6.1 Classification
预测变量y是离散值情况下的分类问题
Classification
- Email : Spam / Not Spam?
- On-line Transactions : Fraudulent (Yes / No)?
- Tumor : Malignant / Benign ?

Linear regression 可能拟合出的曲线worked well
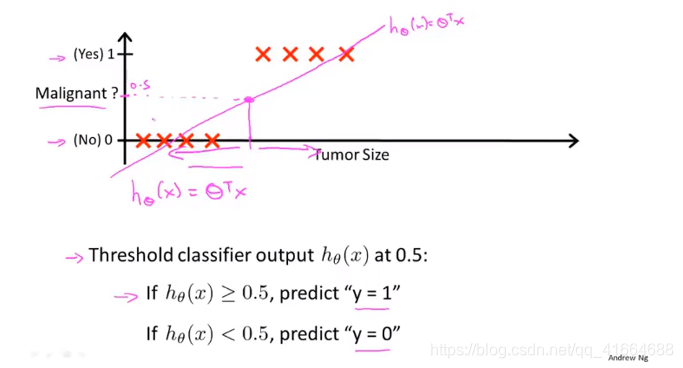
但是,当我们在training set中多加一个实例,就会发现Linear regression 所拟合出来的直线not often a good idea
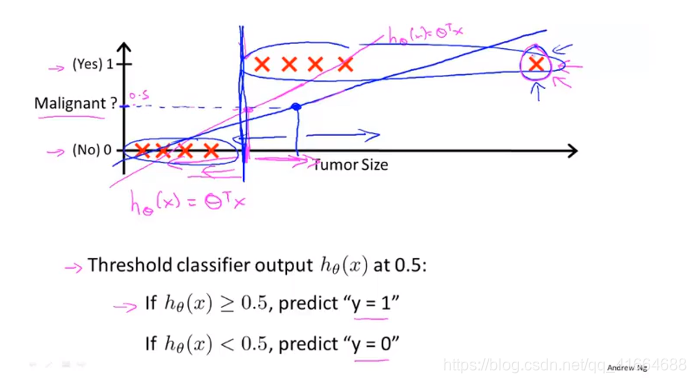
所以,不推荐将Linear regression 用于 classification problems

因此我们引入Logistic regression
Although Logistic regression 名称中有regression, 但实际上这是一个用来处理classification 分类问题的算法
6.2 Hypothesis Representation (假设表示)
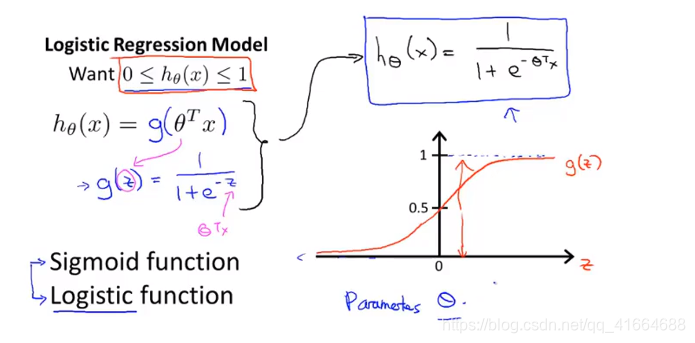

6.3 Decision boundary (决策边界)
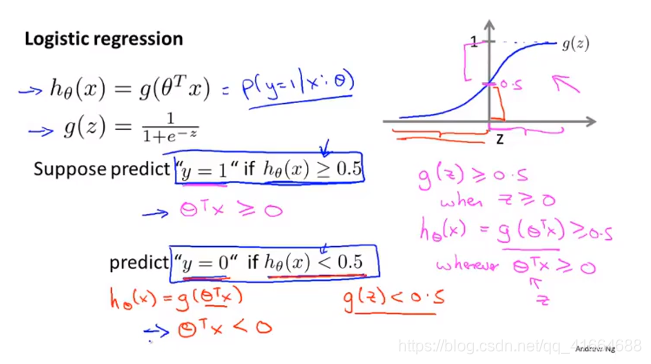
一旦我们有了 , 我们就有了确定的Decision boundary
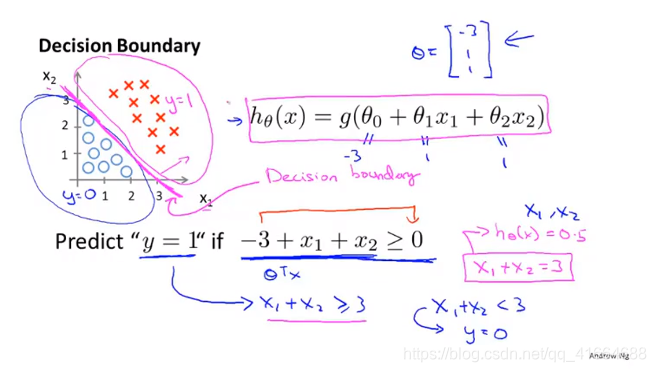

决策边界不是训练集的属性,而是假设本身及其参数的属性,只要给定了参数向量
, 决策边界就确定了
我们用训练集来拟合参数 , 而不是用训练集来定义的决策边界
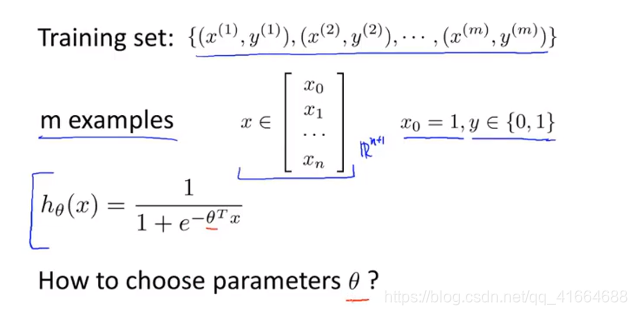
6.4 Cost function
如何拟合参数 ?
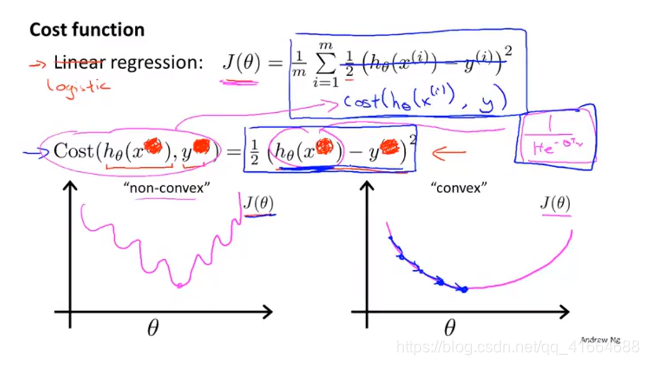
如果仍使用Linear regression 的 cost function, we find that
is a non-convex function ,so 我们要 look up a new cost function, 这样在使用gradient descent 时可以保证只有一个局部最小值
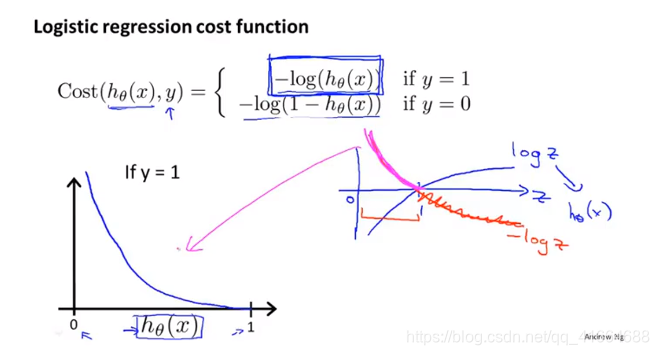
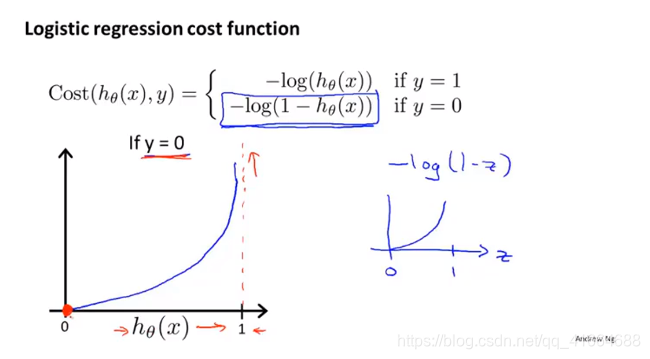
如果
, (即
的概率是1), 则
, 反之,
,(即
的概率是0), 则
(因为此时
).
同理。

6.5 Simplified cost function and gradient descent


最小化代价函数的方法是使用梯度下降法

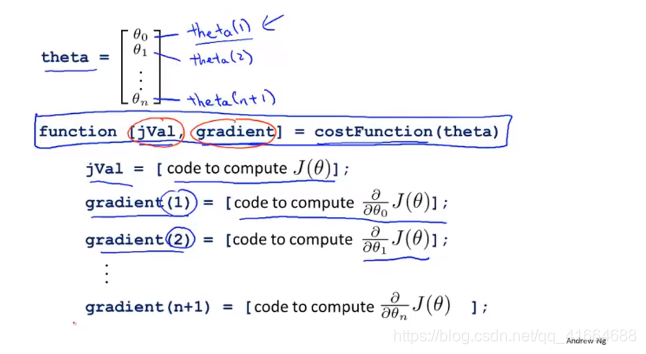
6.6 Advanced optimization
高级优化方法

Conjugate gradient 共轭梯度法
BFGS, L-BFGS都是拟牛顿法的一种

6.7 Multi-class classification : One-vs-all (多类别分类问题)

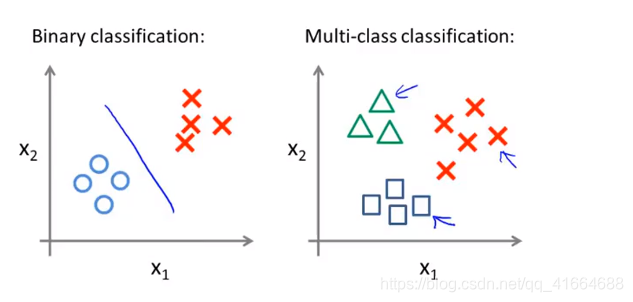
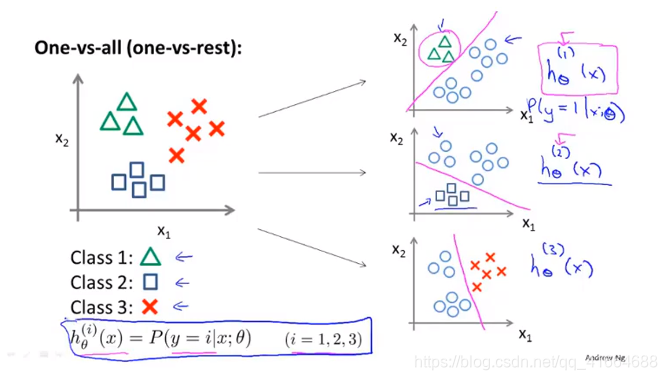
将其分成两个独立的二元分类问题,创建一个新的伪训练集,其中类别2和类别3设定为负类,类别1设定为正类。我们要拟合一个分类器,称其为
.
然后, 我们对类别2进行同样的处理,拟合第二个逻辑回归分类器,称其为 . 对类别3进行同样的处理,拟合第三个逻辑回归分类器,称其为 .

