0、摘要
随着深度神经网络的出现,基于学习的3D重建方法得到了普及。然而,与图像不同,在3D中没有计算和内存有效的规范表示,且允许表示任意拓扑的高分辨率几何。因此,许多最先进的基于学习的3D重建方法只能表示非常粗糙的3D几何,或者仅限于有限的区域。在本文中,我们提出了一种新的基于学习的3D重建方法- -占位网络。占位网络隐式地将3D曲面表示为深度神经网络分类器的连续决策边界。与现有方法不同的是,我们的表示编码了无限分辨率的3D输出描述,而没有过多的内存占用。我们验证了我们的表示可以有效地编码3D结构,并且可以从各种输入中推断出来。我们的实验从定性和定量两个方面展示了在从单张图像、噪声点云和粗离散体素网格进行三维重建的挑战性任务中具有竞争力的结果。我们相信占位网络将成为各种基于学习的3D任务中的有用工具。

1、主要思想
设计了一个网络:Occupancy Network,该网络通过学习拟合一个函数f,其实相当于是学习了一个回归网络,输入一个点,网络输出占用概率[0,1]。
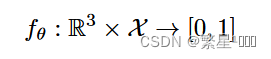
input:张量维度即为(X,3),
output: 张量维度(X,1)。
2、实现细节
2.1 网络结构
- Occupancy Network (Onet):全连接层FCN+5个ResNet blocks+(batch normalization)
- 不同的输入,不同的encoder(为什么需要encoder?,对输入数据先提取特征,转化为latent code,再输入Onet?)
- 3D reconstruction: ResNet18 architecture
- point clouds: PointNet encoder
- voxelized inputs: 3D convolutional neural network
- unconditional mesh generation: PointNet
训练,loss函数
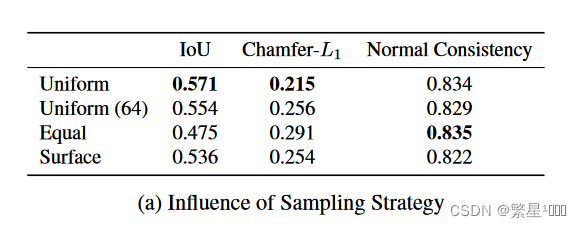
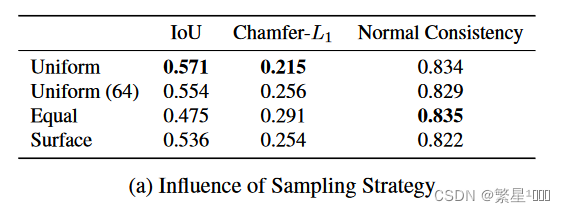
- 先采样点,采样方式会影响结果。Uniform最好
- To our surprise, we find that uniform, the simplest sampling strategy, works best. We explain this by the fact that other sampling strategies introduce bias to the model: for example, when sampling an equal number of points inside and outside the mesh, we implicitly tell the model that every object has a volume of 0.5.
- Moreover, we find that reducing the number of sampling points from 2048 to 64 still leads to good performance
- loss 函数
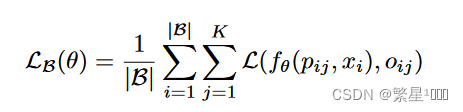
- 概率隐变量模型的loss函数,z就是隐变量

推理,重建mesh
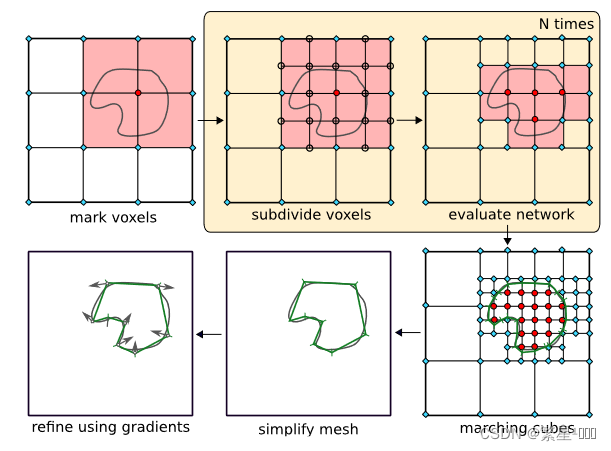
- 1、先确定一个初始的分辨率,将格点的坐标输入Onet,得到占用概率
- 2、定一个阈值T,占用概率减去这个阈值T.(阈值T决定了 提取表面的thickness厚度?)如果一个格点与至少两个相邻格点的占用概率异号,那么格点连线穿过了表面
- 3、对每个网格继续划分,新产生的格点再输入Onet中得到得到占用概率。
- 4、重复第3步,直到分辨率达到预设值
- 5、采样marching cubes算法提取mesh
- 6、使用Fast-Quadric-Mesh-Simplification算法进行微调
- 7、使用一阶和二阶梯度信息进行微调
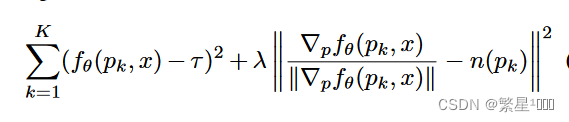
3、实验
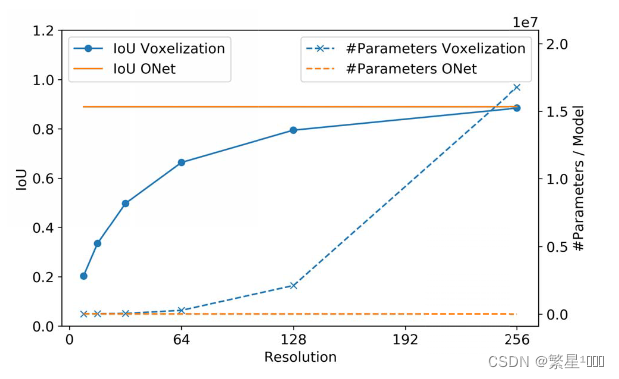
3.1 表达能力
we embed each training sample in a 512 dimensional latent space and train our neural network to reconstruct the 3D shape from this embedding.
- 细节:先将输入映射到512维的特征空间,再从特征空间输出占用概率,再重建3D形状。
- 数据集:ShapeNet chair
- 结果:
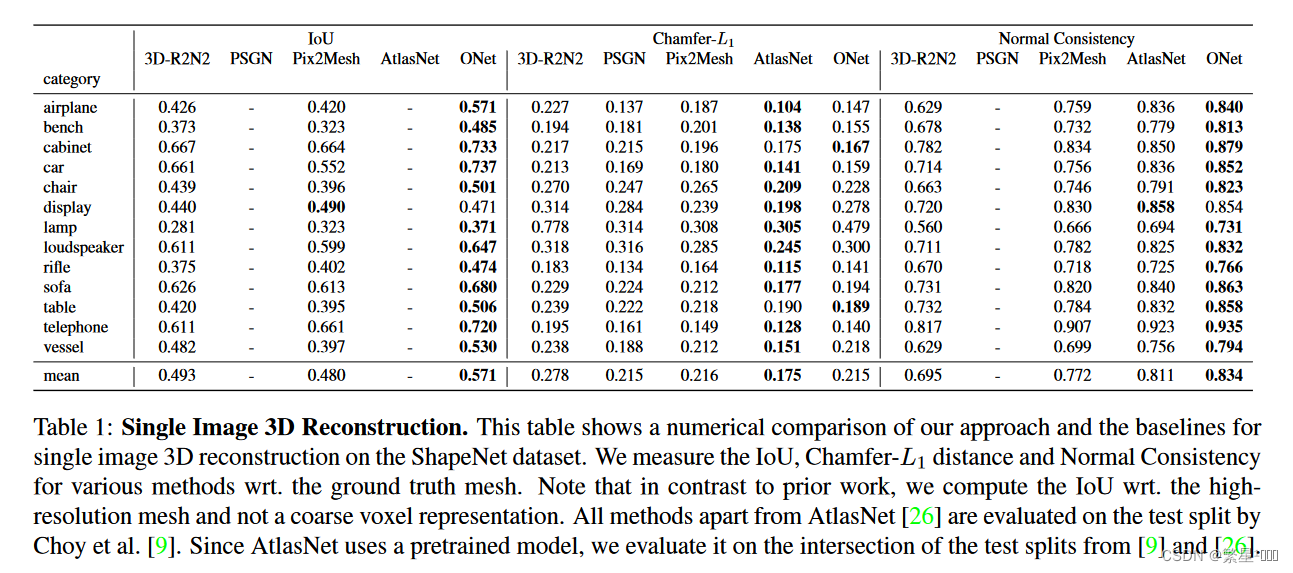
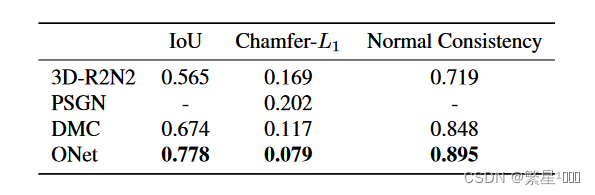
3.2 Single Image 3D Reconstruction
we use a ResNet-18 image encoder, which was pretrained on the ImageNet dataset
- 细节:
- 数据集:
- ShapeNet
- KITTI
- Online Products datasets
- 结果

3.3 Point Cloud Completion
从有噪声的点云中国重建mesh
3.4 Voxel Super-Resolution

3.5 Unconditional Mesh Generation

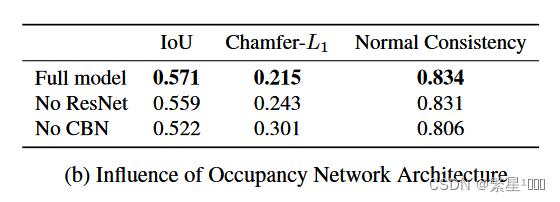
4、消融实验
4.1 采样策略的影响
4.2 网络结构的影响
CBN: conditional batch normalization