版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_20095389/article/details/86649888
文章目录
YOLOv2从三个方面改进
论文地址:https://arxiv.org/abs/1612.08242
博文参考:https://blog.csdn.net/u014380165/article/details/77961414
Better
Batch Normalization
- BN可以将数据的分布归一化,有利于网络收敛。即使去掉了YOLOv1的dropout,也不会发生过拟合现象。BN可以将数据的分布归一化,有利于网络收敛。即使去掉了YOLOv1的dropout,也不会发生过拟合现象。
High Resolution Classifier
- 将原来的pre-train只利用224x224 ImageNet输入做训练,训练部分只利用448x448 Pascal 做输入改为:224x224的pre-train(和原来一样) + 448x448的pre-train(10个epochs)。
- 这样做的目的,是当任务由分类转换到检测时,YOLOv1相当于分辨率和任务两个task都要变化,而YOLOv2分辨率在分类任务上已经变化了一些,因此转换上相对容易一些。所以最终的mAp增加了4%
Convolutional With Anchor Boxes
- 将最后一层全连接层和池化层去掉
- 缩减网络,输入改为416*416,为的是奇数的宽高和唯一的预测中心点。YOLO卷积层下来相当于原图32下采样,所以最后的输出为13x13。
- 每一个anchor box都有分类,置信度。因此YOLOv1总共就预测7x7x2个box框,而yolov2为13x13x9个框
Dimension Clusters
- faster rcnn 采用的是手工的anchor box, 而YOLOv2采用kmeans聚类来获得这些anchors
- kmeans聚类衡量标准不用欧式距离,用IOU评分
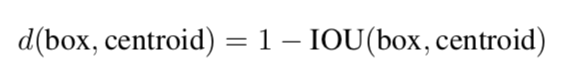
- 选取k=5,5个anchor,作者也同样在文章里列举了选取9的情况,详细见论文

【Direct location prediction】
- 主要是为了解决模型稳定性的问题,从如何改造预测,从而得到更好的loss入手
- YOLOv1 预测的是两个中心点的距离差,???难不成是原来的一个中心点对应4个grid???
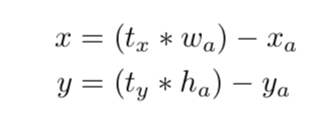
- YOLOv2预测的是中心点坐标和宽高。bx, by, bw, bh 是 预测框(原始图像上)x,y 中心点坐标, 宽,高. tx, ty, tw, th 是网络输出. cx 和 cy 是对应当前网格在原始图像的左上角坐标,pw 和 ph 是anchor框的宽高。


Fine-Grained Features
- 增加一个passlayer,主要是为了解决小目标检测的问题,把26x26那一层的特征图(26x26x512->13x13x2048)和13x13那一层的特征图concate起来。
Multi-Scale Training
- 每隔10个epoch改变图像输入大小,由于整个网络相当于32倍下采样,所以32的倍数作输入{320, 352, … , 608}
- 这种网络训练方式使得相同网络可以对不同分辨率的图像做detection。准确率和训练速度又可以相对平衡
效果
- High Resolution Classifier的提升非常明显(近4%),另外通过结合dimension prior+localtion prediction这两种方式引入anchor也能带来近5%mAP的提升
Faster
Darknet-19
- 作者自己设计了一个新的网络,Darknet-19
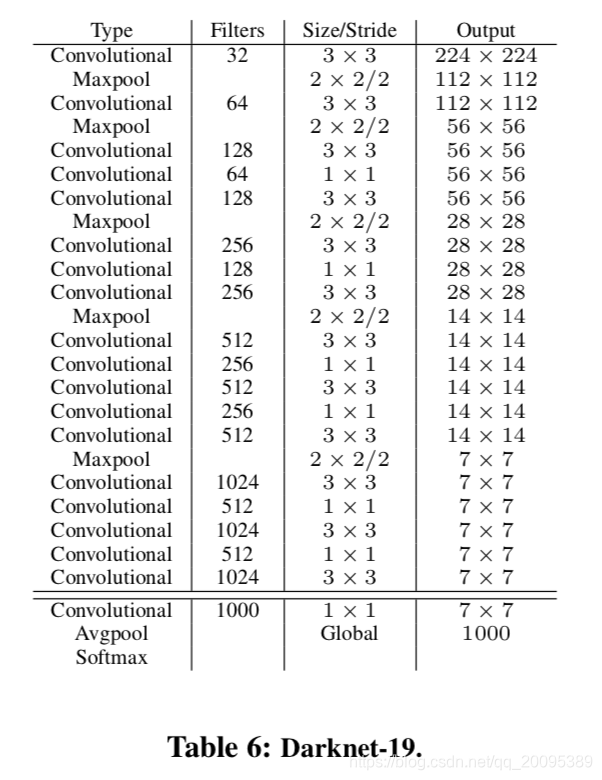
Training for classification
- 第一阶段:160 epochs, imagenet, SGD, lr=0.1, 衰减指数4,权重衰减0.0005,动量0.9,224x224。
- 训练的时候采用了标准的数据增加方式比如随机裁剪,旋转以及色度,亮度的调整。
- 第二阶段:10 epochs, imagemet, SGD, lr=0.001,448x448.
Training for detection
- 去掉最后一层卷积网络,改为3x3x1024的卷既往+1x1xoutput_size。
- 160 epochs, lr=0.001, lr在60和90epochs的时候各除以10。权重衰减0.0005,动量0.9。
Stronger
不是特别理解这块,欢迎互相探讨和指正。
带标注的检测数据集量比较少,而带标注的分类数据集量比较大,因此YOLO9000主要通过结合分类和检测数据集使得训练得到的检测模型可以检测约9000类物体。
一方面要构造数据集(采用WordTree解决),另一方面要解决模型训练问题(采用Joint classification and detection)。
Hierarchical classification
- 这个就是利用wordnet 构词法,把分类和检测数据集融合到一个wordnet tree里。

- 假如预测1369类,detect标签就变成了这个词母类的概率都为1,假设detect出来是哈巴狗,那么狗,动物的概率都为1,vector就可以体现出来了。而最终预测输出是每一个类的概率,那么最终是否某类就利用叠乘法来进行。然后设置一个阈值,判断所到达的具体的某一类。比如detect的类是车,实际上他也是个卡车,那么车概率为1, 卡车概率为0.99,那么最后预测出来那个位置上就是卡车。


Dataset combination with WordTree
- 有了刚才上面介绍的,我们就可以将识别种类扩展到很多,这一步主要是数据集的建立。
Joint classification and detection
- 联合训练,分类数据集只反向传播分类loss的梯度,检测数据集正常反向传播。
- 分类数据集只传播tree上有的,没有的话往上找母类传递。
- To do this we simply find the bound- ing box that predicts the highest probability for that class and we compute the loss on just its predicted tree. We also assume that the predicted box overlaps what would be the ground truth label by at least .3 IOU and we backpropagate objectness loss based on this assumption. (???)这是讲的分类还是检测,第二步说预测框和GT的IOU大于0.3才反向传播,这是什么??