上一节主要介绍了机器学习中监督学习和无监督学习的区别。这一章主要介绍监督学习中的分类算法-逻辑回归,也叫logistic回归。
逻辑回归:根据已有的数据点,根据这些数据分类的边界建立回归公式,找到最佳拟合参数集。
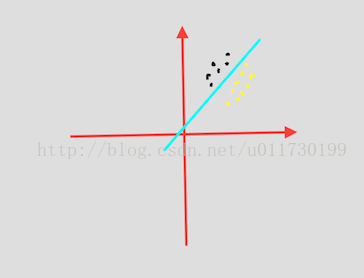
要介绍算法实现之前,肯定要先介绍其数学实现原理。
对于这些特征数据点,假如我们有:(公式图片来源于网络)
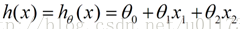
(x1,x2代表数据的特征,比如这些数据点是来自一个电视的特征,x1代表电视屏幕大小,x2代表电视屏幕分辨率,θ是权重参数)
我们知道这条线肯定不会和全部的数据点拟合,所以我们要设计一个公式来衡量所得到参数的精确性,这里把它称作损失函数或代价函数,逻辑分类的代价函数为:
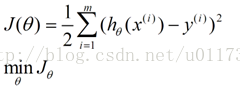
逻辑回归中我们要计算这个公式的最大值,因为这是个分类问题,所以两侧的点到线的距离越大也就代表这条直线分类效果越好,就像求一个函数的最大值,我们上学时就知道要求一个函数的最大值,如果是多元函数,就是求其偏导数,这里有个专有名词叫做梯度上升,【把偏导数符号变一下就变成梯度下降】,这里θ作为自变量,梯度上升见下图1,对其求导过程如下2图:
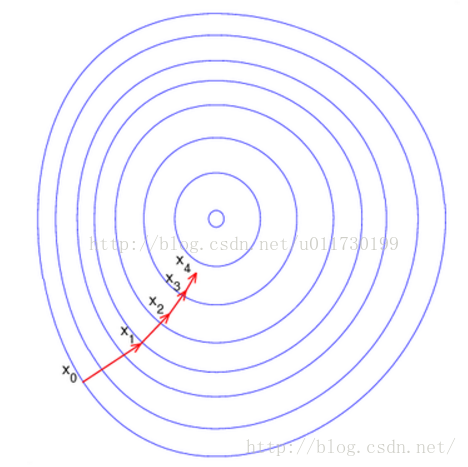
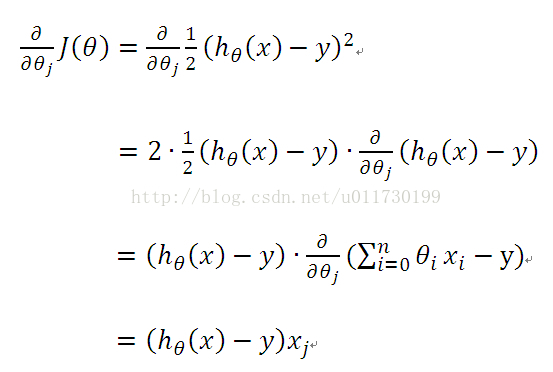
上面求得改函数对每个θ的偏导数,沿着偏导数的方向是该函数上升最快的方向,当然也会使我们迭代的次数最少。
每次更新θ后,重新得到其偏导数,重新得到上升最快的方向,得到θ的迭代公式为:
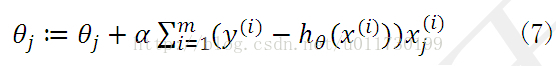
现在我们知道可以不断利用这个迭代公式求得最佳参数θ,使得代价函数最大。现在回过神想想我们要处理什么问题,对,就是分类问题,我们要让函数输出0或1,这种函数瞬间跳跃很难处理,因此我们引进了sigmoid函数:

这里Z=h(x)
程序逻辑:
回归系数(即θ)初始化为1:
迭代N次:
计算数据集的梯度
使用步长x梯度更新回归系数
返回回归系数
从上面我们也可以得到逻辑回归的优点:容易理解,方便计算;缺点:精度可能不那么高,容易欠拟合。
优化算法:因为每次更新回归系数都要遍历整个数据集,数据量大的情况下,效率容易低下,这里可以采用随机梯度上升或
随机梯度下降算法。
基础的数学知识理解后,可能会有些模糊,结合着代码会更深入的了解。具体的代码实现可以参照机器学习实战一书。
http://download.csdn.net/download/u011730199/10007428