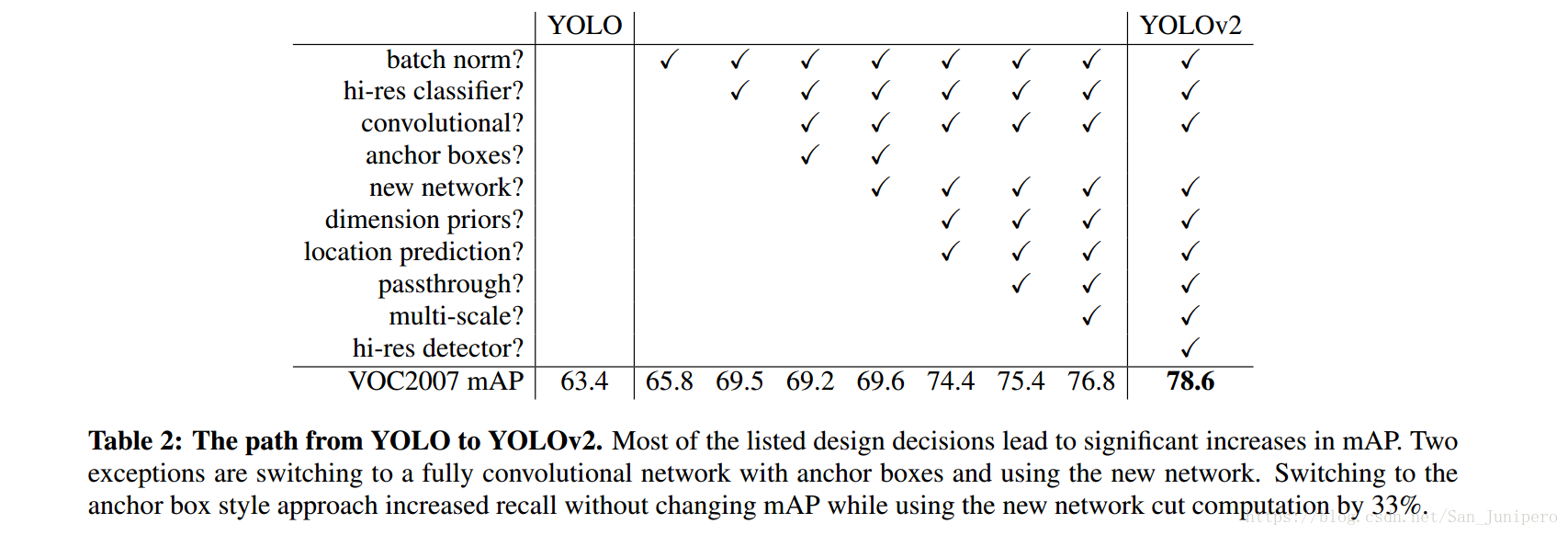
YOLO缺点
- 和rcnn系列相比,定位错误会多一些。毕竟是一步回归,难免准确率会下降一些。
- 此外YOLO比基于region proposal的RCNN系列有更低的recall。recall即预测框和ground truth的比率。
准确度改进
Batch normalize
可以在不采用其他正则化方法的情况下,减小过拟合,并促进收敛。
其加在每一层的后面,把层间输出标准化。

可以把sigmoid函数的边缘值,通过标准化拉到中间部分。
比如,在-4到-6之间,其值逼近与0,,处于梯度饱和区,其梯度变化极慢。如果能把其拉到0左右,又能使其维持比较高的梯度变化,促进收敛。
cite
Batch normalize : https://www.cnblogs.com/guoyaohua/p/8724433.html
High Resolution Classifier
采用高分辨率图片输入detection网络。这样的话,大多数网络需要重新适应YOLO的网络输入。
Convolutional With Anchor Boxes
YOLO里使用全连接层预测边界框,YOLOv2使用anchor boxes替代该方法预测bounding box。
anchor boxes略微降低了mAP,但提高了recall。为自己留出了更多可提升的空间。 = =
Dimension Clusters
用anchor boxes的时候,遇到了两个问题。一个是box dimensions是人工挑选的。人工选尺寸太费劲,选的还不一定好。
所以这里使用k均值算法,自动挑出比较好的先验尺寸。
而标准的K均值算法,使用欧式距离。但欧氏距离,其尺寸越大的框会比尺寸小的框产生更多的错误。所以这里需要使用一个和尺寸无关的算法。
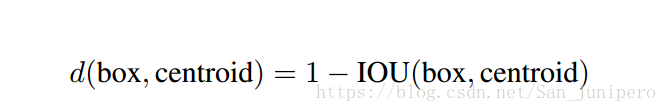
结果是,anchor box里有比较少的短的宽的框,而有更多的高的,瘦的框。
首先,减去卷积层后面的池化层,这样能输出更高分辨率的结果。
然后,把网络缩成416*416,则其中心是一个cell,而不是2*2的中心区域。
Direct location prediction
anchor boxes遇到的第二个问题就是:模型的不稳定。尤其是在早期的迭代过程中。其不稳定性也主要来自于预测出来的x,y值的不稳定。
这里采用和YOLO类似的思路,不使用x,y的offset。而采用location坐标和cell坐标的相对关系。
其针对每个cell在feature maps预测五个box,每个box包括五个元素。tx,ty,tw,th,to。
Fine-Grained Features
Multi-Scale Training
因为anchor boxes机制的加入,模型的输入从448*448改成了416*416,这样其中心能得到一个单cell来预测物体,而不是中间的四个cell一起预测。
因为模型只用了卷积层和池化层,所以其可以在fly过程中resize。
不同于固定输入图像大小,YOLOv2通过每过10个batches,就resize网络大小,其规模在320到608之间,以32为间隔。
速度改进
- 用Googlenet取代VGG16,效果更好,且计算效率更高。
- darknet-19。
健壮改进
针对分类和检测一套处理。
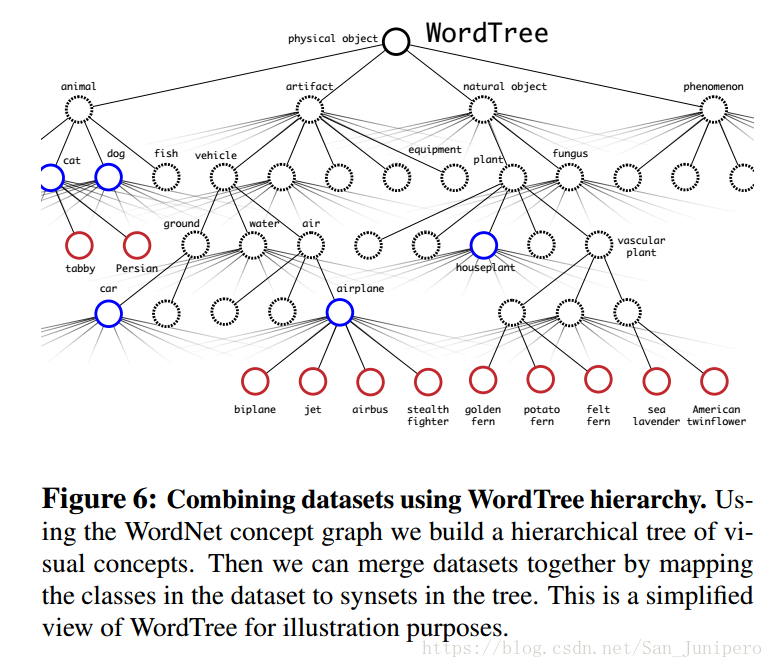
通过建立多标签模型结合数据集。
WordNet,一个有向图而不仅仅是颗树。
计算哪一类的概率,使用条件概率。狗的条件下是猎狗的概率,是猎狗的条件下是terrier的概率。
如果遇到一条狗,它不确定是什么狗,它就只输出狗。
论文提到的点
- 计算机视觉领域,网络模型越大,越深,其性能就可能越好。
- 多个模型的聚合处理也能提升性能。不过这两个方法较为笨重。
- 数据增量方法:随机裁剪,旋转,色调,饱和度,和曝光变化