import numpy as np
from sklearn import linear_model
import matplotlib.pyplot as plt
#画图函数画出数据点和边界
def plot_classifier(classifier, X, y):
# 定义图形的取值范围
x_min, x_max = min(X[:, 0]) - 1.0, max(X[:, 0]) + 1.0
y_min, y_max = min(X[:, 1]) - 1.0, max(X[:, 1]) + 1.0
# 设置网格数据的步长
step_size = 0.01
# 定义网格
x_values, y_values = np.meshgrid(np.arange(x_min, x_max, step_size), np.arange(y_min, y_max, step_size))
# 计算分类器输出结果
mesh_output = classifier.predict(np.c_[x_values.ravel(), y_values.ravel()])
# 数组维度变形
mesh_output = mesh_output.reshape(x_values.shape)
# 用彩画画出各个类型的边界
plt.figure()
# 选择配方方案
plt.pcolormesh(x_values, y_values, mesh_output, cmap=plt.cm.gray)
# 画训练点
plt.scatter(X[:, 0], X[:, 1], c=y, s=80, edgecolors='black', linewidth=1, cmap=plt.cm.Paired)
# 设置图形的取值范围
plt.xlim(x_values.min(), x_values.max())
plt.ylim(y_values.min(), y_values.max())
#设置X轴与Y轴
plt.xticks((np.arange(int(min(X[:, 0])-1), int(max(X[:, 0])+1), 1.0)))
plt.yticks((np.arange(int(min(X[:, 1])-1), int(max(X[:, 1])+1), 1.0)))
#坐标含义
plt.xlabel('X')
plt.ylabel('Y')
plt.title('C=10000')
plt.show()
if __name__=='__main__':
#假设一共有三类数据
X = np.array([[4, 7], [3.5, 8], [3.1, 6.2], [0.5, 1], [1, 2], [1.2, 1.9], [6, 2], [5.7, 1.5], [5.4, 2.2]])
y = np.array([0, 0, 0, 1, 1, 1, 2, 2, 2])
#初始化一个逻辑回归分类器
classifier = linear_model.LogisticRegression(solver = 'liblinear', C = 10000)
classifier.fit(X, y)
plot_classifier(classifier, X,y)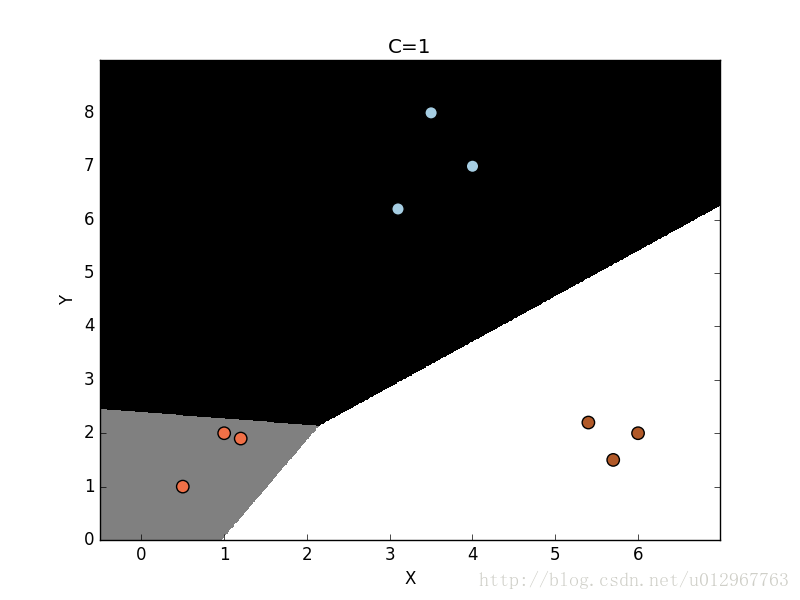
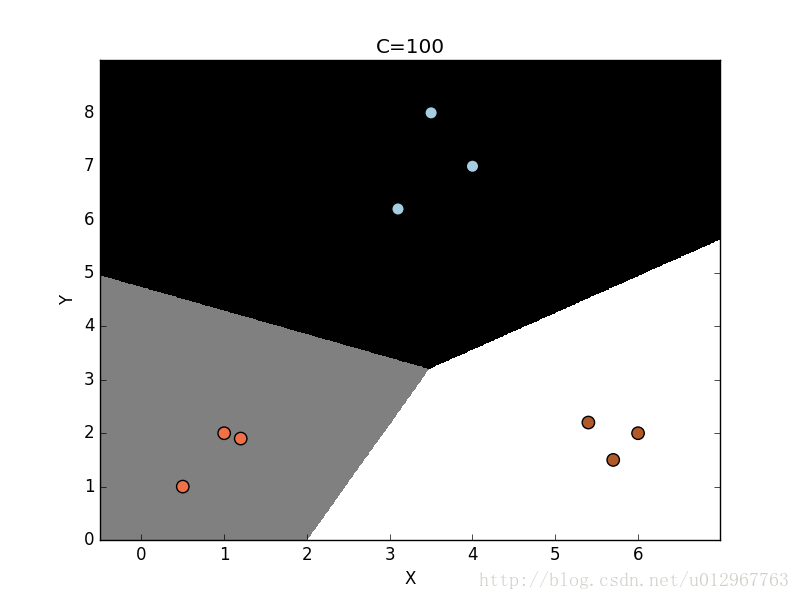
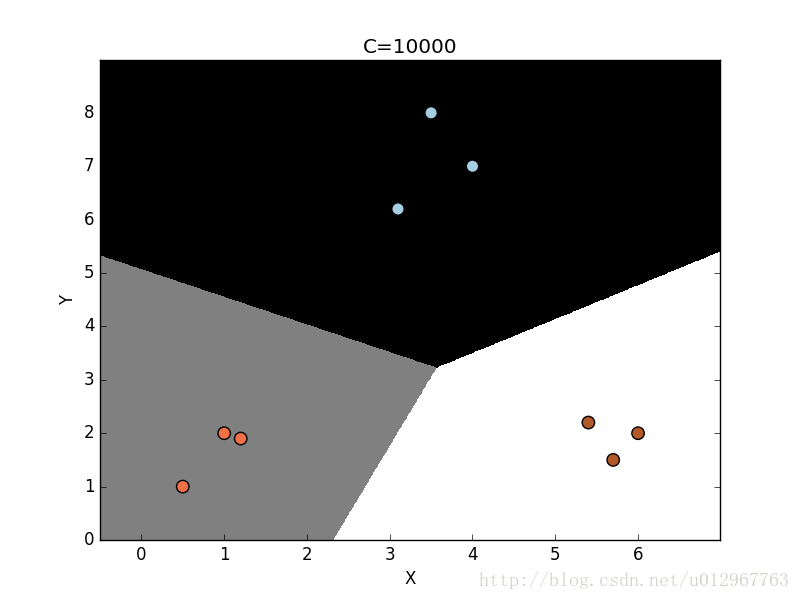
参数C表示对分类错误的惩罚值。随着参数C的不断增大,分类错误的惩罚值越高。因此,各个类型的边界更优。