Curriculum Learning
论文原文:Curriculum Learning
课程学习(Curriculum Learning)由Montreal大学的Bengio教授团队在2009年的ICML上提出,主要思想是模仿人类学习的特点,由简单到困难来学习课程(在机器学习里就是容易学习的样本和不容易学习的样本),这样容易使模型找到更好的局部最优,同时加快训练的速度。
Abstract
人类和动物在学习时学习材料按照由易到难的顺序呈现是学习效果会更好,在机器学习中课程学习的概念借鉴了这种思想。在非凸问题中,课程学习展现出了巨大的性能提升和很强的泛化能力。作者认为课程学习的策略能够加速收敛速率以及在非凸优化中找到更好的局部最优点(可以看成是continuation method)。
1. Introduction
介绍了课程学习的思想,并通过动物训练shaping的模式和循环网络学习语法的例子说明,学习要由易到难循序渐进。
Contributions:
- 作者通过有关视觉和语言的任务证明了很简单的多阶段课程学习的策略就能够实现泛化能力的提高和收敛速度的加快。
- 另外解释了课程学习为什么有这些优势。
- 实验表明课程学习的作用类似于某种正则项。
2. On the difficult optimization problem of training deep neural networks
在这一部分作者在深度神经网络中讨论课程学习策略对局部最优问题的处理。深度神经网络就具有层次的结构,使用多层级的抽象特征能够让系统根据数据自动推断出输入输出之间的映射关系,从而排除人工特征的设计。然而,训练深度结构的神经网络却很困难,一些学者的研究证明使用一些无监督预训练策略来确定监督训练的初始化参数可以帮助深度网络的训练得到更好的测试误差(泛化能力增强)。作者使用课程学习的策略来进行预训练,以便找到更好的局部最优以及提高收敛的速度。
3. A curriculum as a continuation method
介绍了Allgower和Georg的continuation method的思想,对于一个优化问题 ( 参数反映了优化问题难易程度),先优化一个较为平滑的目标 ,这个目标反映了问题整体的景象,然后逐渐增加 并且保持 是 的局部最优,最终 就是实际想要优化的问题。
课程学习就是这种思想,根据训练样本训练的难易程度,给不同难度的样本不同的权重,一开始给简单的样本最高权重,他们有着较高的概率,接着将较难训练的样本权重调高,最后样本权重统一化了,直接在目标训练集上训练。
下面介绍公式化这种思想的一种方法:
首先重新分配了在第 步( )训练时的样本分布 ,
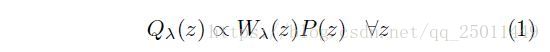
其中,
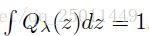
根据上面的描述有当 时,有
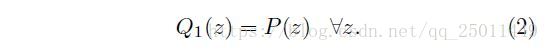
定义:若训练时的样本分布 的熵和用于重新分配分布的权重 是递增的,那么 就是一个课程,即满足以下两个条件:
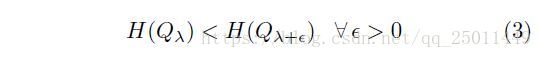
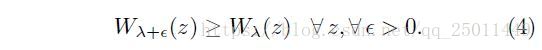
一个简单的理解就是利用课程改变训练样本中的分布,一开始简单的样本数量很多,出现的概率大,随着 增大,分布与原始数据集越来越接近,最终和原始数据一致。
到目前为止,还没有介绍如何确定课程,即如何确定训练样本的难易程度,下面的实验将介绍几种定义课程的简单方式。
4. Toy Experiments with a Convex Criterion
4.1 Cleaner Examples May Yield Better Generalization Faster
这里作者通过一个小实验说明了首先在简单样本上训练的好处。作者在一个拥有50个训练样本点的数据集上训练一个SVM进行二分类任务,实验结果表明,在简单的数据上训练的泛化误差要优于在随机选取数据上的泛化误差(16.3% vs 17.1%)。简单样本是根据 来选取的,因为对于SVM来说,满足 条件的样本点都是正确分类的,可以看作是没有噪声比较容易区分的。
有些人可能会质疑困难的样本含有更多的信息,然而困难的样本往往是无用的,因为他们可能含有噪声,会干扰训练效果。
4.2 Introduction Gradually More Difficult Examples Speeds-up Online Training
这里作者使用两种方式来说明从简单到困难的课程学习策略的有效性。
- 根据样本中不相关(irrelevant)数据的个数。
- 的margin大小,margin越大说明特征越明显越容易区分。
实验结果如下:

5. Experiments on shape recognition
这个实验关于三角形、长方形和椭圆形的形状的识别。作者用了两组数据集来区分样本的难易。一组数据集包含了等边三角形、正方形和圆形(BasicShapes),另一组中的形状并不那么规则(GeomShapes)。为了说明课程学习的效果,作者采取了以下策略:
- 将仅使用GeomShapes数据集训练的结果作为baseline。
- 开始先用BasicShapes数据集中的数据进行训练,为了区分难易程度,分别训练0、2、4……、128个epochs(0 epoch就是baseline),然后再用GeomShapes训练至256个epochs,如果validation error到达设定的最小值就提前停止。结果如下图所示:
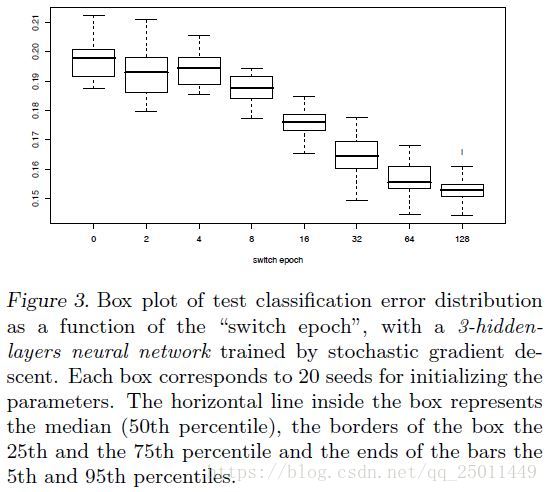
但是这样的结果可能是因为相比没有课程学习的训练,课程学习的方式看到了更多的样本。因此作者又进行了两个实验,一个是使用BasicShapes和GeomShapes两个数据集的数据在没有课程学习策略的情况下进行训练(这样看到的数据就一样多了);另一个是只使用BasicShapes数据集中的数据进行非课程学习的训练(这样就验证了并非BasicShapes中的数据比较好),两个对比实验的结果都不好,从而说明的课程学习的效果。
6. Experiment on language modeling
这个实验是根据句子上下文来预测下一个单词是什么。作者使用了Collobert和Weston的策略。
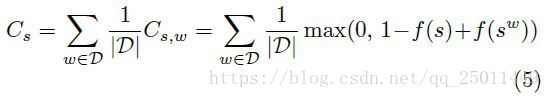
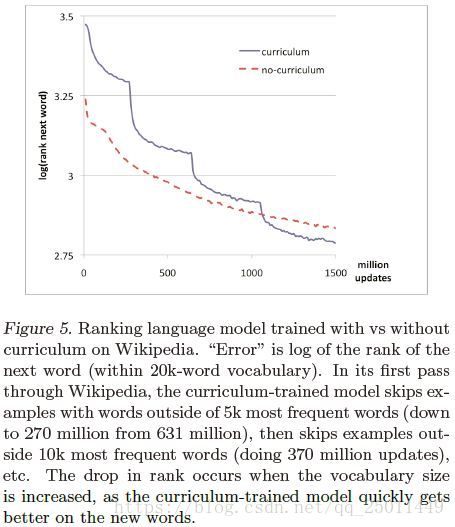
这里对于一个可能的文本 我们想让 尽量大(最大为1),这样其他文本对应的 就会尽量小,那么 就会接近于零。课程学习的策略是根据是不是常见的词汇,词典中每次增加5000个常见的词语,只要每组词汇中有词不在考虑的范围内,就丢掉这组词汇。没有课程学习策略的就直接从20000个单词中学习。下面是训练的效果:
7. Discussion and Future Work
作者认为课程学习之所以有效可以从以下两个方面解释:
- 在训练初期能够花更少的时间在有噪声的和很难去训练的数据上
- 可以引导训练走向更好的局部最优和更好的泛化效果:课程学习可以被看作是一种特殊的continuation method。
另外,如何寻找更好的课程将是未来的研究方向。