论文基本信息:
DOI: 10.1109/LCOMM.2019.2921755

目录
2.1 one-Epoch BlockFL Operation
3. END-TO-END LATENCY ANALYSIS
3.1 One-Epoch BlockFL Latency Model
3.2 Latency Optimal Block Generation Rate
4.NUMERICAL RESULTS AND DISCUSSION
1.INTRODUCTION
传统的联邦学习主要有以下局限性:
(1)依赖单一的中央服务器,容易受到服务器故障的影响;
(2)没有合适的奖励机制来刺激用户提供数据训练和上传模型参数。
对此,作者提出了【基于区块链的区块链联邦学习(BlockFL)】:
(1)用区块链网络来代替中央服务器,区块链网络允许交换设备的本地模型更新;
(2)加入验证和提供相应的奖励机制。
加入区块链之后,还要考虑延迟问题,因为越高的延迟会导致越多的forking现象。造成延迟的原因主要有以下几个:
compution delays:训练本地模型、在本地计算全局模型;
communication delays:上传本地模型、下载本地模型、块传播延迟、块验证延迟(可忽略);
block Generation:块生成延迟。
对此,作者又对BlockFL由区块链网络引起的延迟进行了分析,研究了BlockFL端到端学习完成延迟,考虑通过调整块的生成速率即POW难度来使延迟最小化,以此增加系统的实用性。

2. ARCHITECTURE AND OPERATION
2.1 one-Epoch BlockFL Operation

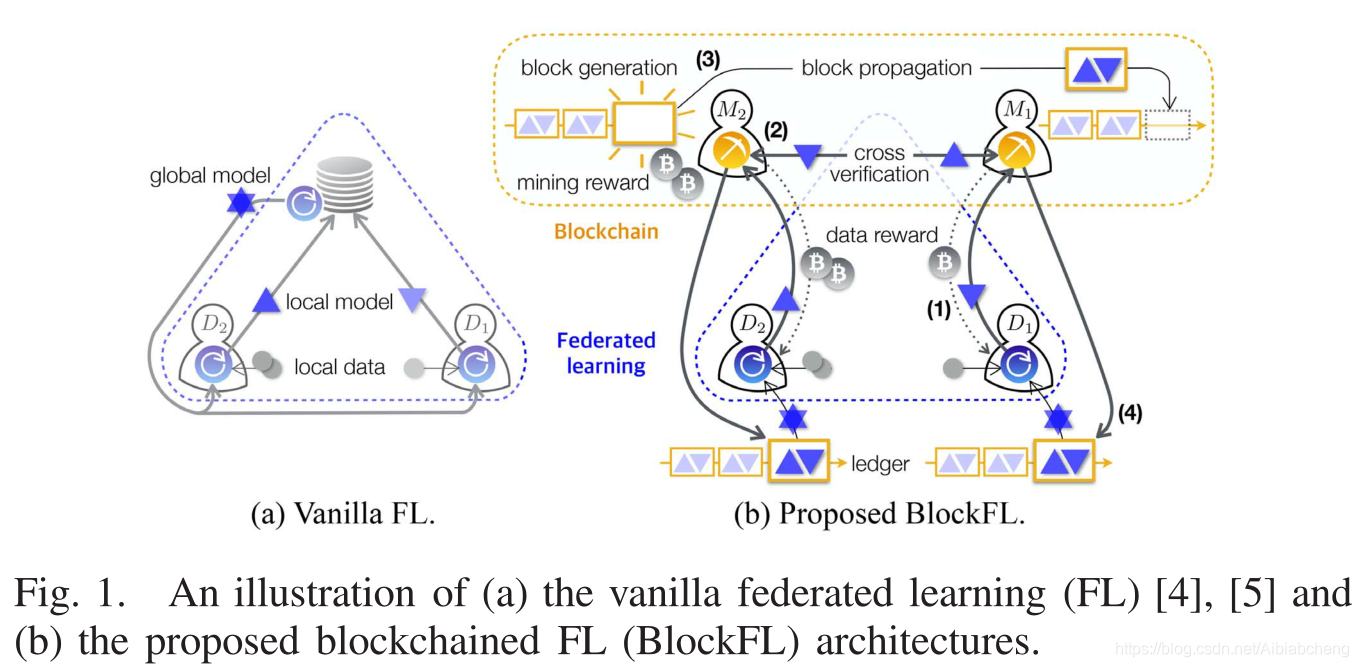
Fig.1.a是传统FL的架构,不再进行赘述。
Fig.1.b是BlockFL的架构。BlockFL的逻辑结构由矿工和设备组成。矿工在物理上是随机选择的设备或者单独节点。
BlockFL每一轮训练可以分为7个步骤:
1)本地模型更新:设备
用local sample训练local model。[计算公式(1)]
2)本地模型上传:设备
3)交叉验证:矿工广播传递local model并进行验证。若验证通过,则把它记录在矿工的候选块中(直到达到block size,或者达到maxinum waiting time)。
4)块生成:每个矿工运行POW,直到找到nonce或收到生成块。
5)块传播:首次找到nonce的矿工的候选块被作为新块并传播给其他矿工,矿工从区块链网络上获得挖矿奖励(mining reward)。为了避免链分叉,一旦每个矿工接收到新的块,就发送一个ACK,包括是否发生forking。如果发生forking,操作将从第1)步重新开始,生成新块的矿工等待一个预定义的而最大block ACK waiting time。
6)全局模型下载:设备
从相邻矿工那里下载新块。
7)全局模型更新:设备
这个循环过程结束的条件:.
2.2 FL operation in BlockFL
(1)设备集:.
的数据样本为
.
(2)FL模型:本文解决的是并行回归问题。
所有设备的数据样本:
,其中,
是d维列向量,
。
目标:minimize loss function 。


和传统FL一样,使用随机方差消减梯度算法。所有的设备的本地模型更新采用分布式拟牛顿法进行聚合。

3. END-TO-END LATENCY ANALYSIS
3.1 One-Epoch BlockFL Latency Model
延迟分析在instruction中已有叙述,此处略。
3.2 Latency Optimal Block Generation Rate

推导出最优的“块生成率”。(过程略)
结论:过大的块生成率,forking的发生率变大,进而导致学习完成延迟变大。
相反,过小的块生成率,生成块的代价变大,延迟也会变高。
4.NUMERICAL RESULTS AND DISCUSSION
数值评估了BlockFL的平均完成学习延迟。

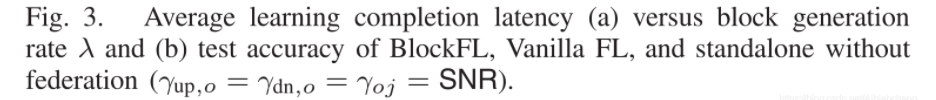
Fig.3.a 表示块生成率对BlockFL的平均学习完成延迟的影响
延迟图像是凸形的,并且随着SNR(信噪比)的增大而减小。
Fig.3.b 说明
在设备数量相同的情况下,BlockFL与传统FL的准确率几乎相等。

Fig.4.a 说明BlockFL的学习完成延迟比传统FL更低()。
的时候,通过以0.05的概率向每个矿工的本地模型更新加入高斯噪声
。
- 无故障时,延迟的原因主要有:交叉验证、块传播。
- 在BlockFL中,每个矿工的故障仅仅影响它相联的设备,而这些设备可以从其他互联的正常矿工那里获得模型,从而消除这个影响。
- 较多的矿工可以获得更低的延迟。(
,有故障时)
- 存在一个使延迟最低的设备数目。过多的设备可以有更多可以利用的数据集,但会增大每个块的大小和块交换的时间,导致如图的“凸形延迟”。
Fig.4.b 设定一个设备成为矿工的门槛.
无故障时,学习完成延迟变大(因为低门槛时,矿工多,交叉验证和块传播延迟高)
有故障时,延迟反而低(因为矿工少了,耗时减少)
Fig.4.c 表示恶意矿工的链比诚实矿工的链长的概率。
说明只要有几个块被诚实矿工“锁”住,被恶意矿工篡改的概率就几乎为0.
5.思考
由于移动设备、网络延迟、电源故障 及 间歇可用性 等原因,所有的设备都在内成功上传local model是不符合实际的。