1. 分治的思想:
先把问题分解为一个个小问题,然后再逐个求解这些小问题,最后再重建原问题的解。
2.归并排序
所谓的归并就是将已经解决的各个小问题的解合并起来得到原问题的解。
归并排序利用分治的思想,将待排序的n个元素分成n/2个子序列,然后将每个子序列排好序,再两两合并再排序,直到最后变成有序序列。
3. 实现方式
在排序算法的实现中,常用的实现方式有两种:
(1)自顶向下的递归法
使用递归调用方式将一个很大的序列切分为一个个很小的序列。
Python 代码实现
def mergeSort(s):
ls = len(s)
if ls <= 1: # 当只有一个元素时停止切分
return s
else:
mid = ls // 2
left_half = mergeSort(s[:mid]) # 递归调用
right_half = mergeSort(s[mid:]) # 递归调用
merged_seq = merge(left_half, right_half) # 合并两个已经排好序的序列
return merged_seq
上面的代码中还有一个merge()没有实现,这也是算法中的难点。
我们如何将两个已经排好序的数组合并成一个有序的数组?
关键是要开辟额外的内存空间。
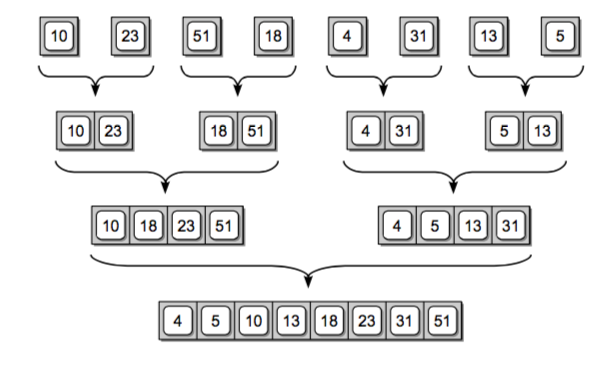
参考下图理解(图片参考这里):
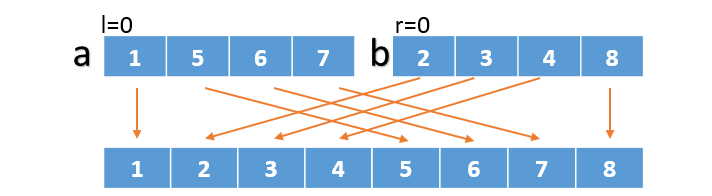
设数组为a,b
给左右两半的数组各设置一个指针,l,r,初始值为0,新建一个数组
当l,r的值小于其对应数组的长度时,只需要比较对应位置上值,然后存放较小的值到新建的数组。
如上图所示,先比较两个数组0位置上的值,分别是1,2, 1<2,, 新的数组第一个位置存放1.
然后左边的数组指针向前移动一位,即l=l+1。继续比较当前l,r索引的值,此时5与2比较,5>2, 2存入数组的第二个位置,右边数组的向右移动一位,即r=r+1;
继续比较当前l,r索引的值5和3,5>3, 3存入数组的第三个位置,右边数组的向右移动一位r = r + 1;
…
当某个数组被遍历,那么剩下的值都从另外一个还没有没有的数组中取。
具体实现如下:
def merge(leftpart, rightpart):
len_leftpart, len_rightpart = len(leftpart), len(rightpart)
l, r = 0, 0
merged_seq = []
while l < len_leftpart and r < len_rightpart:
if leftpart[l] <= rightpart[r]:
merged_seq.append(leftpart[l])
l += 1
else:
merged_seq.append(rightpart[r])
r += 1
while l < len_leftpart and r >= len_rightpart:
merged_seq.append(leftpart[l])
l += 1
while l >= len_leftpart and r < len_rightpart:
merged_seq.append(rightpart[r])
r += 1
return merged_seq
在线调试:这里
上面的代码不是很好?为什么呢?
我们在每次合并两个子序列的时候都新建有一个新的数组或者列表,就是增加了额外的空间。
可以不增加额外的空间开销做到排序。
我们在合并的时候直接传入原来没有被切分的序列,直接在原序列上做修改即可。
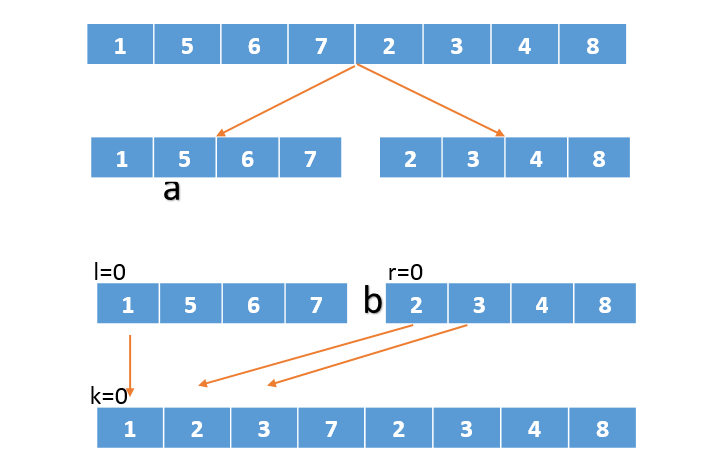
修改的代码不多:
def mergeSort(s):
ls = len(s)
if ls <= 1:
return s
else:
mid = ls // 2
left_half = mergeSort(s[:mid])
right_half = mergeSort(s[mid:])
# merged_seq = merge(left_half, right_half)
merged_seq = merge(s, left_half, right_half)
return merged_seq
def merge(s, leftpart, rightpart):
len_leftpart, len_rightpart = len(leftpart), len(rightpart)
l, r = 0, 0
k = 0
# merged_seq = []
while l < len_leftpart and r < len_rightpart:
if leftpart[l] <= rightpart[r]:
# merged_seq.append(leftpart[l])
s[k] = leftpart[l]
k += 1
l += 1
else:
# merged_seq.append(rightpart[r])
s[k] = rightpart[r]
k += 1
r += 1
while l < len_leftpart and r >= len_rightpart:
# merged_seq.append(leftpart[l])
s[k] = leftpart[l]
k += 1
l += 1
while l >= len_leftpart and r < len_rightpart:
# merged_seq.append(rightpart[r])
s[k] = rightpart[r]
k += 1
r += 1
# return merged_seq
return s
import random
test_seq = list(range(10))
random.shuffle(test_seq)
print(test_seq)
merged_seq = mergeSort(test_seq)
print(merged_seq)
在线调试:这里
(2)自底向上的迭代法
先两个元素两个元素归并;
然后四个四个归并;
再八个八个归并;
…
最后n/2 ,n/2归并。
第一个麻烦:切片的选择
比如第一轮两个两个归并时,使用迭代的方式,第一次归并的切片是seq[0:2], 第二次归并的切片[2:4],…, 直到最后,左右要判断的是右断点和序列长度n的关系,防止所以越界,使用min()去两者中的较小值。
同理当第二轮归并按照上面的类推即可,主要是索引下面的问题。
第二个麻烦: 在原始序列上排序
虽然是在原始序列上排序,但是在排序之前先将原始的切片复制了一份,造成了额外的空间开销。
Python代码实现
其实这里的_merge()函数是可以跟上面的共用,有兴趣的可以看看怎么改成一致。
def mergeSort(seq):
"""
Bottom up merge sort
:param seq: input sequence
:return: None
"""
n = len(seq)
size = 1
while size < n:
j = 0
while j < n:
_merge(seq, j, min(j + size + size, n)) #merge each part of length of 2,4,8..
j += 2 * size
size += size # size = 2, 4, 8,..,2*size
def _merge(seq, left_index, right_index):
"""
inplace merge
:param seq: the original input sequence
:param left_index: the beginning of current slice
:param right_index: the end of current slice
:return: None
"""
aux = seq[left_index:right_index] # copy the current slice to a new list
seq_len = right_index - left_index
mid = seq_len // 2
l, r = 0, mid
for i in range(left_index, right_index): # direct modify the original sequence
if l >= mid and r < seq_len:
seq[i] = aux[r]
r += 1
elif l < mid and r >= seq_len:
seq[i] = aux[l]
l += 1
elif aux[l] <= aux[r]:
seq[i] = aux[l]
l += 1
else:
seq[i] = aux[r]
r += 1
import random
test_seq = list(range(10))
random.shuffle(test_seq)
print(test_seq)
mergeSort(test_seq)
在线调试:这里
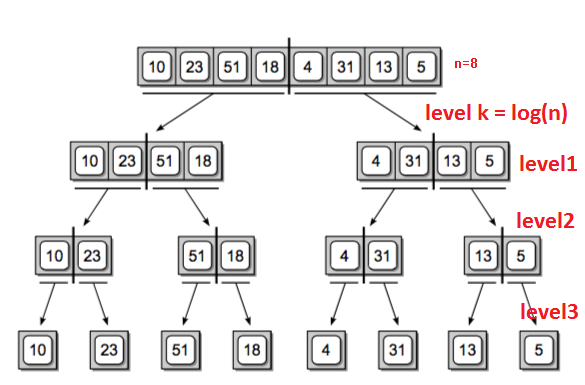
3. nlogn从何而来
归并排序有两个步骤:拆分和归并。
一个长度为n的序列拆分到n个一元序列,能够拆分成log(n) 层;
每层合并操作有 n 次运算:
以n=8 说明,
- 第三层,4 次合并,每次成本是 2 次运算。
- 第二层,2 次合并,每次成本是 4 次运算。
- 第一层,1 次合并,成本是 8 次运算。
所以每一层的操作都是n,有n成,所以有nlogn。