机器学习分为监督学习、无监督学习和半监督学习(强化学习)。无监督学习最常应用的场景是聚类(clustering)和降维(dimension reduction)。聚类算法包括:K均值聚类(K-Means)、层次聚类(Hierarchical Clustering)和混合高斯模型(Gaussian Mixture Model)。降维算法包括:主成因分析(Principal Component Analysis)和线性判别分析(Linear Discriminant Analysis)。
主成因分析(Principal Component Analysis: PCA)是使用最广的降维方法。PCA顾名思义,就是找出数据里最主要的方面,用数据里最主要的方面来代替原始数据。
1 算法原理
主成因分析(Principal Component Analysis)降维算法是一种非监督学习的降维方法。PCA算法利用特征值分解的思想和事件,将高维数据压缩或去噪成低维数据。PCA算法由于某些固有缺陷,出现了很多PCA算法变种: 解决非线性降维的PCA方法、解决内存限制的增量PCA方法和解决稀疏数据降维的PCA方法。
假设我们的数据集是n维的,数据集中有m个数据{X1, X2, …, Xm}。我们希望将这个数据集从n维压缩到n/2维。这个压缩明显是有损的压缩,我们唯一能做的是保证变换后的n/2维数据集能够最大限度的表征原始的n维数据集。对于正交属性空间中数据集,构建一个超平面或者超曲面将数据集合理划分到更低的维度空间,这里的超平面或者超曲面需要具有最近重构性和最大可分性才能满足上述要求。其中最近重构性要求样本点到目标超平面的距离足够近;最大可分性要求样本点到目标超平面上的投影尽可能分开。
主成因分析(Principal Component Analysis)降维算法的核心步骤如下:
- 对所有的样本进行中心化;
- 计算样本的协方差矩阵 ;
- 对协方差矩阵 进行特征值分解;
- 取出最大的n’个特征值对应的特征向量(w1,w2,…,wn′), 计算标准化特征向量矩阵W;
- 取出原始高维度样本x(i), 进行降维计算操作,获得低维度样本: z(i)=WTx(i);
- 输出降维后的样本集D′=(z(1),z(2),…,z(m))。
主成因分析(Principal Component Analysis)降维算法的核心优势如下:
- 计算伸缩性: 计算方法简单,主要运算是特征值分解,易于实现;
- 参数依赖性: 可配置目标维度数目n’;以方差衡量信息量,不受数据集以外的因素影响;
- 普适性能力: 特征值分解时各主成分之间正交,泛化能力较好;
- 抗噪音能力: 泛化能力较好,抗噪音能力强;
- 结果解释性: 特征维度的含义可能具有模糊性,解释性降低。
1.1 最佳实践
- 理解有最近重构性和最大可分性是理解主成因分析(PCA)的关键;
- 目标维度数目由用户自行设定,配合使用其他分类器(诸如:k近邻分类器)交叉验证容易选出最佳的目标维度数目;
- 线性降维方法使用线性映射函数, 将高维数据空间映射到低维数据空间,应用于非线性场景,需要引入核函数(Kernel);
2 算法实例
注意:本文中使用sklearn中的鸢尾花(yuānwěi)数据集来对特征处理功能进行说明。如果不熟悉该数据集请阅读sklearn的数据集(含python源码)并先了解一下鸢尾花(yuānwěi)数据集。
https://blog.csdn.net/shareviews/article/details/82848530
部分机器学习项目,由于数据集特征矩阵过大,导致计算量大,训练时间长的问题,因此降低特征矩阵维度也是必不可少的。常见的降维方法包括:基于L1惩罚项的模型、主成分分析法(PCA)和线性判别分析(LDA)。降维的本质就是将原始的样本映射到维度更低的样本空间中。PCA是为了让映射后的样本具有最大的发散性;而LDA是为了让映射后的样本有最好的分类性能。所以说PCA是一种无监督的降维方法,而LDA是一种有监督的降维方法。
使用sklearn.decomposition库的PCA类进行降维的代码如下:
#
# Python 3.6
#
from sklearn.datasets import load_iris
from matplotlib import pyplot as plt
from sklearn.decomposition import PCA
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
iris = load_iris()
print(iris.keys())
print("iris.keys() = {0}".format(iris.keys()))
raw_data = iris['data']
print("iris.data.shape = {0}".format(raw_data.shape))
feature_names = iris['feature_names']
print("data.feature_names = {0}".format(feature_names))
raw_target = iris['target']
print("data.target.shape = {0}".format(raw_target.shape))
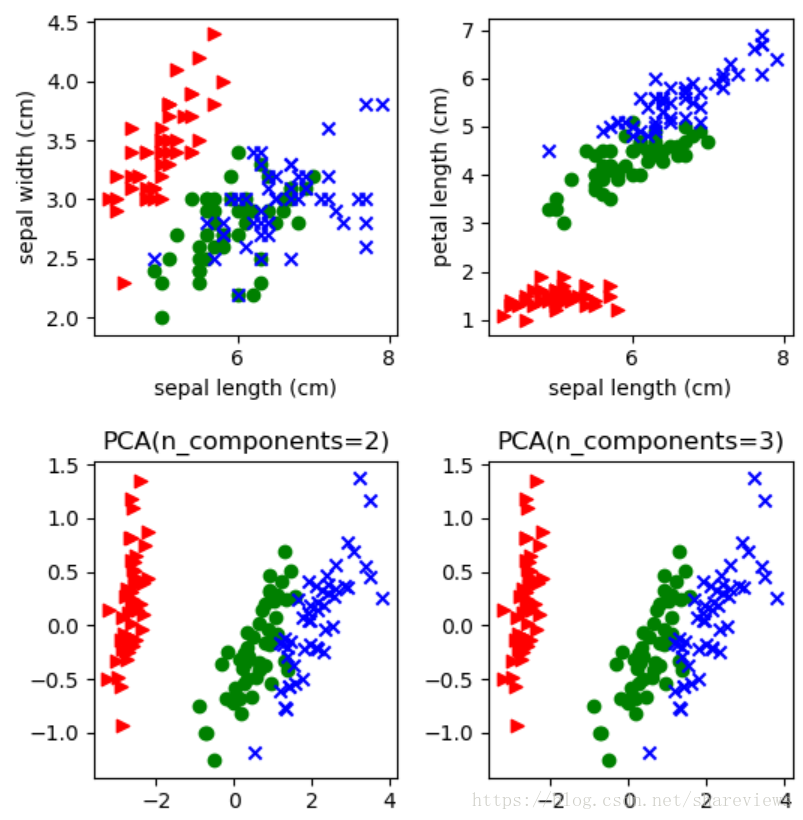
def plot_iris_projection(x_index, y_index):
# plt.scatter one type of iris flower with one color.
types_count = 3
for t,marker,c in zip(range(types_count),'>ox', 'rgb'):
plt.scatter(dst_data[dst_target==t,x_index],
dst_data[dst_target==t,y_index],
marker=marker,c=c)
if(dst_data.shape[1] == 4):
plt.xlabel(feature_names[x_index])
plt.ylabel(feature_names[y_index])
plt.figure(figsize=(16, 9))
dst_data = raw_data
dst_target = raw_target
plt.subplot(2, 2, 1)
plot_iris_projection(x_index=0, y_index=1)
plt.subplot(2, 2, 2)
plot_iris_projection(x_index=0, y_index=2)
# unsupervised dimensionality reduction
dst_data = PCA(n_components=2).fit_transform(raw_data)
ax = plt.subplot(2, 2, 3)
ax.set_title('PCA(n_components=2)')
plot_iris_projection(x_index=0, y_index=1)
print(dst_data.shape)
# unsupervised dimensionality reduction
dst_data = PCA(n_components=3).fit_transform(raw_data)
ax = plt.subplot(2, 2, 4)
ax.set_title('PCA(n_components=3)')
plot_iris_projection(x_index=0, y_index=1)
print(dst_data.shape)
#Adjust subgraph spacing
plt.subplots_adjust(wspace =0.3, hspace =0.4)
plt.show()
由上图可以看出,sklearn.decomposition库的PCA类仅需要配置维度数量n_components即可,不需要额外的调参。原始数据维度print(raw_data.shape)为(150,4)。处理后为数据维度print(dst_data.shape)为(150, 2)和(150,3)得到了降维的目的。
3 典型应用
主成因分析(PCA)是无监督线性降维方法,线性判别分析(LDA)是最著名的有监督线性降维方法。他们也存在核函数版本,用以支持非线性降维场景。主成因分析(PCA)能够将具有一定相关性的多个指标,重新组合成一组新的较少的互不相关的综合指标来代替原来指标,保持原有近似的精度下,压缩指标量实现降维。主成因分析(PCA)在数据压缩消除冗余和数据噪音消除等领域都有广泛的应用。
美国的统计学家Stone在1947年关于国民经济的研究是一项十分著名的工作。他曾利用美国1929年到1938年各年数据,得到了17个反映国民收入与支出的变量要素,例如雇主补贴、消费资料和生产资料、纯公共支出、净增库存、股息、利息、外贸平衡等等。在进行主成因分析(PCA)之后,竟然以97.4%的精度,用3个新变量就取代了原先的17个变量指标。根据经济学知识,Stone将这3个新变量分别命名为总收入F1,总收入变化率F2 和经济发展(或者衰退)趋势F3。
数据分析软件SPSS和MatLab等都具有主成因分析(PCA)模块,他们通过计算协方差矩阵和特征值矩阵、特征向量的函数等,来实现PCA分析。
系列文章
参考资料
- [1] 周志华. 机器学习. 清华大学出版社. 2016.
- [2] [日]杉山将. 图解机器学习. 人民邮电出版社. 2015.
- [3] 佩德罗·多明戈斯. 终极算法-机器学习和人工智能如何重塑世界. 中信出版社. 2018.