given x,want Y = P(y=1|x) Given an input feature vector x maybe corresponging to an image that you want to recognize as cat picture or not a cat picture. More formally ,you want y hat to be the probability of the chance that,y is equal to onr given the input features x,so in other words ,if x =is a picture
output : y, = w(tranfor)x + b -------------------linear function
but it is not a very good algorithm for binary classification .because you want a P(0<=p<=1) between zero and one.
so in logistic regression our output is instead going to be y hat equals the sigmoid function applied to this quantity.
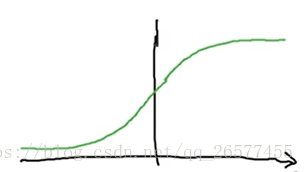
this is the shape of the sigmoid function .label the axes by x and y.
full picture is that :

G(z) = 1/(1+e^(-z))
So ,if Z is very large then E to the negative Z will be close to zero,so the gradien will be close zero. then the learing rates will be slowly.
So,when you implement logistic regression,your job is to try learn parameters W and B
Befor moving on,just anthor note on the notation:
when we programming ,we usually keep the parameter W and parameter B seprrate,here B correponds to an interceptor