介绍了前面的很多排序算法后,也许你会问是否有一种O(n)复杂度的排序算法呢!答案当然是有的。但是和我们之前看到的算法不一样。前面的算法不管是插入排序,归并排序,还是快速排序,以及堆排序也好,它们都需要比较元素的大小。在导论上有证明了只要是比较排序算法,它的时间复杂度下界是O(nlogn)(当然也存在特例,比如桶排序)。也就是说要想达到O(n)的复杂度,我们必须在不进行比较大小的情况下,将元素排好序。下面我们来看看有哪些算法能做到这一点!
一. 计数排序
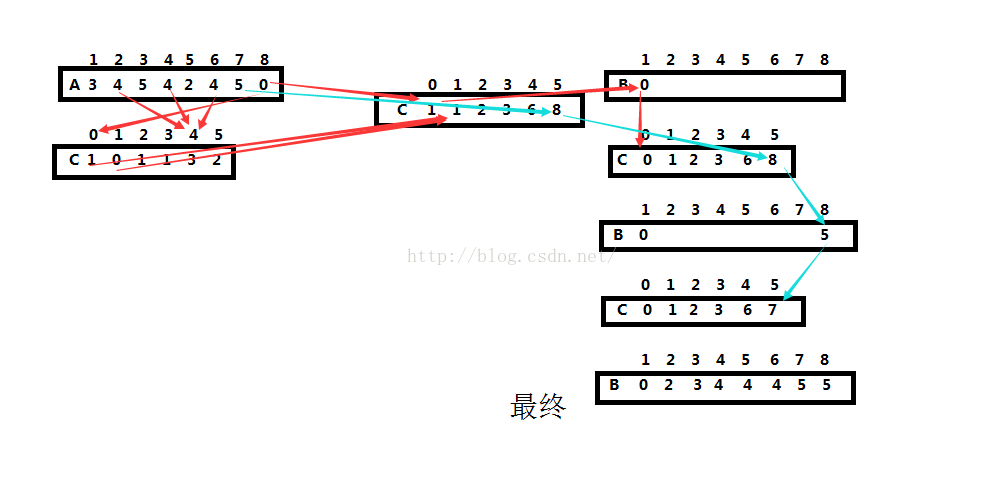
计数排序有一个提前假设,是数值大小与数据的规模成线性关系,并且数值的大小不能过大,不然会花费很大的存储空间,这个是典型的空间换取时间的例子。原理:将要排序的关键字转换成整数形式,范围是0~max,然后创建一个max+1大小的存储数组。然后遍历数据,讲对应存储数组索引位加一。接一下遍历存储数组(这就是为什么要成线性关系),将每一位的数加上前一位的数,这就使得存储数组中每一位中的数是不大于该索引编号的元素个数。然后更加存储数组依次将数据放入结果数组中。
听了一大坨也许你晕了,下面我们来根据图看看实现的过程吧!图中A表示数据数组,C表示存储数组,B表示结果数组。可以看到A中元素的大小最大为5,所以C的大小开到6(因为有可能有0元素)。设想一下如果最大元素为10^10,那么C的大小将超大,这就是计数排序的缺点。接下来将A中的元素在C中对应的索引加1。然后处理C数组,这里有人说可以不处理C数组直接输出不是也可以吗?没有元素的地方为0,如果C中元素超过1,说明A中有重复元素,依次输出就可以了啊!但是你可能没有考虑到稳定性的问题,你说相同元素有什么稳定性可言,但是如果每个元素附加了卫星数据呢,一般实际应用中都是有的多,那么这种方式就变得无法处理了。我在网上看到有人讲这种方法说成是桶排序,还不止一位朋友这么说,这里必须强调一下,其本质是简化的计数排序,与桶排序压根没有关系。。。我们接着说,遍历C数组,每个元素加上前一个元素得到的是不大于索引的数据个数,你想想是不是。然后从A数组的末尾,依次更加C数组,将元素放入B数组中,并将C中对于元素减1,因为放好一个了。为什么要从A的末尾开始呢?不可以从前往后吗?不可以,还是稳定性的原因。大家想想就明白了。
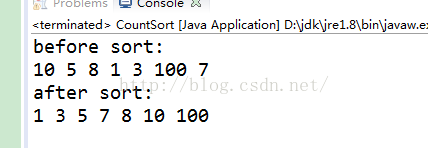
上代码:
package charp_1;
public class CountSort {
public static int[] countSort(int[] a, int k)
{
int[] c = new int[k];
for (int i = 0; i < a.length; i++) {
c[a[i]]++;
}
for (int i = 1; i < c.length; i++) {
c[i] += c[i-1];
}
int[] result = new int[a.length];
//为了保持排序的稳定性必须要反向输出,这样才能保证相同数据下后面的数据一样放在后面
for (int i = a.length-1; i >= 0; i--) {
result[c[a[i]] - 1] = a[i];
c[a[i]]--;
}
return result;
}
public static void main(String[] args)
{
int[] a = new int[]{10, 5, 8 ,1, 3, 100, 7};
System.out.println("before sort:");
QuickSort.print(a);
System.out.println("after sort:");
QuickSort.print(countSort(a, 101));
}
}
二. 基数排序
这个基数排序比较特别,有十分有趣!有两种方式,第一种是先从低位开始,按照低位数字将数据排好序,然后再根据高位排序,最后就完成了。很简单吧!结合图看一下:
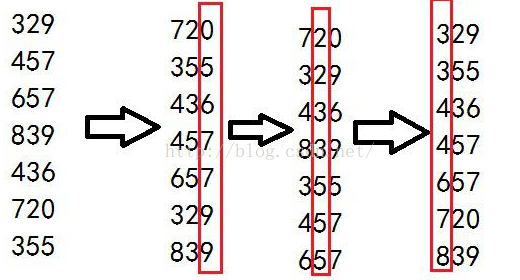
先根据个位排序,然后十位,然后百位,最后就OK了!神奇吧,不过你细想一下就理解了。
还有另一种方法,是从高位往低位走,不过不像第一种那样循环处理,需要递归处理,很费空间,不推荐,所以就不讲了!
我们说了要讲数据按照各位排序,那么按照何种方式排序呢?如果按照插入排序,那么复杂度还会不会是O(N)呢?显然不会。如果按照计数排序,那么才会是O(n)。所以基数排序的复杂度取决于你是按何种方式排序的。
代码如下:
/**
*
*/
package charp_1;
/**
* @author freestyle458
*
*/
public class RadixSort {
public static int[] radixSort(int[] a, int d)
{
for (int i = 0; i < d; i++) {
//返回的是一个新数组,并非原址排序
a = CountSort.countSortForRadix(a, i);
}
return a;
}
public static void main(String[] args)
{
int[] a = new int[]{10, 2, 22, 8, 7, 17, 1233, 889};
System.out.println("before sort:");
QuickSort.print(a);
System.out.println("after sort:");
a = radixSort(a, 4);
QuickSort.print(a);
}
}
运行结果如下:

三.桶排序
这个排序算法其实用到了比较,但是依然是O(n)的复杂度。当然这是期望复杂度,在最差的情况下将不是O(n),这个算法的前提是数据服从平均分布。
原理:我们将数据范围分成几份,或者是几个桶,每个桶中装有特定范围的数据。然后对每个桶内进行插入排序,最后输出结果。


看了图理解一下,很简单吧!
桶排序可以很好的处理小数排序问题,当然计数排序和基数排序做适当的变形,比如同时扩大数据变成全整数等,也可以处理。但是没有桶排序来的方便,因为它根本不关心数据是否为小数,只关心范围。最后的排序交给插入排序。
好了,理解完这三个O(n)算法以后,基本排序的算法我们都了解的。涉及到复杂的数据结构的算法,我们后面再说。
在掌握了伟大的排序思想以后,我们可以很方便地应用的其他问题中,最典型的比如寻找第k个最大或者最小值问题。
四. 寻找最大最小值
最简单的寻找最大最小值问题,一般都会遍历一下,将每个元素与最大最小值比较。但是会发现这不是最好的,因为我们可以只遍历n/2次,每次区一对数据,将较大者与max比较,较小者与min比较。
/**
*
*/
package charp_1;
import javax.swing.plaf.basic.BasicInternalFrameTitlePane.MaximizeAction;
/**
* @author freestyle458
*
*/
public class FindMinMax {
public static void main(String[] args)
{
int[] a = new int[]{10, 2, 22, 8, 7, 17, 1233, 889};
int min = a[0];
int max = a[0];
for (int i = 0; i < a.length; i++) {
int A = a[i];
int B;
if (i == a.length - 1)
B = a[i];
else
B = a[i+1];
if (max < Math.max(A, B))
max = Math.max(A, B);
if (min > Math.min(A, B))
min = Math.min(A, B);
}
System.out.println("the max is " + max);
System.out.println("the min is " + min);
}
}
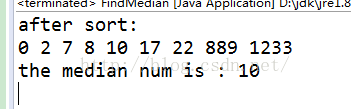
五. 寻找第k个最大或最小值
这个问题就比单纯的寻找最大最小问题复杂一些了。回想快速排序算法的思想,每次去一个元素,然后找出这个元素的真实位置,将数据集一份为2。有了这种思想,我们可以不断的寻找数据的真实位置,如果位置为k的话,那么输出结果,如果不为k,继续寻找,这里只要寻找一边的数据集就可以了,因为我们知道想要的第k的元素属于哪个数据集中。
第k个最大,就是第n-k+1个小,所以一样的处理。这里我们寻找中位数(k = n/2)看看!!!
代码:
/**
*
*/
package charp_1;
/**
* @author freestyle458
*
*/
public class FindMedian {
public static void main(String[] args)
{
int[] a = new int[]{10, 2, 22, 0, 8, 7, 17, 1233, 889};
System.out.println("after sort: ");
QuickSort.print(RadixSort.radixSort(a, 4));
System.out.println("the median num is : " + findMedian(a));
}
public static int findMedian(int[] a)
{
//都采用下中位数,不区别奇偶
int medianIndex = (a.length + 1) / 2 - 1;
return findKth(a, 0, a.length-1, medianIndex);
}
private static int findKth(int[] a, int p, int r, int k)
{
if (p == r)
return a[p];
else {
int q = partition(a, p, r);
if (q == k)
return a[q];
else if (q < k) {
return findKth(a, q+1, r, k);
} else {
return findKth(a, p, q-1, k);
}
}
}
private static int partition(int[] a, int p, int r)
{
int key = a[r];
int i = p - 1;
for (int j = p; j < r; j++) {
if (a[j] < key){
i++;
QuickSort.swap(a, i, j);
}
}
QuickSort.swap(a, i+1, r);
return i+1;
}
}
运行结果:
排序算法至关重要,所以希望各位朋友掌握扎实,有很多优秀的思想都是由排序算法变种而来。
最后让我们欣赏一下各个排序算法随着数据集的增大,时间消化程度吧!
