一、概率的性质与运算法则
1.1 基本性质
- 对任一随机事件
,有
- 必然事件的概率为1,而不可能事件的概率为0,即
、
-
若A与B互斥,则
,此性质可推广到多个两两互斥的随机事件
,则
1.2 运算法则
- 加法法则:对于任意两个随机事件,它们和的概率为两个事件分别的概率之和减去两事件相交的概率,即
(特别地,如果A与B互斥,则
,此时
-
乘法公式:
条件概率
与概率
,
有以下关系:
,
另一种形式:
- 独立性:两个事件中不论哪一个事件发生并不影响另一个事件发生的概率,则称这两个事件相互独立。当两个事件相互独立时,其乘法法则可以简化为:
。 多个事件
二、离散型随机变量及其分布
2.1 离散型随机变量
如果随机变量的所有取值都可以逐个列举出来,则称X为离散型随机变量。例如:在一批产品种取到次品的个数。
2.2 离散型随机变量的概率分布
设有一离散型随机变量
,可能取值
,其相应的概率为
,即
,如表所示:
则称该表格形式为离散型随机变量
是

仅在0于1离散点的分布,称为0—1分布。
0—1分布:设离散型随机变量X只可能取0和1两个值,它的概率分布为:
式中,
为常量,
,则称
服从0—1分布。如下表:

2.3 离散型随机变量的期望值和方差
期望值
(
为随机变量X的所有可能取值,
为对应概率)
离散型随机变量
方差:
![\sigma ^{2}=D(X)=E[X-E(X)]^{2}](https://private.codecogs.com/gif.latex?%5Csigma%20%5E%7B2%7D%3DD%28X%29%3DE%5BX-E%28X%29%5D%5E%7B2%7D)
(每一个随机变量取值于期望值的离差平方之期望值)
若
若
,即随机变量以概率1取值
标准差:
期望值反映随机变量
离散系数
用来比较不同期望值的总体之间的离中趋势。

2.4 二项分布和泊松分布
二项分布
实验只有两种结果,这种随机变量所服从的概率分布成为二项分布。比如,“成功”或“失败”,“有”和“没有”。
以
显然

称随机变量
。式中
二项分布的期望值和方差分别为:
泊松分布
泊松分布是用来描述在一指定事件范围内或在指定的面积或体积之内某一事件出现的次数的分布。比较典型的服从泊松分布的随机变量的例子有:在某个企业中每月发生的事故的次数;某种仪器每月出现故障的次数。
泊松分布公式为:
(
为给定的时间间隔内时间的平均数)
泊松分布的期望值和方差分别为:
当成功的概率很小(即
),试验次数很大时,二项分布可近似等于泊松分布,即
三、离散型随机变量及其分布
3.1 连续型随机变量
如果随机变量的所有取值无法逐个列举出来,而是取数轴上某一个区间内的任一点,则称
为连续型随机变量。
3.2 概率密度与分布函数
连续型随机变量可以取某一区间或整个实数轴上的任意一个值,通常用数学函数的形式和分布函数的形式来描述。当用函数来表示连续型随机变量时,我们将
称为概率密度函数。概率密度函数应满足以下两个条件:
(1) (2)
需要指出的时,并不是一个概率,即
,
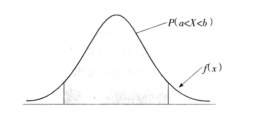
称为概率密度函数,而
在连续分布的条件下为零。在连续分布的情况下以曲线下面的面积表示概率,如随机变量
在
与
之间的概率可以写成
即下图中阴影部分的面积:
连续型随机变量的概率也可以用分布函数来表示,分布函数定义为:
这也是建立在密度函数的基础之上的,因此
也可以写成:
显然,连续型随机变量的概率密度时其分布函数的导数,即
连续型随机变量的期望值与方差分别定义为:
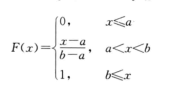
例:设连续型随机变量
内取值,其概率密度为:
试求:(1)分布函数
。 (2)期望值与方差。
解:(1)由分布函数的定义可得
时,
,所以
时,
,所以
时,
所以
(2)
(3)
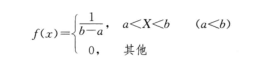
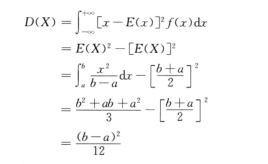
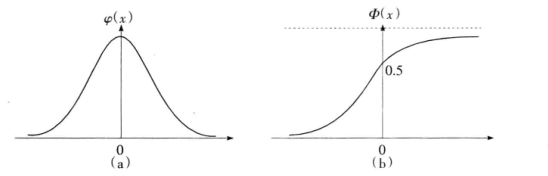
3.3 正态分布
在连续型随机变量中,最重要的一种随机变量时具有钟形概率分布的随机变量,称为正态随机变量,相应的概率分布称为正态分布(normal distribution),如下图:
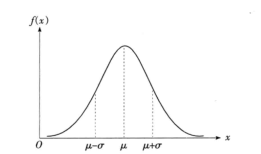
在社会经济问题中,有许多随机变量的概率分布都服从正太分布。例如,某地区同年龄组儿童的发育特征,如身高、体重、肺活量;某公司年销售量等等。
如果随机变量
则称
,其中,
,
,
为随机变量
为随机变量
3.4 标准正态分布
当上式中的,
时,则
相应的正态分布称为标准正态分布(standard normal distribution)。对标准正态分布,通常用
表示概率密度函数,用
表示分布函数,即
标准正态分布的概率密度函数和分布函数
的图形如下(a)和(b)所示: