论文精读之PDE-Net: Learning PDEs from Data
整理人:陈振庭 文章中两个案例的代码 摘要
这篇文章,我们设计了一个深度前馈网络-----PDE-Net ,基于如下的非线性PDE:
u
t
=
F
(
x
,
u
,
∇
u
,
∇
2
u
,
…
)
,
x
∈
Ω
⊂
R
2
t
∈
[
0
,
T
]
u _ { t } = F \left( x , u , \nabla u , \nabla ^ { 2 } u , \ldots \right) , \quad x \in \Omega \subset R ^ { 2 } \quad t \in [ 0 , T ]
u t = F ( x , u , ∇ u , ∇ 2 u , … ) , x ∈ Ω ⊂ R 2 t ∈ [ 0 , T ]
给定一组测量值和一些物理量:
{
u
(
t
,
⋅
)
:
t
=
t
0
,
t
1
,
…
}
\left\{ u ( t , \cdot ) : t = t _ { 0 } , t _ { 1 } , \ldots \right\}
{ u ( t , ⋅ ) : t = t 0 , t 1 , … }
Ω
⊂
R
2
\Omega \subset R ^ { 2 }
Ω ⊂ R 2
u
(
t
,
⋅
)
:
Ω
↦
R
u ( t , \cdot ) : \Omega \mapsto R
u ( t , ⋅ ) : Ω ↦ R
u
t
(
t
,
x
,
y
)
=
F
(
x
,
y
,
u
x
,
u
y
,
u
x
x
,
u
x
y
,
u
y
y
,
…
)
,
(
1
)
∣
u _ { t } ( t , x , y ) = F \left( x , y , u _ { x } , u _ { y } , u _ { x x } , u _ { x y } , u _ { y y } , \ldots \right) , ( 1 ) |
u t ( t , x , y ) = F ( x , y , u x , u y , u x x , u x y , u y y , … ) , ( 1 ) ∣
(
x
,
y
)
∈
Ω
R
2
,
t
∈
[
0
,
T
]
( x , y ) \in \Omega R ^ { 2 } , t \in [ 0 , T ]
( x , y ) ∈ Ω R 2 , t ∈ [ 0 , T ]
定义2.1 (Order of Sum Rules)
q
q
q
∑
k
∈
Z
2
k
β
q
[
k
]
=
0
(
2
)
\sum _ { k \in Z ^ { 2 } } k ^ { \beta } q [ k ] = 0 \quad ( 2 )
k ∈ Z 2 ∑ k β q [ k ] = 0 ( 2 )
q
q
q
α
=
(
α
1
,
α
2
)
\alpha = \left( \alpha _ { 1 } , \alpha _ { 2 } \right)
α = ( α 1 , α 2 )
α
∈
Z
+
2
\alpha \in Z _ { + } ^ { 2 }
α ∈ Z + 2
β
=
(
β
1
,
β
2
)
∈
Z
+
2
\beta = \left( \beta _ { 1 } , \beta _ { 2 } \right) \in Z _ { + } ^ { 2 }
β = ( β 1 , β 2 ) ∈ Z + 2
∣
β
∣
:
=
β
1
+
β
2
<
∣
α
∣
| \beta | : = \beta _ { 1 } + \beta _ { 2 } < | \alpha |
∣ β ∣ : = β 1 + β 2 < ∣ α ∣
β
∈
Z
+
2
\beta \in Z _ { + } ^ { 2 }
β ∈ Z + 2
∣
β
∣
=
∣
α
∣
| \beta | = | \alpha |
∣ β ∣ = ∣ α ∣
β
≠
α
\beta \neq \alpha
β ̸ = α
β
∈
Z
+
2
\beta \in Z _ { + } ^ { 2 }
β ∈ Z + 2
∣
β
∣
<
K
| \beta | < \mathrm { K }
∣ β ∣ < K
β
≠
β
‾
\beta \neq \overline { \beta }
β ̸ = β
β
‾
∈
Z
+
2
\overline { \beta } \in Z _ { + } ^ { 2 }
β ∈ Z + 2
∣
β
‾
∣
=
J
<
K
| \overline { \beta } | = \mathrm { J } < \mathrm { K }
∣ β ∣ = J < K
K
\
{
J
+
1
}
K \backslash \{ J + 1 \}
K \ { J + 1 }
N
∗
N
N*N
N ∗ N
q
,
N
q,N
q , N
q
q
q
−
N
−
1
2
- \frac { N - 1 } { 2 }
− 2 N − 1
∑
l
=
−
N
−
1
2
N
−
1
2
∑
m
=
−
N
−
1
2
N
−
1
2
l
β
1
m
β
2
q
[
l
,
m
]
=
0
\sum _ { l = - \frac { N - 1 } { 2 } } ^ { \frac { N - 1 } { 2 } } \sum _ { m = - \frac { N - 1 } { 2 } } ^ { \frac { N - 1 } { 2 } } l ^ { \beta _ { 1 } } m ^ { \beta _ { 2 } } q [ l , m ] = 0
l = − 2 N − 1 ∑ 2 N − 1 m = − 2 N − 1 ∑ 2 N − 1 l β 1 m β 2 q [ l , m ] = 0
q
q
q
α
∈
Z
+
2
\alpha \in Z _ { + } ^ { 2 }
α ∈ Z + 2
F
(
x
)
on
R
2
F ( x ) \text { on } R ^ { 2 }
F ( x ) on R 2
1
ε
∣
α
∣
∑
k
∈
Z
2
q
[
k
]
F
(
x
+
ε
k
)
=
C
α
∂
α
∂
x
α
F
(
x
)
+
O
(
ε
)
,
a
s
ε
→
0
(
3
)
\frac { 1 } { \varepsilon ^ { | \alpha | } } \sum _ { k \in \mathbb { Z } ^ { 2 } } q [ k ] F ( x + \varepsilon k ) = C _ { \alpha } \frac { \partial ^ { \alpha } } { \partial x ^ { \alpha } } F ( x ) + O ( \varepsilon ) , a s \varepsilon \rightarrow 0(3)
ε ∣ α ∣ 1 k ∈ Z 2 ∑ q [ k ] F ( x + ε k ) = C α ∂ x α ∂ α F ( x ) + O ( ε ) , a s ε → 0 ( 3 )
q
q
q
K
\
{
∣
α
∣
+
1
}
K \backslash \{ | \alpha | + 1 \}
K \ { ∣ α ∣ + 1 }
K
>
∣
α
‾
∣
K > |\overline { \alpha } |
K > ∣ α ∣
1
ε
∣
α
∣
∑
k
∈
Z
2
q
[
k
]
F
(
x
+
ε
k
)
=
C
α
∂
α
∂
x
α
F
(
x
)
+
O
(
ε
K
−
∣
α
∣
)
,
a
s
ε
→
0
(
4
)
\frac { 1 } { \varepsilon ^ { | \alpha | } } \sum _ { k \in Z ^ { 2 } } q [ k ] F ( x + \varepsilon k ) = C _ { \alpha } \frac { \partial ^ { \alpha } } { \partial x ^ { \alpha } } F ( x ) + O \left( \varepsilon ^ { K - | \alpha | } \right) , a s \varepsilon \rightarrow 0(4)
ε ∣ α ∣ 1 k ∈ Z 2 ∑ q [ k ] F ( x + ε k ) = C α ∂ x α ∂ α F ( x ) + O ( ε K − ∣ α ∣ ) , a s ε → 0 ( 4 )
α
\alpha
α
α
\alpha
α
q
q
q
K
>
∣
α
∣
+
k
,
k
≥
1
K >| \alpha | + k , k \geq 1
K > ∣ α ∣ + k , k ≥ 1
q
=
(
1
0
−
1
2
0
−
2
1
0
−
1
)
q = \left( \begin{array} { c c c } { 1 } & { 0 } & { - 1 } \\ { 2 } & { 0 } & { - 2 } \\ { 1 } & { 0 } & { - 1 } \end{array} \right)
q = ⎝ ⎛ 1 2 1 0 0 0 − 1 − 2 − 1 ⎠ ⎞
∂
∂
x
\frac { \partial } { \partial x }
∂ x ∂
N
∗
N
N*N
N ∗ N
q
,
Q
q,Q
q , Q
M
(
q
)
=
(
m
i
,
j
)
N
×
N
M ( q ) = \left( m _ { i , j } \right) _ { N \times N }
M ( q ) = ( m i , j ) N × N
m
i
,
j
=
1
(
i
−
1
)
!
(
j
−
1
)
!
∑
k
∈
Z
2
k
1
i
−
1
k
2
j
−
1
q
[
k
1
,
k
2
]
m _ { i , j } = \frac { 1 } { ( i - 1 ) ! ( j - 1 ) ! } \sum _ { k \in \mathbb { Z } ^ { 2 } } k _ { 1 } ^ { i - 1 } k _ { 2 } ^ { j - 1 } q \left[ k _ { 1 } , k _ { 2 } \right]
m i , j = ( i − 1 ) ! ( j − 1 ) ! 1 ∑ k ∈ Z 2 k 1 i − 1 k 2 j − 1 q [ k 1 , k 2 ]
i
,
j
=
1
,
2
,
…
,
N
i , j = 1,2 , \ldots , N
i , j = 1 , 2 , … , N
M
(
q
)
M(q)
M ( q )
∂
u
∂
x
\frac { \partial u } { \partial x }
∂ x ∂ u
q
⊗
u
q \otimes u
q ⊗ u
q
q
q
M
(
q
)
M(q)
M ( q )
(
0
0
⋆
1
⋆
⋆
⋆
⋆
⋆
)
or
(
0
0
0
1
0
⋆
0
⋆
⋆
)
(
6
)
\left( \begin{array} { c c c } { 0 } & { 0 } & { \star } \\ { 1 } & { \star } & { \star } \\ { \star } & { \star } & { \star } \end{array} \right) \quad \text { or } \quad \left( \begin{array} { c c c } { 0 } & { 0 } & { 0 } \\ { 1 } & { 0 } & { \star } \\ { 0 } & { \star } & { \star } \end{array} \right)(6)
⎝ ⎛ 0 1 ⋆ 0 ⋆ ⋆ ⋆ ⋆ ⋆ ⎠ ⎞ or ⎝ ⎛ 0 1 0 0 0 ⋆ 0 ⋆ ⋆ ⎠ ⎞ ( 6 )
M
(
q
)
M(q)
M ( q )
M
(
q
)
=
(
0
0
0
1
0
0
0
0
0
)
M(q) = \left( \begin{array} { c c c } {0 } & { 0 } & { 0} \\ { 1 } & { 0 } & { 0} \\ { 0 } & { 0 } & { 0 } \end{array} \right)
M ( q ) = ⎝ ⎛ 0 1 0 0 0 0 0 0 0 ⎠ ⎞
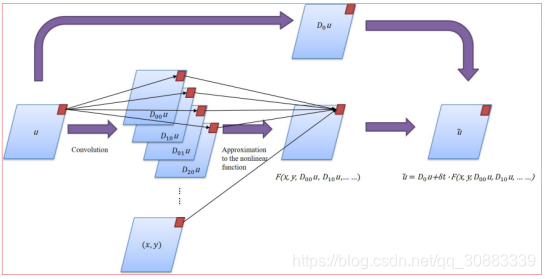
对于给定的PDE(1),我们使用向前欧拉做时间的离散。
δ
t
−
b
l
o
c
k
\delta t - b l o c k
δ t − b l o c k
u
~
(
t
i
+
1
,
⋅
)
\widetilde { u } \left( t _ { i } + 1 , \cdot \right)
u
( t i + 1 , ⋅ )
u
u
u
t
i
+
1
t _ { i + 1 }
t i + 1
u
u
u
t
i
t _ { i }
t i
u
~
(
t
i
+
1
,
⋅
)
=
D
0
u
(
t
i
,
⋅
)
+
Δ
t
⋅
F
(
x
,
y
,
D
00
u
,
D
10
u
,
D
01
u
,
D
20
u
,
…
 
)
.
(
7
)
\tilde { u } \left( t _ { i + 1 } , \cdot \right) = D _ { 0 } u \left( t _ { i } , \cdot \right) +\Delta t \cdot F \left( x , y , D _ { 00 } u , D _ { 10 } u , D _ { 01 } u , D _ { 20 } u , \dots \right).(7)
u ~ ( t i + 1 , ⋅ ) = D 0 u ( t i , ⋅ ) + Δ t ⋅ F ( x , y , D 0 0 u , D 1 0 u , D 0 1 u , D 2 0 u , … ) . ( 7 )
D
0
,
D
i
j
D _ { 0 } , D _ { i j }
D 0 , D i j
D
0
u
=
q
0
⊗
u
and
D
i
j
u
=
q
i
j
⊗
u
D _ { 0 } u = q _ { 0 } \otimes u \text { and } D _ { i j } u = q _ { i j } \otimes u
D 0 u = q 0 ⊗ u and D i j u = q i j ⊗ u
D
i
j
u
≈
∂
i
+
j
u
∂
i
x
∂
j
y
D _ { i j } u \approx \frac { \partial ^ { i + j } u } { \partial ^ { i } x \partial ^ { j } y }
D i j u ≈ ∂ i x ∂ j y ∂ i + j u
δ
t
−
b
l
o
c
k
\delta t - b l o c k
δ t − b l o c k
δ
t
−
b
l
o
c
k
\delta t - b l o c k
δ t − b l o c k
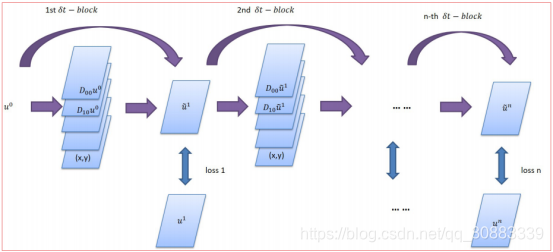
PDE-NET (MULTIPLE
δ
t
−
b
l
o
c
k
s
\delta t - b l o c ks
δ t − b l o c k s
δ
t
−
b
l
o
c
k
\delta t - b l o c k
δ t − b l o c k
δ
t
−
b
l
o
c
k
s
\delta t - b l o c ks
δ t − b l o c k s
PDE-Net可以简单描述为:
δ
t
−
b
l
o
c
k
s
\delta t - b l o c ks
δ t − b l o c k s
δ
t
−
b
l
o
c
k
s
\delta t - b l o c ks
δ t − b l o c k s
u
(
t
i
,
⋅
)
u \left( t _ { i } , \cdot \right)
u ( t i , ⋅ )
δ
t
−
b
l
o
c
k
s
\delta t - b l o c ks
δ t − b l o c k s
∥
u
(
t
i
+
n
,
⋅
)
−
u
~
(
t
i
+
n
,
⋅
)
∥
2
2
\left\| u \left( t _ { i + n } , \cdot \right) - \widetilde { u } \left( t _ { i + n } , \cdot \right) \right\| _ { 2 } ^ { 2 }
∥ u ( t i + n , ⋅ ) − u
( t i + n , ⋅ ) ∥ 2 2
u
~
(
t
i
+
n
,
)
\widetilde { \mathcal { u } } \left( t _ { i + n } , \right)
u
( t i + n , )
u
(
t
i
,
⋅
)
u \left( t _ { i } , \cdot \right)
u ( t i , ⋅ )
{
u
j
(
t
,
⋅
)
:
i
,
j
=
0
,
1
,
…
}
\left\{ u _ { j } ( t , \cdot ) : i , j = 0,1 , \ldots \right\}
{ u j ( t , ⋅ ) : i , j = 0 , 1 , … }
j
j
j
j
j
j
n
δ
t
−
b
l
o
c
k
s
n\delta t - b l o c ks
n δ t − b l o c k s
n
≥
1
n \geq 1
n ≥ 1
{
u
i
(
t
,
⋅
)
,
u
i
(
t
i
+
n
,
⋅
)
}
\left\{ u _ { i } ( t , \cdot ) , u _ { i } \left( t _ { i + n } , \cdot \right) \right\}
{ u i ( t , ⋅ ) , u i ( t i + n , ⋅ ) }
u
i
(
t
i
,
⋅
)
u _ { i } \left( t _ { i , } \cdot \right)
u i ( t i , ⋅ )
u
i
+
n
(
t
i
,
⋅
)
u _ { i+n } \left( t _ { i , } \cdot \right)
u i + n ( t i , ⋅ )
L
2
L _ { 2 }
L 2
L
=
∑
i
,
j
l
i
j
,
where
l
i
j
=
∥
u
j
(
t
i
+
n
,
⋅
)
−
u
~
j
(
t
i
+
n
,
⋅
)
∥
2
2
L = \sum _ { i , j } l _ { i j } , \text { where } l _ { i j } = \left\| u _ { j } \left( t _ { i + n } , \cdot \right) - \tilde { u } _ { j } \left( t _ { i + n } , \cdot \right) \right\| _ { 2 } ^ { 2 }
L = i , j ∑ l i j , where l i j = ∥ u j ( t i + n , ⋅ ) − u ~ j ( t i + n , ⋅ ) ∥ 2 2
u
~
i
(
t
i
+
n
,
⋅
)
\widetilde { u } _ { i } \left( t _ { i + n } , \cdot \right)
u
i ( t i + n , ⋅ )
u
i
(
t
i
,
⋅
)
{ u } _ { i } \left( t _ { i } , \cdot \right)
u i ( t i , ⋅ )
q
0
q _ { 0 }
q 0
q
i
j
q _ { ij }
q i j
D
0
D _ { 0 }
D 0
D
i
j
D_ { ij }
D i j
(
M
(
q
0
)
)
1.1
=
1
,
(
M
(
q
00
)
)
1.1
=
1
∣
\left( M \left( q _ { 0 } \right) \right) _ { 1.1 } = 1 , \left( M \left( q _ { 00 } \right) \right) _ { 1.1 } = 1 |
( M ( q 0 ) ) 1 . 1 = 1 , ( M ( q 0 0 ) ) 1 . 1 = 1 ∣
i
+
j
>
0
\ i + j > 0
i + j > 0
(
M
(
q
i
,
j
)
)
k
1
,
k
2
=
0
,
k
1
+
k
2
≤
i
+
j
+
2
,
(
k
1
,
k
2
)
≠
(
i
+
1
,
j
+
1
)
\left( M \left( q _ { i , j } \right) \right) _ { k _ { 1 } , k _ { 2 } } = 0 , k _ { 1 } + k _ { 2 } \leq i + j + 2 , \left( k _ { 1 } , k _ { 2 } \right) \neq ( i + 1 , j + 1 )
( M ( q i , j ) ) k 1 , k 2 = 0 , k 1 + k 2 ≤ i + j + 2 , ( k 1 , k 2 ) ̸ = ( i + 1 , j + 1 )
(
M
(
q
i
,
j
)
)
i
+
1
,
j
+
1
=
1
∣
\left( M \left( q _ { i , j } \right) \right) _ { i + 1 , j + 1 } = 1 |
( M ( q i , j ) ) i + 1 , j + 1 = 1 ∣
在PDE-Net中,参数可以被分为三组:
δ
t
−
b
l
o
c
k
\delta t - b l o c k
δ t − b l o c k
δ
t
−
b
l
o
c
k
\delta t - b l o c k
δ t − b l o c k
Network-In-Network(NIN)
Deep Residual Neural Network(ResNet)
我们考虑一个2维的线性变参数对流扩散方程在
Ω
=
[
0
,
2
π
]
×
[
0
,
2
π
]
\Omega = [ 0,2 \pi ] \times [ 0,2 \pi ]
Ω = [ 0 , 2 π ] × [ 0 , 2 π ]
{
∂
u
∂
t
=
a
(
x
,
y
)
u
x
+
b
(
x
,
y
)
u
y
+
0.2
u
x
x
+
0.3
u
y
y
u
∣
t
=
0
=
u
0
(
x
,
y
)
(
8
)
\left\{ \begin{array} { l l } { \frac { \partial u } { \partial t } } & { = a ( x , y ) u _ { x } + b ( x , y ) u _ { y } + 0.2 u _ { x x } + 0.3 u _ { y y } } \\ { \left. u \right| _ { t = 0 } } & { = u _ { 0 } ( x , y ) } \end{array} \right.(8)
{ ∂ t ∂ u u ∣ t = 0 = a ( x , y ) u x + b ( x , y ) u y + 0 . 2 u x x + 0 . 3 u y y = u 0 ( x , y ) ( 8 )
(
t
,
x
,
y
)
∈
[
0
,
0.3
]
×
Ω
( t , x , y ) \in [ 0,0.3 ] \times \Omega
( t , x , y ) ∈ [ 0 , 0 . 3 ] × Ω
a
(
x
,
y
)
=
0.5
(
cos
(
y
)
+
x
(
2
π
−
x
)
sin
(
x
)
)
+
0.6
b
(
x
,
y
)
=
2
(
cos
(
y
)
+
sin
(
x
)
)
+
0.8
\begin{array} { l } { a ( x , y ) = 0.5 ( \cos ( y ) + x ( 2 \pi - x ) \sin ( x ) ) + 0.6 } \\ { b ( x , y ) = 2 ( \cos ( y ) + \sin ( x ) ) + 0.8 } \end{array}
a ( x , y ) = 0 . 5 ( cos ( y ) + x ( 2 π − x ) sin ( x ) ) + 0 . 6 b ( x , y ) = 2 ( cos ( y ) + sin ( x ) ) + 0 . 8
Ω
\Omega
Ω
50
∗
50
50*50
5 0 ∗ 5 0
δ
t
=
0.015
\delta t = 0.015
δ t = 0 . 0 1 5
u
0
(
x
,
y
)
u _ { 0 } ( x , y )
u 0 ( x , y )
u
0
(
x
,
y
)
=
∑
∣
k
∣
,
∣
l
∣
≤
N
λ
k
,
l
cos
(
k
x
+
l
y
)
+
γ
k
,
l
sin
(
k
x
+
l
y
)
,
(
9
)
u _ { 0 } ( x , y ) = \sum _ { | k | , | l | \leq N } \lambda _ { k , l } \cos ( k x + l y ) + \gamma _ { k , l } \sin ( k x + l y ) ,(9)
u 0 ( x , y ) = ∣ k ∣ , ∣ l ∣ ≤ N ∑ λ k , l cos ( k x + l y ) + γ k , l sin ( k x + l y ) , ( 9 )
N
=
9
N=9
N = 9
λ
k
,
l
,
γ
k
,
l
∼
N
(
0
,
1
50
)
\lambda _ { k , l } , \gamma _ { k , l } \sim \mathrm { N } \left( 0 , \frac { 1 } { 50 } \right)
λ k , l , γ k , l ∼ N ( 0 , 5 0 1 )
k
k
k
L
L
L
u
^
(
x
,
y
,
t
)
=
u
(
x
,
y
,
t
)
+
0.015
×
M
W
(
10
)
\widehat { u } ( x , y , t ) = u ( x , y , t ) + 0.015 \times M W(10)
u
( x , y , t ) = u ( x , y , t ) + 0 . 0 1 5 × M W ( 1 0 )
M
=
max
x
,
y
,
t
{
u
(
x
,
y
,
t
)
}
,
W
∼
N
(
0
,
1
)
M = \max _ { x , y , t } \{ u ( x , y , t ) \} , W \sim \mathcal { N } ( 0,1 )
M = max x , y , t { u ( x , y , t ) } , W ∼ N ( 0 , 1 )
F
=
∑
0
≤
i
+
j
≤
4
f
i
j
(
x
,
y
)
∂
i
+
j
u
∂
x
i
∂
y
j
F = \sum _ { 0 \leq i + j \leq 4 } f _ { i j } ( x , y ) \frac { \partial ^ { i + j } u } { \partial x ^ { i } \partial y ^ { j } }
F = 0 ≤ i + j ≤ 4 ∑ f i j ( x , y ) ∂ x i ∂ y j ∂ i + j u
δ
t
−
b
l
o
c
k
\delta t - b l o c k
δ t − b l o c k
u
~
(
t
n
+
1
,
⋅
)
=
D
0
u
(
t
n
,
⋅
)
+
δ
t
⋅
(
c
00
D
00
u
+
c
10
D
10
u
+
…
+
c
04
D
04
u
)
\tilde { u } \left( t _ { n + 1 } , \cdot \right) = D _ { 0 } u \left( t _ { n } , \cdot \right)+ \delta t \cdot \left( c _ { 00 } D _ { 00 } u + c _ { 10 } D _ { 10 } u + \ldots + c _ { 04 } D _ { 04 } u \right)
u ~ ( t n + 1 , ⋅ ) = D 0 u ( t n , ⋅ ) + δ t ⋅ ( c 0 0 D 0 0 u + c 1 0 D 1 0 u + … + c 0 4 D 0 4 u )
{
D
0
,
D
i
j
:
i
+
j
≤
4
}
\left\{ D _ { 0 } , D _ { i j } : i + j \leq 4 \right\}
{ D 0 , D i j : i + j ≤ 4 }
{
c
i
j
:
i
+
j
≤
4
}
\left\{ c _ { i j } : i + j \leq 4 \right\}
{ c i j : i + j ≤ 4 }
f
i
j
(
x
,
y
)
f _ { i j } ( x , y )
f i j ( x , y )
{
D
0
,
D
i
j
:
i
+
j
≤
4
}
\left\{ D _ { 0 } , D _ { i j } : i + j \leq 4 \right\}
{ D 0 , D i j : i + j ≤ 4 }
5
∗
5
5*5
5 ∗ 5
7
∗
7
7*7
7 ∗ 7
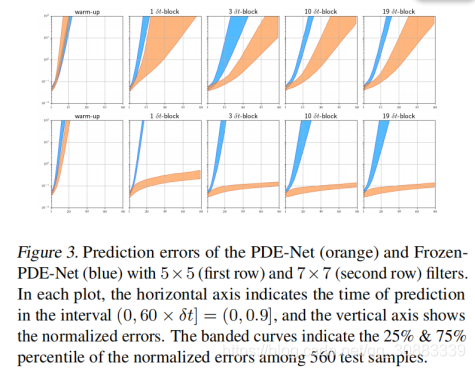
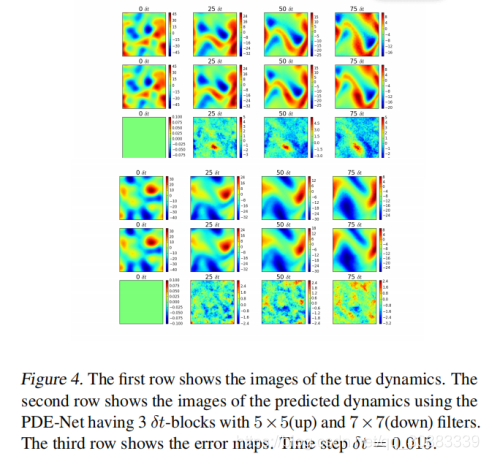
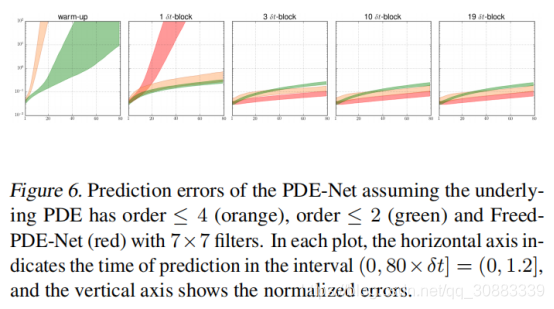
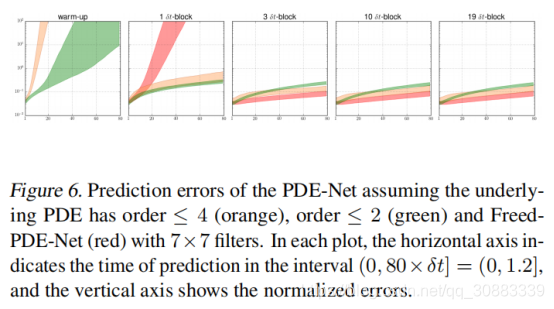
我们首先展示训练好的PDE-Net在预测方面的能力。在有的pde-net训练完后,我们随机产生了560个基于(9)(10)的初始数据,将他们喂给PDE-NET,然后测量动态预测和实际动态变化之间的误差,将误差定义为:
ϵ
=
∥
u
~
−
u
∥
2
2
∥
u
−
u
‾
∥
2
2
\epsilon = \frac { \| \tilde { u } - u \| _ { 2 } ^ { 2 } } { \| u - \overline { u } \| _ { 2 } ^ { 2 } }
ϵ = ∥ u − u ∥ 2 2 ∥ u ~ − u ∥ 2 2
u
u
u
u
~
\widetilde { u }
u
u
‾
\overline { u }
u
u
u
u
δ
t
−
b
l
o
c
k
s
\delta t - b l o c ks
δ t − b l o c k s
对于线性问题,求解PDE相当于寻找近似
{
f
i
j
:
1
≤
i
+
j
≤
4
}
\left\{ f _ { i j } : 1 \leq i + j \leq 4 \right\}
{ f i j : 1 ≤ i + j ≤ 4 }
{
c
i
j
:
1
≤
i
+
j
≤
4
}
\left\{ c _ { i j } : 1 \leq i + j \leq 4 \right\}
{ c i j : 1 ≤ i + j ≤ 4 }
{
c
i
j
:
1
≤
i
+
j
≤
2
}
\left\{ c _ { i j } : 1 \leq i + j \leq 2 \right\}
{ c i j : 1 ≤ i + j ≤ 2 }
f
11
f
i
j
:
1
≤
i
+
j
≤
2
f _ { 11 } f _ { i j } : 1 \leq i + j \leq 2
f 1 1 f i j : 1 ≤ i + j ≤ 2
{
C
i
j
}
\left\{ C _ { i j } \right\}
{ C i j }
{
f
i
j
}
\left\{ f _ { i j } \right\}
{ f i j }
δ
t
−
b
l
o
c
k
\delta t - b l o c k
δ t − b l o c k
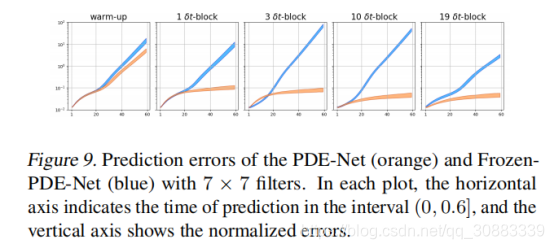
PDE(8)是二阶的,在我们前面的试验中,我们假设了PDE不超过4阶。如果我们知道PDE是二阶的,我们能够用更准确的方法估计对流和扩散项的变量系数。然而,预测的误差很高,因为我们只是用了较少的可训练参数。
我们考虑这样一个2维带有非线性汇源项的线性对流方程:
Ω
=
[
0
,
2
π
]
×
[
0
,
2
π
]
\Omega = [ 0,2 \pi ] \times [ 0,2 \pi ]
Ω = [ 0 , 2 π ] × [ 0 , 2 π ]
{
∂
u
∂
t
=
c
Δ
u
+
f
s
(
u
)
,
u
∣
t
=
0
=
u
0
(
x
,
y
)
,
with
(
t
,
x
,
y
)
∈
[
0
,
0.2
]
×
Ω
(
11
)
\left\{ \begin{array} { l l } { \frac { \partial u } { \partial t } } & { = c \Delta u + f _ { s } ( u ) , } \\ { \left. u \right| _ { t = 0 } } & { = u _ { 0 } ( x , y ) , } \end{array} \right. \quad \text { with } ( t , x , y ) \in [ 0,0.2 ] \times \Omega(11)
{ ∂ t ∂ u u ∣ t = 0 = c Δ u + f s ( u ) , = u 0 ( x , y ) , with ( t , x , y ) ∈ [ 0 , 0 . 2 ] × Ω ( 1 1 )
c
=
0.3
c = 0.3
c = 0 . 3
f
s
(
u
)
=
15
sin
(
u
)
f _ { s } ( u ) = 15 \sin ( u )
f s ( u ) = 1 5 sin ( u )
δ
t
=
0.0009
\delta t = 0.0009
δ t = 0 . 0 0 0 9
F
F
F
F
=
∑
1
≤
i
+
j
≤
2
f
i
j
(
x
,
y
)
∂
i
+
j
u
∂
x
i
∂
y
j
+
f
s
(
u
)
F = \sum _ { 1 \leq i + j \leq 2 } f _ { i j } ( x , y ) \frac { \partial ^ { i + j } u } { \partial x ^ { i } \partial y ^ { j } } + f _ { s } ( u )
F = 1 ≤ i + j ≤ 2 ∑ f i j ( x , y ) ∂ x i ∂ y j ∂ i + j u + f s ( u )
δ
t
−
b
l
o
c
k
\delta t - b l o c k
δ t − b l o c k
u
~
(
t
n
+
1
,
⋅
)
=
D
0
u
(
t
n
,
⋅
)
+
δ
t
⋅
(
∑
1
≤
i
+
j
≤
2
c
i
j
D
i
j
u
+
f
~
s
(
u
)
)
\tilde { u } \left( t _ { n + 1 } , \cdot \right) = D _ { 0 } u \left( t _ { n } , \cdot \right) + \delta t \cdot \left( \sum _ { 1 \leq i + j \leq 2 } c _ { i j } D _ { i j } u + \tilde { f } _ { s } ( u ) \right)
u ~ ( t n + 1 , ⋅ ) = D 0 u ( t n , ⋅ ) + δ t ⋅ ( 1 ≤ i + j ≤ 2 ∑ c i j D i j u + f ~ s ( u ) )
{
D
0
,
D
i
j
:
1
≤
i
+
j
≤
2
}
\left\{ D _ { 0 } , D _ { i j } : 1 \leq i + j \leq 2 \right\}
{ D 0 , D i j : 1 ≤ i + j ≤ 2 }
{
c
i
j
:
1
≤
i
+
j
≤
2
}
\left\{ c _ { i j } : 1 \leq i + j \leq 2 \right\}
{ c i j : 1 ≤ i + j ≤ 2 }
f
i
j
(
x
,
y
)
f _ { i j } ( x , y )
f i j ( x , y )
我们首先展示训练好的PDE-Net的预测能力。
对于PDE(11),确定PDE相当于寻找近似
{
f
i
j
:
1
≤
i
+
j
≤
2
}
}
\left\{ f _ { i j} : 1 \leq i + j \leq 2 \right\} \}
{ f i j : 1 ≤ i + j ≤ 2 } }
{
c
i
j
:
1
≤
i
+
j
≤
2
}
\left\{ c _ { i j } : 1 \leq i + j \leq 2 \right\}
{ c i j : 1 ≤ i + j ≤ 2 }
f
s
f _ { s }
f s
f
~
s
\widetilde { f } _ { s }
f
s
{
c
i
j
:
1
≤
i
+
j
≤
2
}
\left\{ c _ { i j } : 1 \leq i + j \leq 2 \right\}
{ c i j : 1 ≤ i + j ≤ 2 }
f
s
f _ { s }
f s
在这篇文章中,我们设计了一个深层的前馈网络叫PDE-Net,为了从观测到的动态变化中发现隐藏的PDE模型并预测其动态行为。