概率与概率分布
概率是度量偶然事件发生可能性的数值。假如经过多次重复试验(用X代表),偶然事件(用A代表)出现了若干次(用Y代表)。以X作分母,Y作分子,形成了数值(用P代表)。在多次试验中,P相对稳定在某一数值上,P就称为A出现的概率。如偶然事件的概率是通过长期观察或大量重复试验来确定,则这种概率为统计概率或经验概率。
研究支配偶然事件的内在规律的学科叫概率论。属于数学上的一个分支。概率论揭示了偶然现象所包含的内部规律的表现形式。所以,概率,对人们认识自然现象和社会现象有重要的作用。
概率的古典定义
如果一个试验满足两条:
(1)试验只有有限个基本结果;
(2)试验的每个基本结果出现的可能性是一样的。
这样的试验便是古典试验。
对于古典试验中的事件A,它的概率定义为:,其中n表示该试验中所有可能出现的基本结果的总数目。m表示事件A包含的试验基本结果数。这种定义概率的方法称为概率的古典定义。
古典概率局限在随机试验只有有限个可能结果的范围内,这使其应用受到了很大限制。因此,人们又提出了根据某一事件在重复试验中发生的频率来确定其概率的方法,即概率的统计定义。
概率的统计定义
在相同的条件下随机试验n次,某事件A出现m次(),则比值
称为事件A发生的频率。随着n增大,该频率围绕某一常数p上下波动,且波动的幅度逐渐减小,趋于稳定,这个频率的稳定值即为该事件的概率,记为:
例子:

随机事件及其概率
在一定的条件下可能发生也可能不发生的事件,叫做随机事件。
通常一次实验中的某一事件由基本事件组成。如果一次实验中可能出现的结果有n个,即此实验由n个基本事件组成,而且所有结果出现的可能性都相等,那么这种事件就叫做等可能事件。
互斥事件:不可能同时发生的两个事件叫做互斥事件。
对立事件:即必有一个发生的互斥事件叫做对立事件。
在一个特定的随机试验中,称每一可能出现的结果为一个基本事件,全体基本事件的集合称为基本空间。
随机事件(简称事件)是由某些基本事件组成的,例如,在连续掷两次骰子的随机试验中,用Z,Y分别表示第一次和第二次出现的点数,Z和Y可以取值1、2、3、4、5、6,每一点(Z,Y)表示一个基本事件,因而基本空间包含36个元素。“点数之和为2”是一事件,它是由一个基本事件(1,1)组成,可用集合{(1,1)}表示,“点数之和为4”也是一事件,它由(1,3),(2,2),(3,1)3个基本事件组成,可用集合{(1,3),(3,1),(2,2)}表示。
如果把“点数之和为1”也看成事件,则它是一个不包含任何基本事件的事件,称为不可能事件。P(不可能事件)=0。
在试验中此事件不可能发生。如果把“点数之和小于40”看成一事件,它包含所有基本事件,在试验中此事件一定发生,称为必然事件。P(必然事件)=1。实际生活中需要对各种各样的事件及其相互关系、基本空间中元素所组成的各种子集及其相互关系等进行研究。
离散型随机变量及其分布
随机变量的定义
随机变量(random variable)表示随机试验各种结果的实值单值函数。随机事件不论与数量是否直接有关,都可以数量化,即都能用数量化的方式表达。简单地说,随机变量是指随机事件的数量表现。例如掷一颗骰子出现的点数,电话交换台在一定时间内收到的呼叫次数,随机抽查的一个人的身高,悬浮在液体中的微粒沿某一方向的位移,等等,都是随机变量的实例。
在做实验时,常常是相对于试验结果本身而言,我们主要还是对结果的某些函数感兴趣。例如,在掷骰子时,我们常常关心的是两颗骰子的点和数,而并不真正关心其实际结果,就是说,我们关心的也许是其点和数为7,而并不关心其实际结果是否是(1,6)或(2,5)或(3,4)或(4,3)或(5,2)或(6,1)。我们关注的这些量,或者更形式的说,这些定义在样本空间上的实值函数,称为随机变量。
因为随机变量的值是由试验结果决定的,所以我们可以给随机变量的可能值指定概率。
随机变量可以划分为离散型随机变量和连续型随机变量。
离散型
离散型(discrete)随机变量即在一定区间内变量取值为有限个或可数个。
例如某地区某年人口的出生数、死亡数,某药治疗某病病人的有效数、无效数等。
离散型随机变量通常依据概率质量函数分类,主要分为:伯努利随机变量、二项随机变量、几何随机变量和泊松随机变量。
连续型
连续型(continuous)随机变量即在一定区间内变量取值有无限个,或数值无法一一列举出来。
例如某地区男性健康成人的身长值、体重值,一批传染性肝炎患者的血清转氨酶测定值等。
有几个重要的连续随机变量常常出现在概率论中,如:均匀随机变量、指数随机变量、伽马随机变量和正态随机变量。
离散型随机变量的概率分布


离散型随机变量的期望和方差
离散型随机变量常见的分布
- 0-1分布
- 二项分布(伯努利分布)
- 泊松分布
0-1分布
随机变量只可能取0与1两个值,它的分布律是:
![]()
或拆开写为
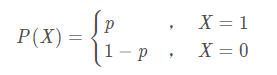
分布律表格是:
二项分布(伯努利分布)
伯努利分布指的是对于随机变量X有, 参数为p(0<p<1),如果它分别以概率p和1-p取1和0为值。EX= p,DX=p(1-p)。伯努利试验成功的次数服从伯努利分布,参数p是试验成功的概率。伯努利分布是一个离散型机率分布,是N=1时二项分布的特殊情况,为纪念瑞士科学家詹姆斯·伯努利(Jacob Bernoulli 或James Bernoulli)而命名。
伯努利试验
如果无穷随机变量序列……,
是独立同分布(i.i.d.)的,而且每个随机变量
都服从参数为
的伯努利分布,那么随机变量
……,
就形成参数为
的一系列伯努利试验。同样,如果
个随机变量
……,
独立同分布,并且都服从参数为
的伯努利分布,则随机变量
……,
形成参数为
的
重伯努利试验。
下面举几个例子加以说明,假定重复抛掷一枚均匀硬币,如果在第次抛掷中出现正面,令
;如果出现反面,令
,那么,随机变量
……,
就形成参数为
的一系列伯努利试验,同样,假定由一个特定机器生产的零件中10%是有缺陷的,随机抽取
个进行观测,如果第
个零件有缺陷,令
;如果没有缺陷,令
,那么,随机变量
……,
就形成参数为
的
重伯努利试验。

泊松分布
随机变量可能取的值为0,1,2,⋅⋅⋅,取各个值的概率为:

其中是泊松分布的数学期望或方差(泊松分布的数学期望和方差相等,都等于参数
),则称
服从参数为
的泊松分布,记为:
~
。
泊松分布只有一个参数。
连续型随机变量的概率分布

由于连续型随机变量可以取某一区间或这个实数轴上的任意一个值,所以我们不能像对离散型随机变量那样列出每一个值及其相应的概率,而必须采用其他方法,通常用数学函数和分布函数的形式来描述。当用函数来表示连续型随机变量时,我们将
称为概率密度函数(Probability Density Function)。

需要指出的是, 并不是一个概率,即
,
称为概率密度函数,而
在连续分布的条件下为零。在连续分布的情况下,以曲线下的面积表示概率,如随机变量X在a与b之间的概率可以写为:
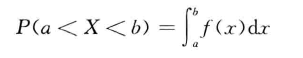
即下图中阴影的面积:

连续型随机变量的期望与方差分别定义为:

连续型随机变量的分布:
- 均匀分布
- 指数分布
- 正态分布
均匀分布

指数分布

正态分布

正态分布的期望值决定了其位置,其标准差
决定了分布的幅度,由最大值公式可以看出,
越小时图形变得越尖,因而
落在
附近的概率越大。

