目录
Exercise 2: Logistic Regression
Exercise 2: Logistic Regression
需要用到的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn1. Logistic 模型
class Logistic(nn.Module):
def __init__(self):
super(Logistic, self).__init__()
self.linear = nn.Linear(2, 1)
self.sigmoid = nn.Sigmoid()
nn.init.constant_(self.linear.weight, 0)
nn.init.constant_(self.linear.bias, 0)
def forward(self,x):
out = self.linear(x)
out = self.sigmoid(out)
return out因为输入数据的size为100x2,输出数据的size为100x2,故模型为nn.Linear(2, 1)。另外将模型的权重和偏置的值初始化为0。
2. 读取数据
读取数据方法与之前的函数相同详见博客:
https://blog.csdn.net/linghu8812/article/details/88583393
3.Logistic 回归
模型选择之前定义好的Logistic 模型,损失函数选择BCELoss。优化方法选择Adam,也可使用SGD优化方法,但SGD优化方法需要迭代近100万次才收敛,Adam优化方法只需迭代1000次。最后将数据从numpy转换为tensor。
model = Logistic()
criterion = nn.BCELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-1)
X_t = torch.from_numpy(X).type(torch.FloatTensor)
y_t = torch.from_numpy(y).type(torch.FloatTensor)训练模型,迭代1000次,并画出损失函数曲线和分类准确性曲线,最后打印模型的权重和偏置。
train_loss_curve =[]
train_precision_curve =[]
for epoch in range(1000):
model.train()
y_pred = model(X_t)
loss = criterion(y_pred, y_t)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss_curve.append(loss.item())
model.eval()
y_pred = model(X_t).detach().numpy()
y_pred = y_pred > 0.5
precision = np.mean(y_pred == y) * 100
train_precision_curve.append(precision)
print(model.linear.weight)
print(model.linear.bias)最终模型的权重值为0.1359和0.1302,偏置值为-16.3552,损失函数曲线如下图所示。

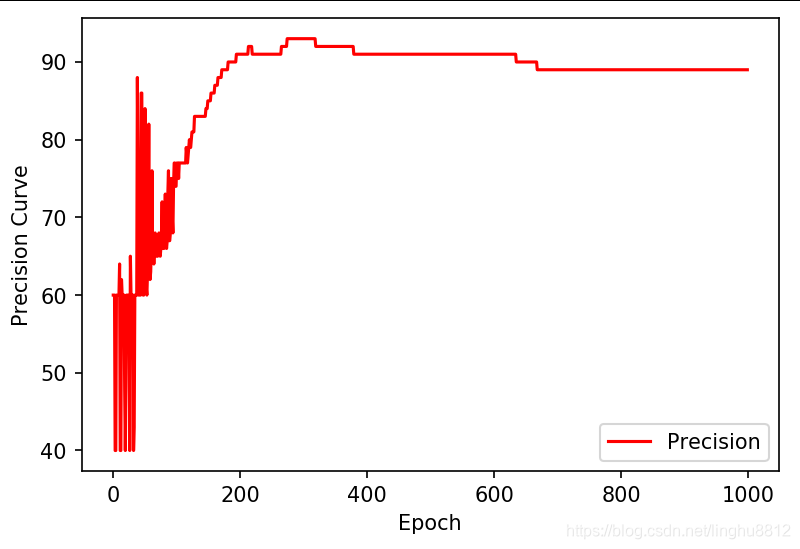
准确率曲线如下图所示,从图中可以看到,迭代到300次左右时准确率可以达到93%,但当损失函数最小时,准确率只有89%。作业中的准确率也只有89%。
Logistic回归结果可视化:

最后对作业中的测试点45分和85分进行测试,结果为0.6962,与作业中的结果0.77不一致,但分类结果一致,均大于0.5。
4.正则化Logistic 回归
对于作业中的第二题,是使用L2正则化方法减小过拟合,数据加载之后分布如下图所示。

使用pytorch进行L2正则化需要在优化器定义中设置weight_decay的值。
optimizer = torch.optim.Adam(model.parameters(), lr=1e-1, weight_decay=1e-5)当weight_decay为0时,训练过程中损失函数和准确率的变化如下图所示。


最终训练集上的准确率为87.5%。不同weight_decay的准确率结果如下表所示。
| weight_decay | 准确率 |
|---|---|
| 0 | 87.5% |
| 1e-5 | 84.7% |
| 2e-5 | 83.9% |
| 5e-5 | 83.9% |
| 1e-4 | 83.9% |
从上表中可以看出,设置了weight_decay之后,在训练集上准确率有所降低,但是如果有测试集的话,准确率可能会提高,使用L2正则化是一种减小过拟合的手段。
