根据:
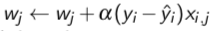
不断更新w,直到收敛convergence:

这一次的w和上一次的w的差值小于一个设置的值。
上面公式中的
称之为learning rate,学习率
这里分成两种类型的梯度下降:
- 计算是否收敛是在计算完全部的training data的error rate之后的,所以称之为batch or off-line gradient descent。这种也是multi-pass method 因为每一个训练数据可能被考虑不止一次。
- 另外一种是single-scan or on-line algorithm。 每次计算完一个训练数据,就会判断是否收敛,达到停止回归的条件。也称为stochastic gradient descent
neural networks
hyperplane 超平面
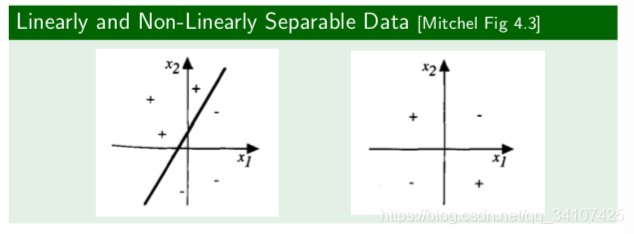
图一可以找到一条件分开+和-,但是图二就不行了。神经网络可以通过产生一个超平面,让图二中的+和-可以被一条线分开,一种我们不太好想象的平面。
神经元
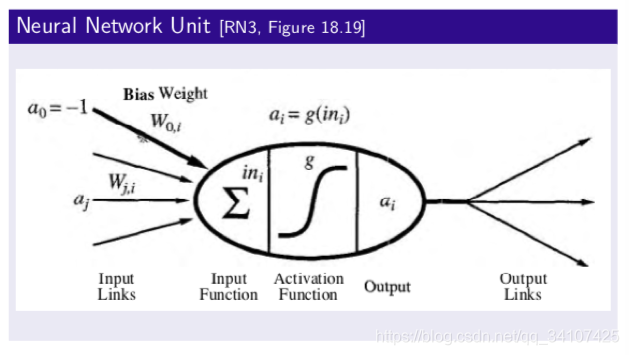
这是一个最简单的神经元,把所有的输入加和,然后通过一个activation function激活函数g,然后产生它的输出值。
这里有几个简单的激活函数图像:
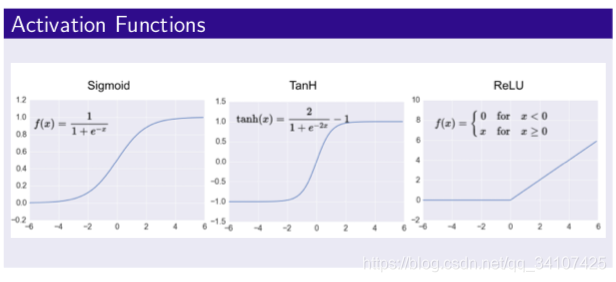
更多信息可以看这个:
深度学习激活函数 深入浅出 通俗易懂 教你如何选择合适的激活函数
Feed-forward network
- 前馈网络
- 连接只有一个方向,基本就是从input layer指向output层,不会出现训练。
- 如果只有一层,全部的inputs直接连接到outputs。我们称之为感知机perceptrons
- multilayer networks 除了inputs 和outputs 层,还有Hidden layers在输出和输入之间。
这里可以简单看一下神经网络的运行步骤:

我们可以看到其中有一步就是计算gradient,然后更新全部的weight在network中,这个怎么更新呢,使用Backpropagation反向传播更新。
Distribution and densities 分布与密度
-
univariate random variable 单随机变量
-
domain定义域吧估计。

-
probability distribution 是一个离散变量的概率分布
-
Cumulative distribution function 累计分布函数

-
probability density function 是一个连续变量的分布
-
joint distribution 是联合分布。
举个例子:
现在有两个变量X,Y,两个变量相互独立。

那他们的联合分布就是:

dependence and independence
- 两个随机变量之间是有或独立或不独立的关系的

用概率论来理解独立:

图中介绍了两种概念:
- independent
- conditionally independent:X,Y相互独立,但是X和Y都与Z不独立
介绍一下怎么用英文说概率:
Bayes theorem

贝叶斯其实就是,你有一个假设,然后有一堆数据,你现在有:
- 假设是真的概率(不基于任何的已知数据)
- 数据的概率
- 基于假设,数据的概率
然后我们通过:

计算出,基于数据,假设是真的概率。
觉得有用的加个关注呗~
但是讲道理我感觉没啥用,这是我数据挖掘课上记的笔记。。都是简单的基本知识
