[深度学习与计算机视觉] 斯坦福 CS231n 2017 学习笔记 -1 (Lecture 1: Introduction;课程介绍)
| VIDEO |
|---|
课程介绍-计算机视觉概述
CS231n 近几年一直是计算机视觉领域和深度学习领域最为经典的课程之一。而最近才刚刚结课的 CS231n Spring 2017 仍由李飞飞带头主讲,并邀请了 Goodfellow 等人对其中部分章节详细介绍。本课程从计算机视觉的基础概念开始,在奠定了基本分类模型、神经网络和优化算法的基础后,重点详细介绍了CNN、RNN、GAN、RL 等深度模型在计算机视觉上的应用。
什么是计算机视觉呢?

顾名思义就针对视觉数据的研究,如今世界上的视觉数据爆炸性增长,很大得益于海量的视觉传感器,2017年,互联网上80%的数据都是视频,所以接下来的问题是如何利用算法去开发、理解、利用这些数据。这里把视频之于互联网比作暗物质之于宇宙,构成了网络传输中的大部分,但却都是难以计算和探测的。还有一个有趣的统计来自youtube,每三秒就能上传5小时的视频数据,所以靠人工来分类、分析、投放广告等是不现实的方法。因此,开发一项技术,使机器能够沉浸式地观测并理解这些视觉数据就显得格外重要。
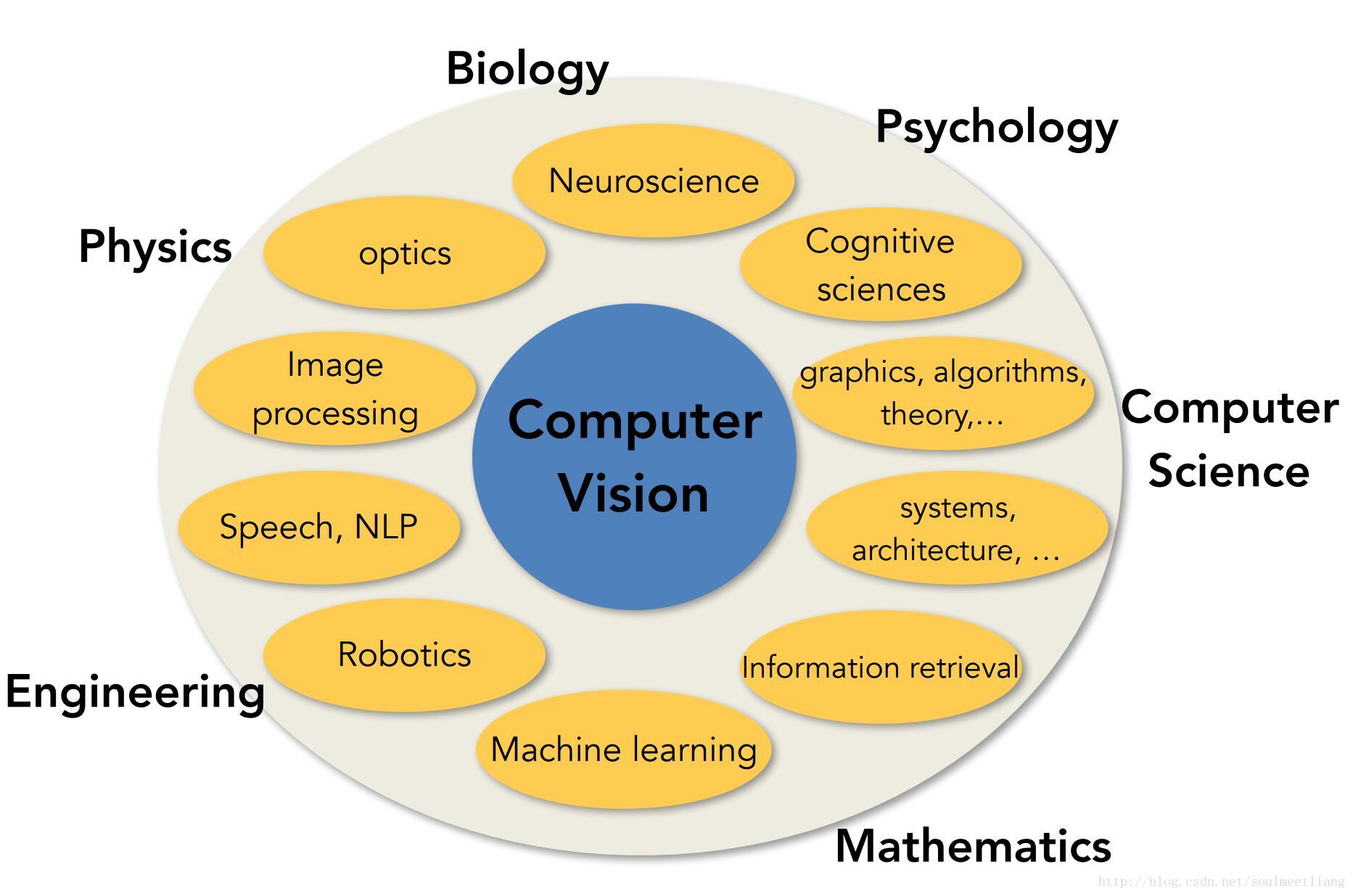
同时计算机视觉也是也交叉学科,围绕它,我们可能会接触到物理学,因为需要光学知识和成像原理,也要理解图像在光学上是如何生成的。我们可能会了解生物学和心理学,去理解动物层面上是如何理解视觉信息的。还可能涉及到计算机科学和工程学,我们在致力实现视觉算法和计算机系统。
计算机视觉历史背景
计算机视觉历史简介
视觉从何而来,我们今天又发展到了那一步呢?

最早的生物都在大海里游荡,没有眼睛更谈不上视觉。但是5亿4千万年前,发生了一件重要的事情,动物种类爆炸性增长,后来称之为物种大爆炸。第一次有动物进化出了眼睛,第一次有了视觉,这大大增进了日后物种的发展历程。随着物种演化,视觉成了大部分动物最重要的感知器官。
那么人类怎样让机器拥有视觉呢?
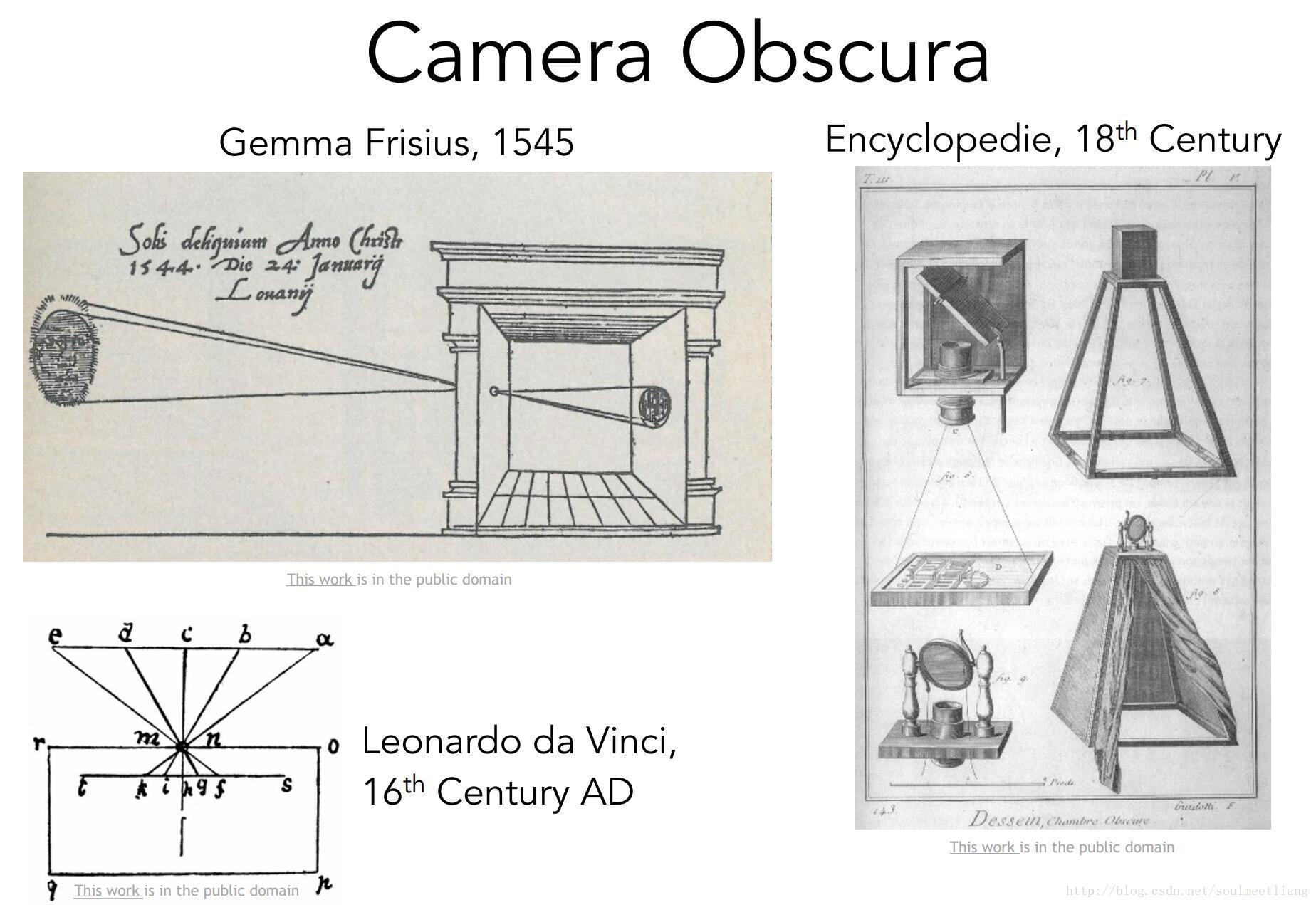
这要追溯到照相机小孔投影成像。
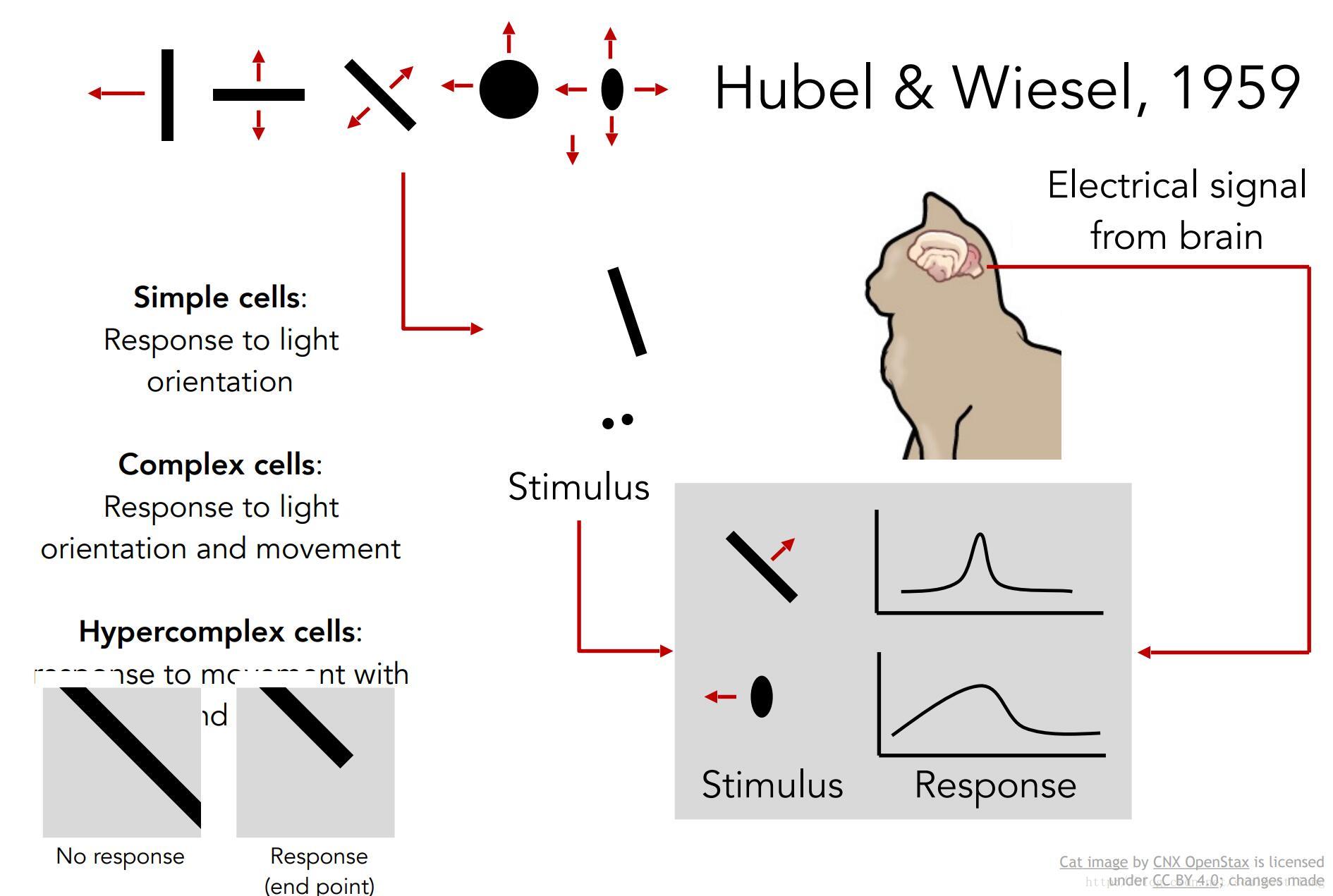
同时生物学家也在研究视觉机理,五六十年代的 Hubel 和 Wiesel使用电生理学研究哺乳动物的视觉处理机制是怎样形成的的,影响了人类视觉、动物视觉,并且启发了计算机视觉的研究。
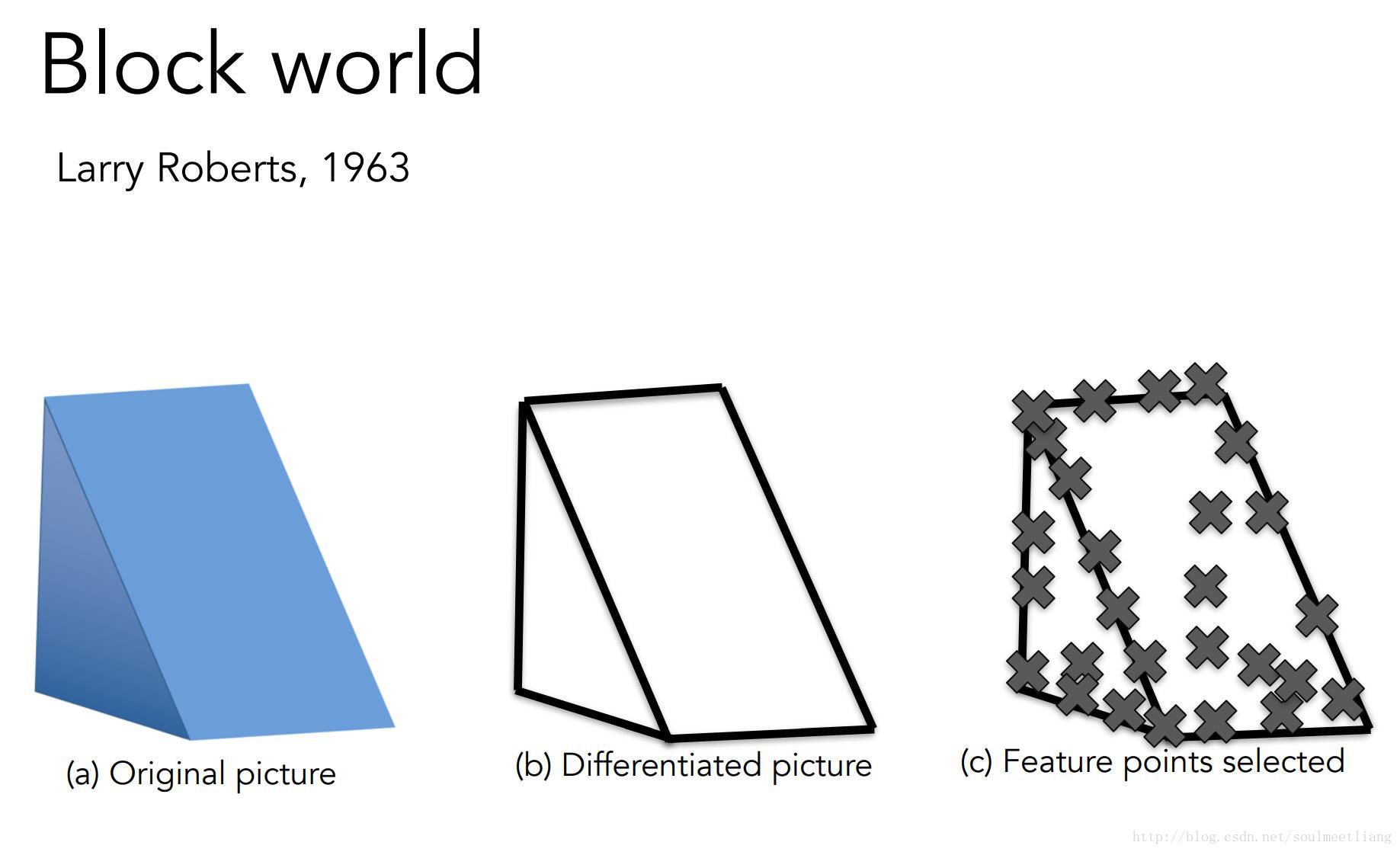
计算机视觉的历史也要从六十年代说起,Larry Roberts 将视觉世界简化为简单的几何形状,这也被认为是计算机视觉的第一篇博士论文。
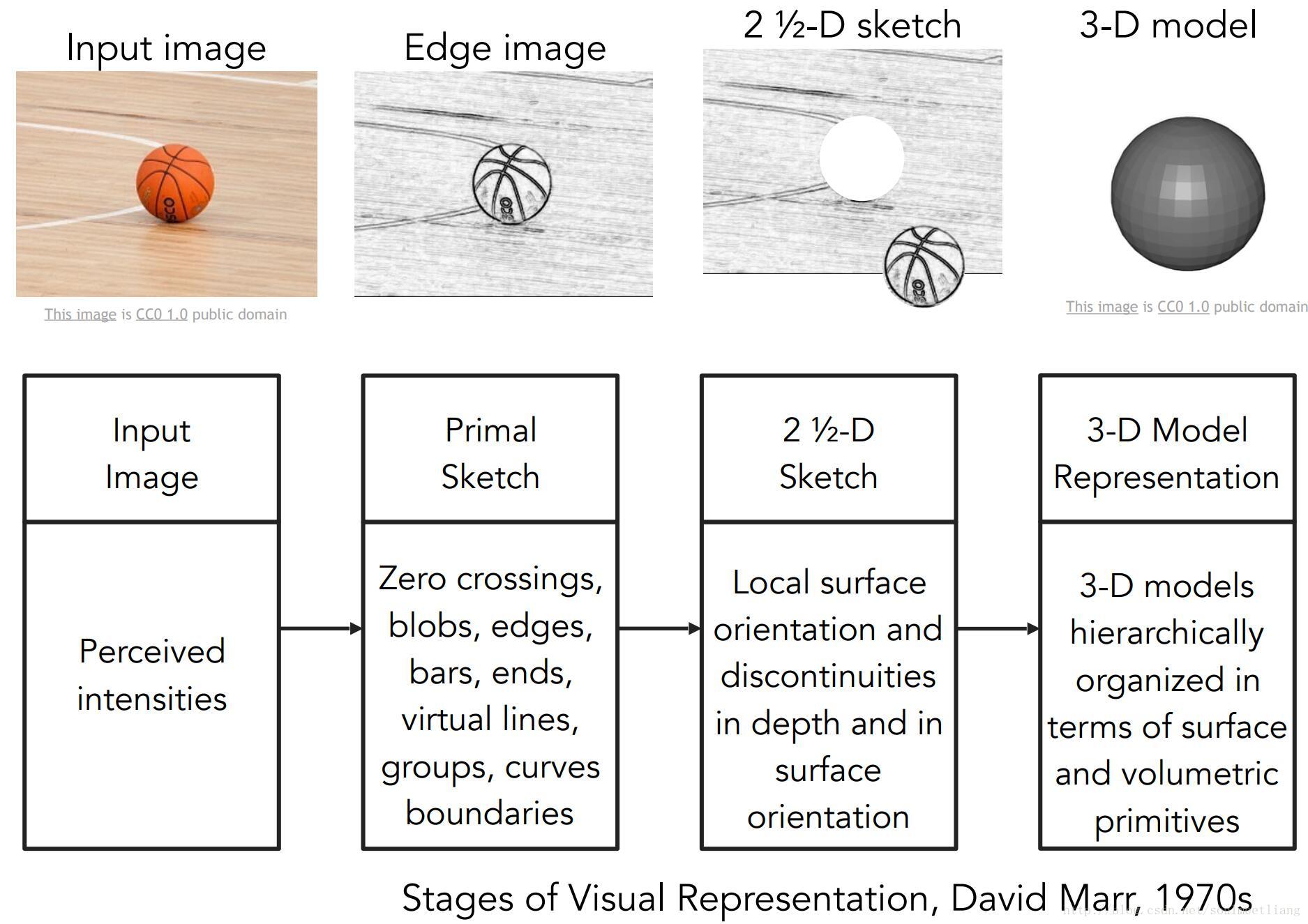
David Marr在《VISION》一书中提出,我们要使拍摄的图像获得全面的 3D 视觉世界,我们必须经过几个过程。
- 原始草图,将大部分边缘、端点、线条、曲线、边界都表示出来。
- 2.5维草图,将以下拼凑在一起: surface、depth information、the layers,the discontinuties of the visual scene。
- 最终,3维模型,将所有内容放在一起,组织起来 物体表面 和 体积图等分层。
(这一块不是很理解求指导)
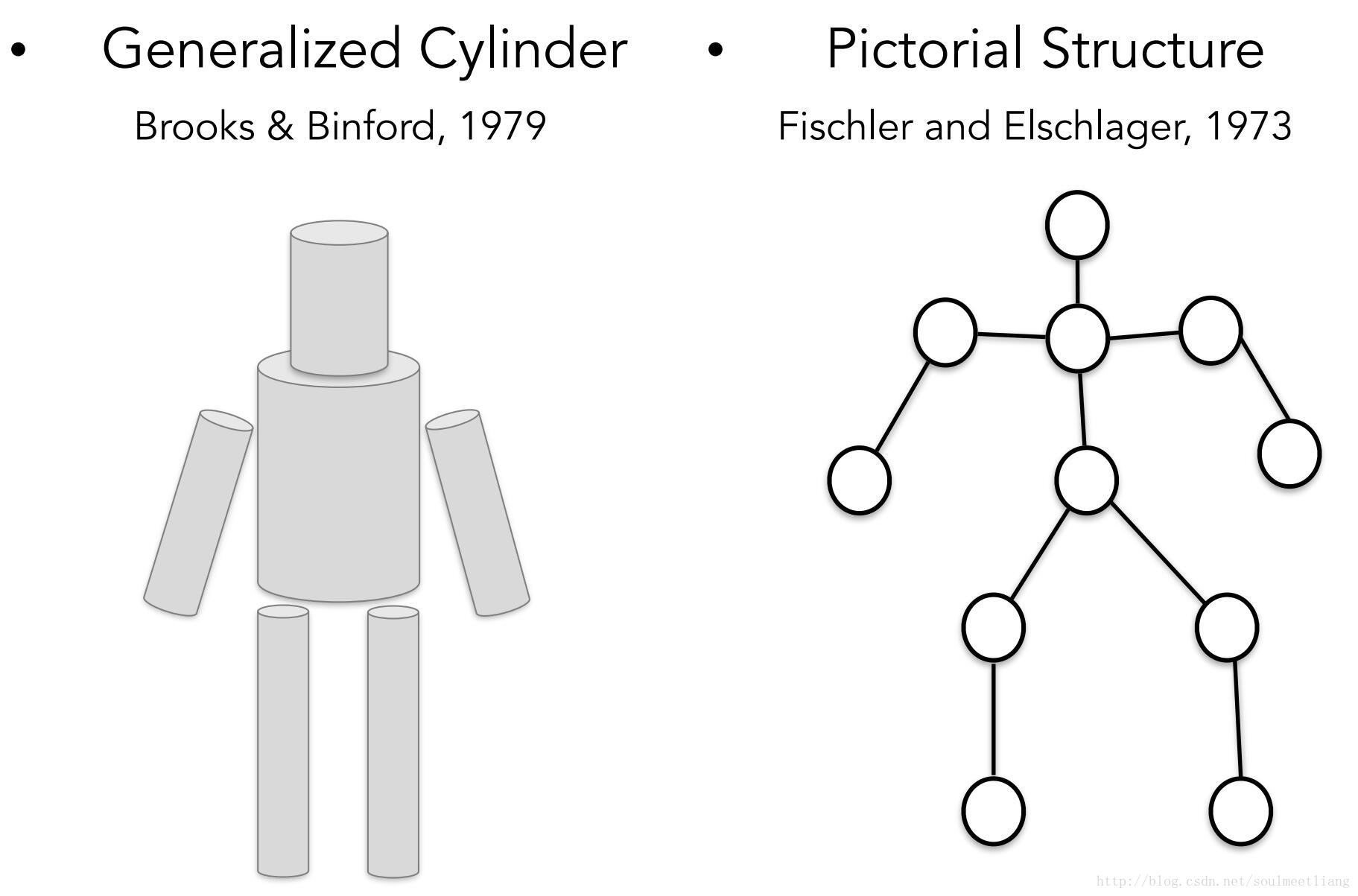
这种思维方式已经影响计算机视觉几十年了,另一个开创性的工作是,越过简单的块状世界,去识别或表示视觉世界的对象。他们的基本思想是每个对象都由简单的几何图单位组成。
目标识别是一项很难的工作,而目标分割相对简单,它的任务就是把一张图片中的像素归类到有意义的区域,这是早期非常有创新型的工作。

在计算机视觉领先发展的是人脸检测,由 Viola & Jones 利用 AdaBoost 算法实现了准确高速的人脸检测,其成果快速转化到了工业界,有了人脸检测相机。
而如何才能做到更好的目标识别,是我们可以继续研究的领域。在九十年代末有一个影响非常深远的思想方法,基于特征的目标识别。

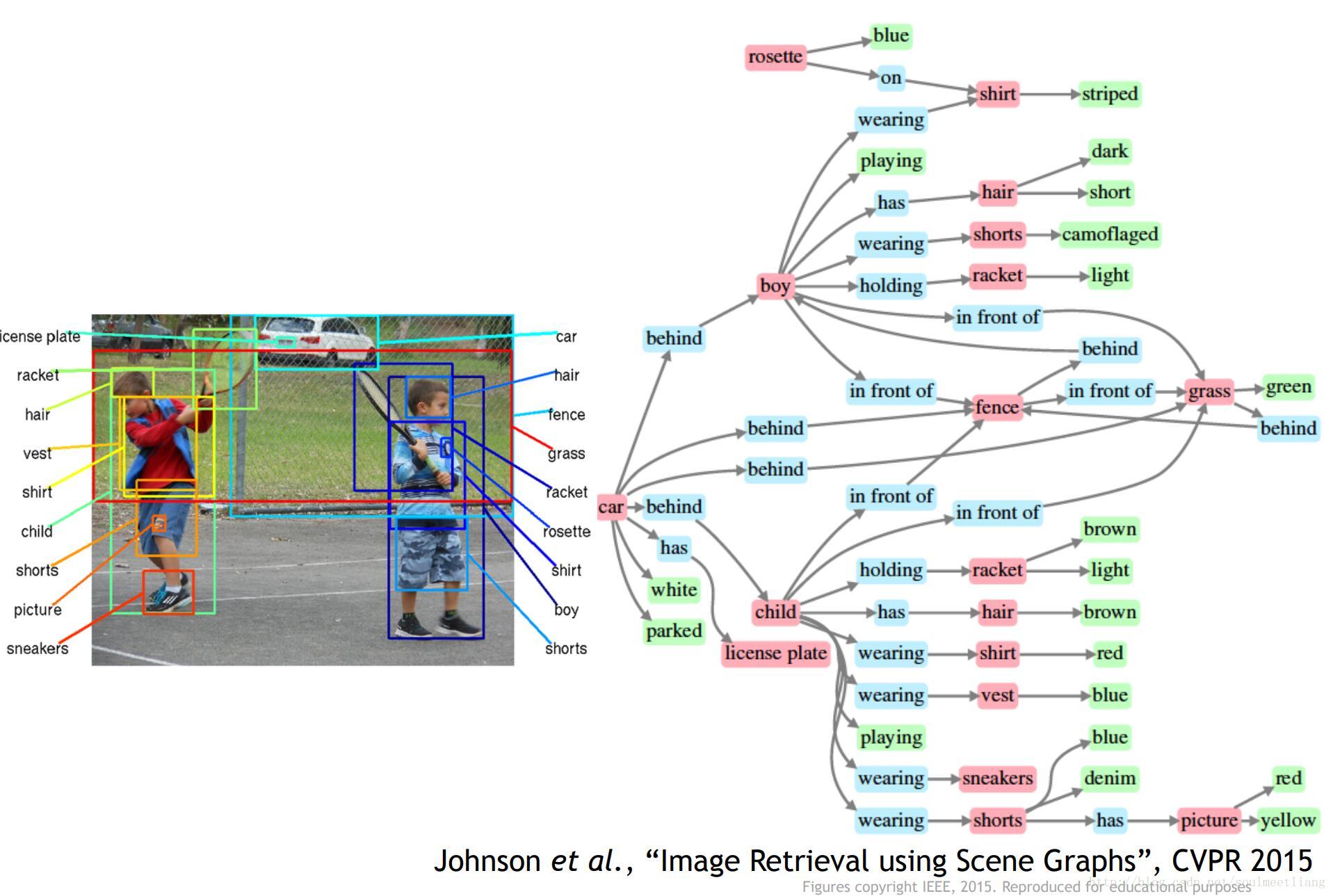
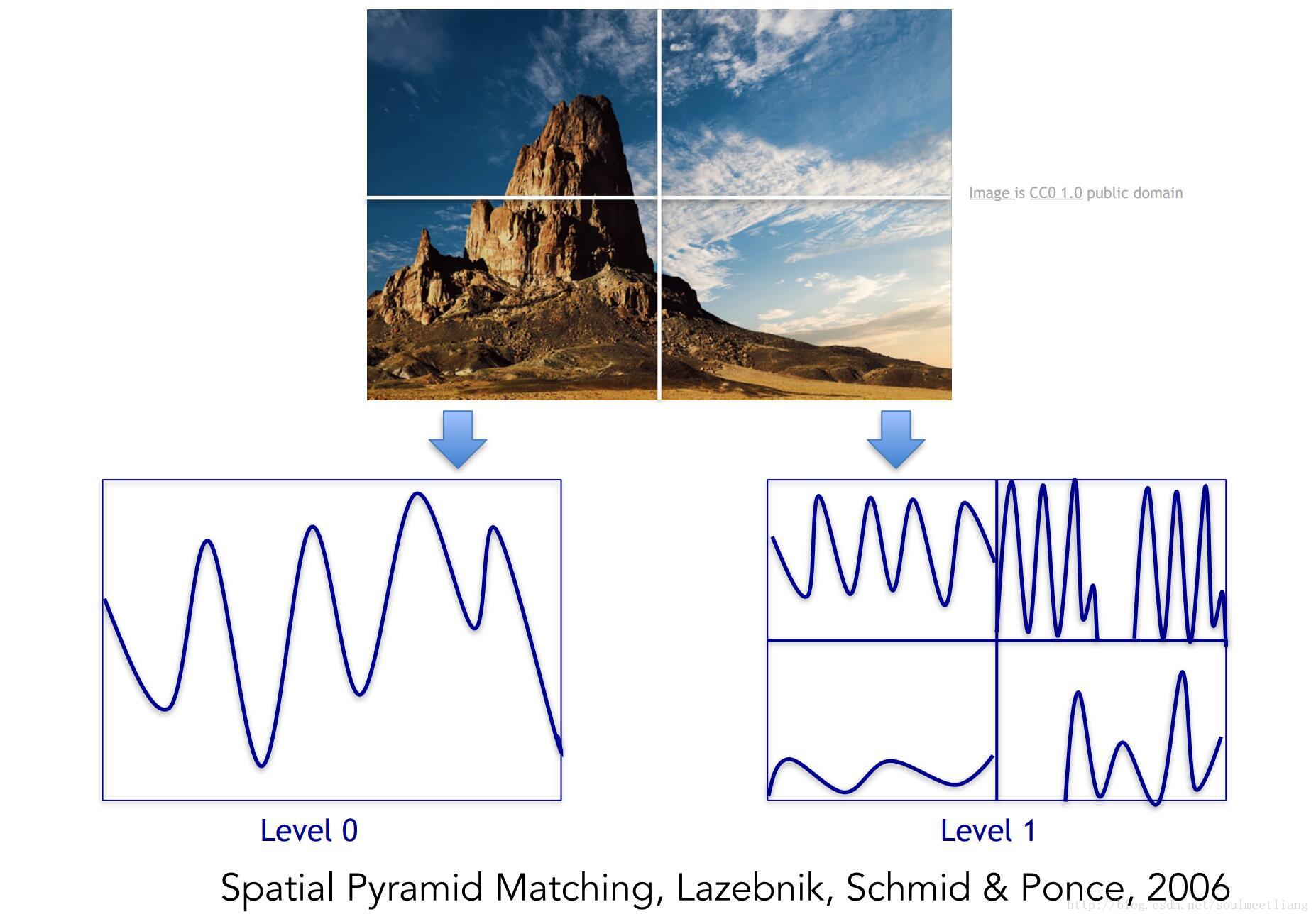
Using the same building block which is features, diagnostic features in image. 在这个领域有一个重要进展是识别整幅图的场景,以一个算法为例,叫空间金字塔匹配(Spatial Pyramid Matching),背后的思想是,图片里有各种特征告诉我们它可能是什么,这个算法从图中的各部分抽取特征,并把他们放在一起作为一个特征描述符(feature descriptor),然后在特征描述符上做一个支持向量机的运算。
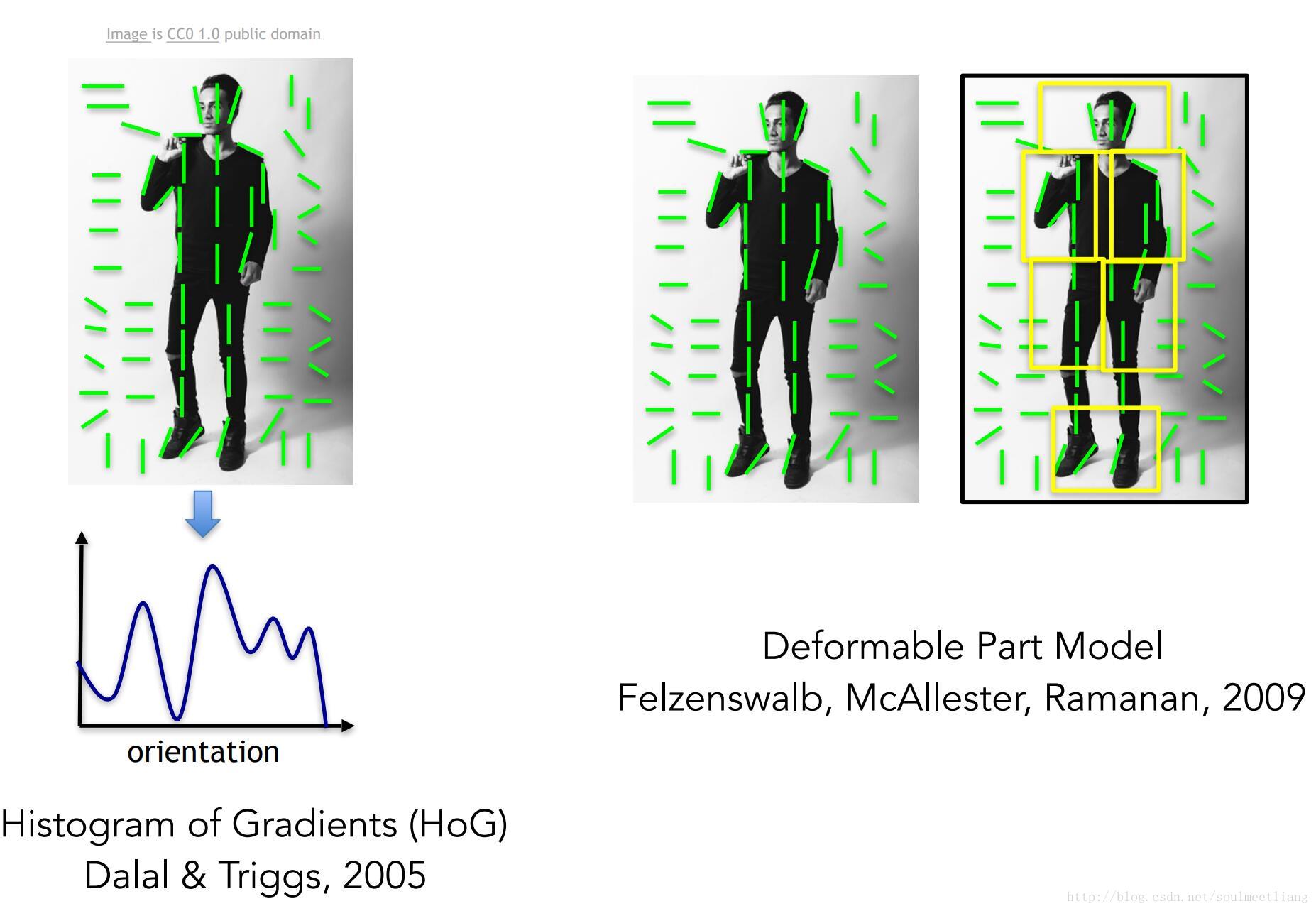
在这个方向上,有一个研究是合理地在图像上构成人体姿态并识别姿态,这被称为 方向梯度直方图(histogram of gradients),另一个被称为 可变形部件模型(deformable part models)。
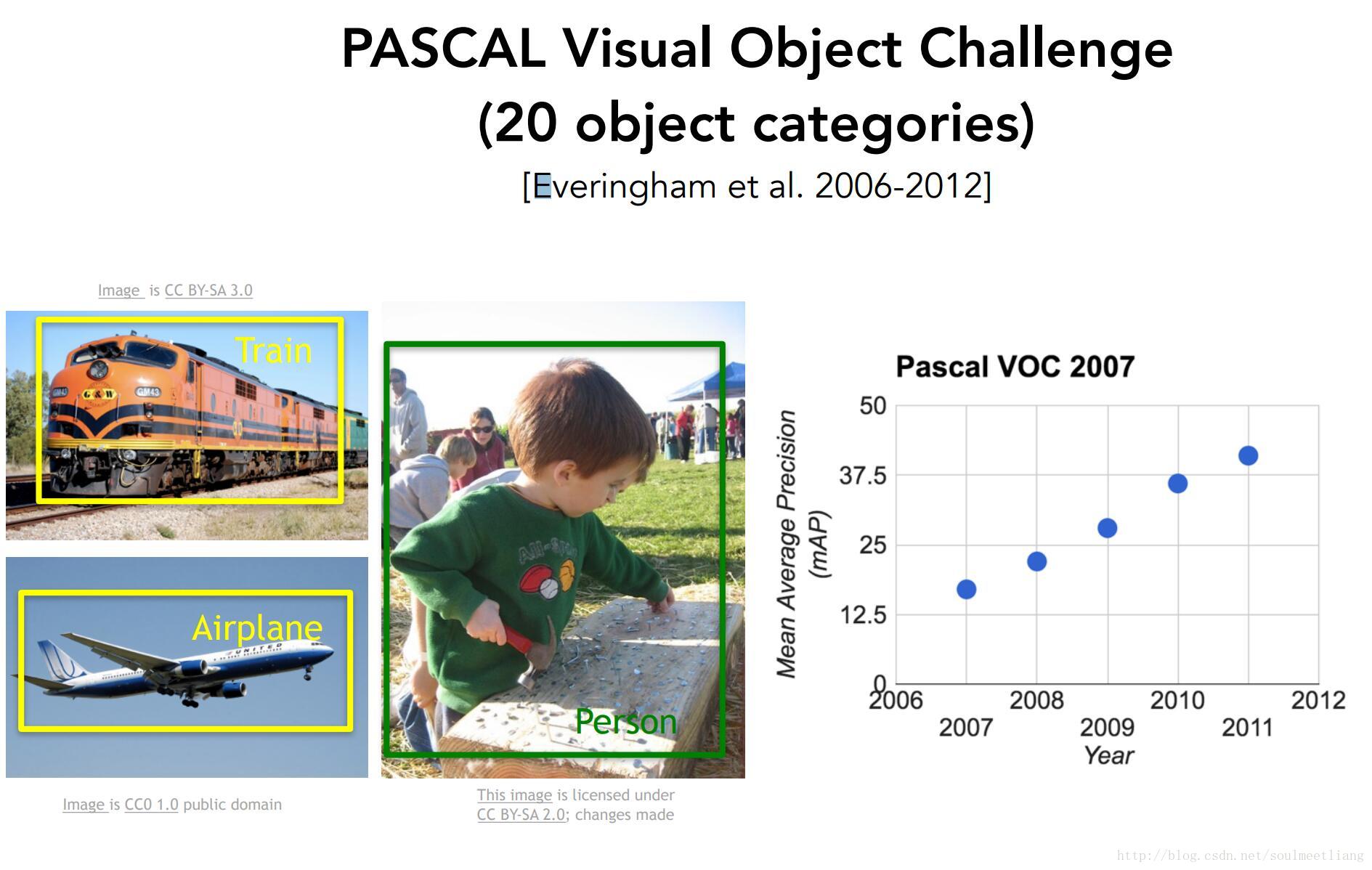
随着计算机视觉的发展,有一个必要解决的问题就是高质量的标注数据里,其中 PASCAL Visual Object Challenge 就是一个非常有影响力的数据集,它拥有二十个类别。
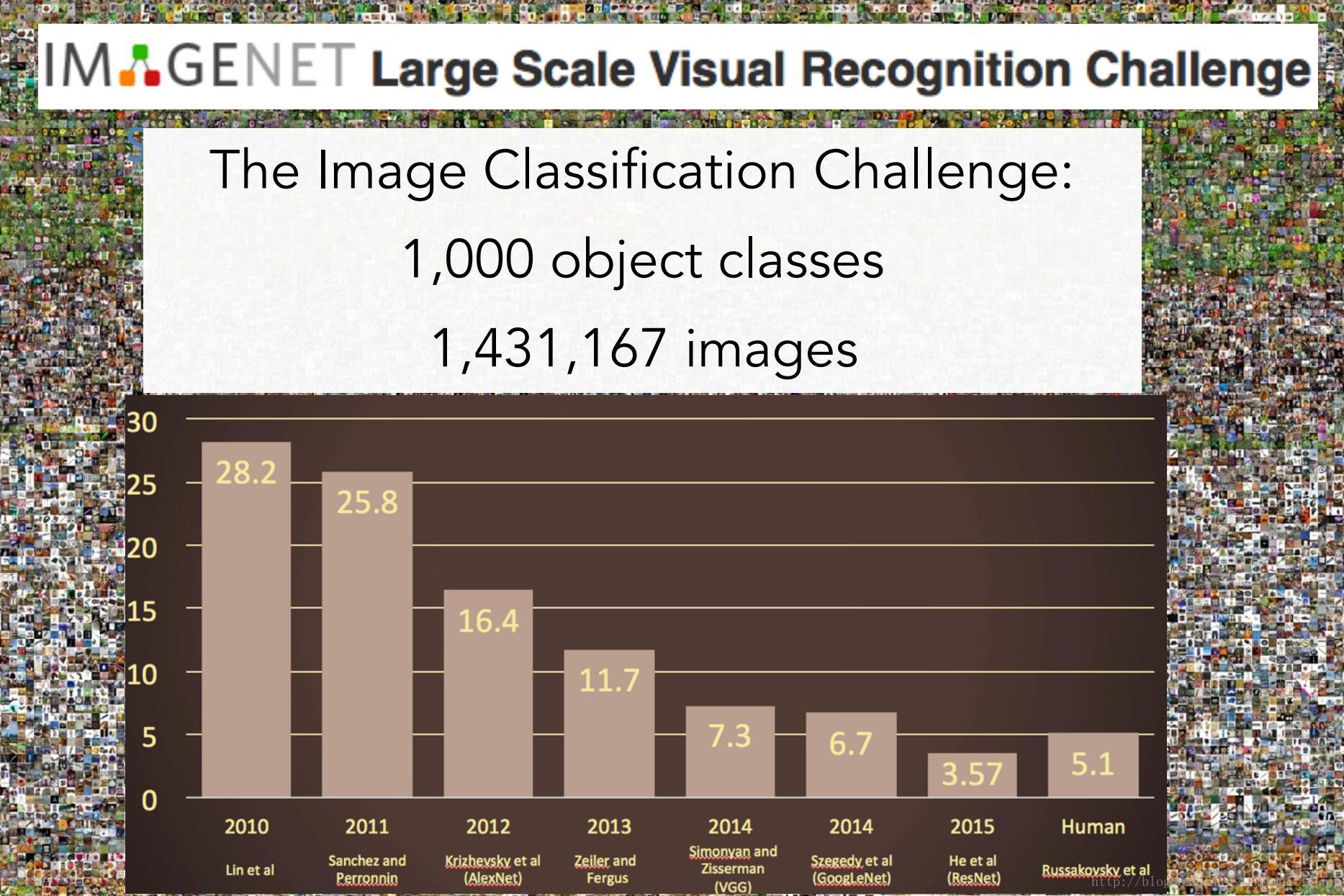
ImageNet
同时,斯坦福的一组学者,在思考我们是否具备了识别真实世界大部分物体的能力,这也是为了解决由于可视化数据非常复杂而常常出现的训练过拟合问题。在高维模型上训练时,由于训练数据量不够,很快就会产生过拟合现象。由于这两方面的动力,他们用了三年时间完成了ImageNet项目,致力于将目标识别算法推向一个新的高度。

关于CS231n
图像基本分类器

There is a number of visual recognition problems that are related to image classification, such as object detection, image captioning.以及图像摘要,生成解释文字。
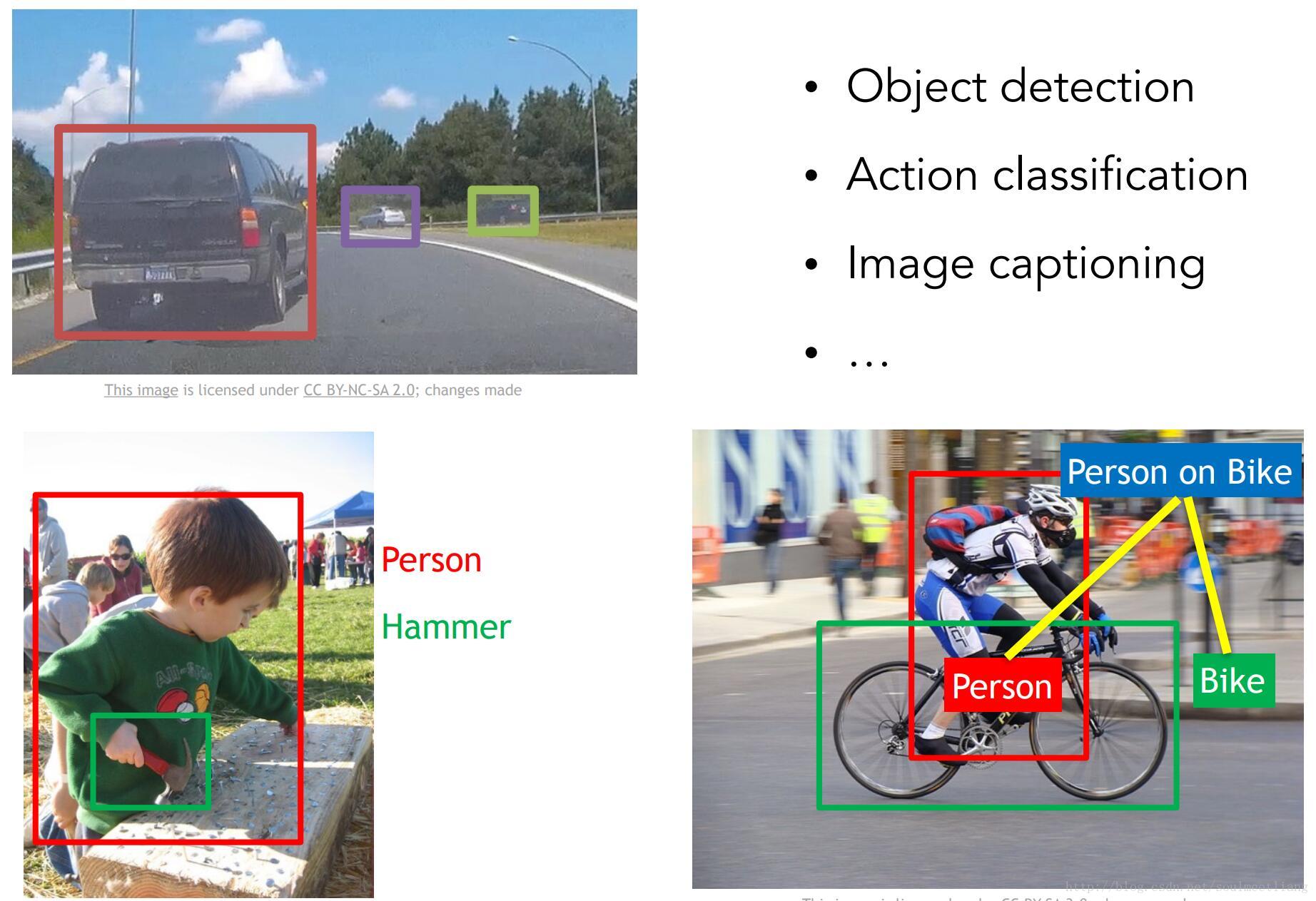
Neural Network
Convolutional Neural Networks (CNN) have become an important tool for object recognition.
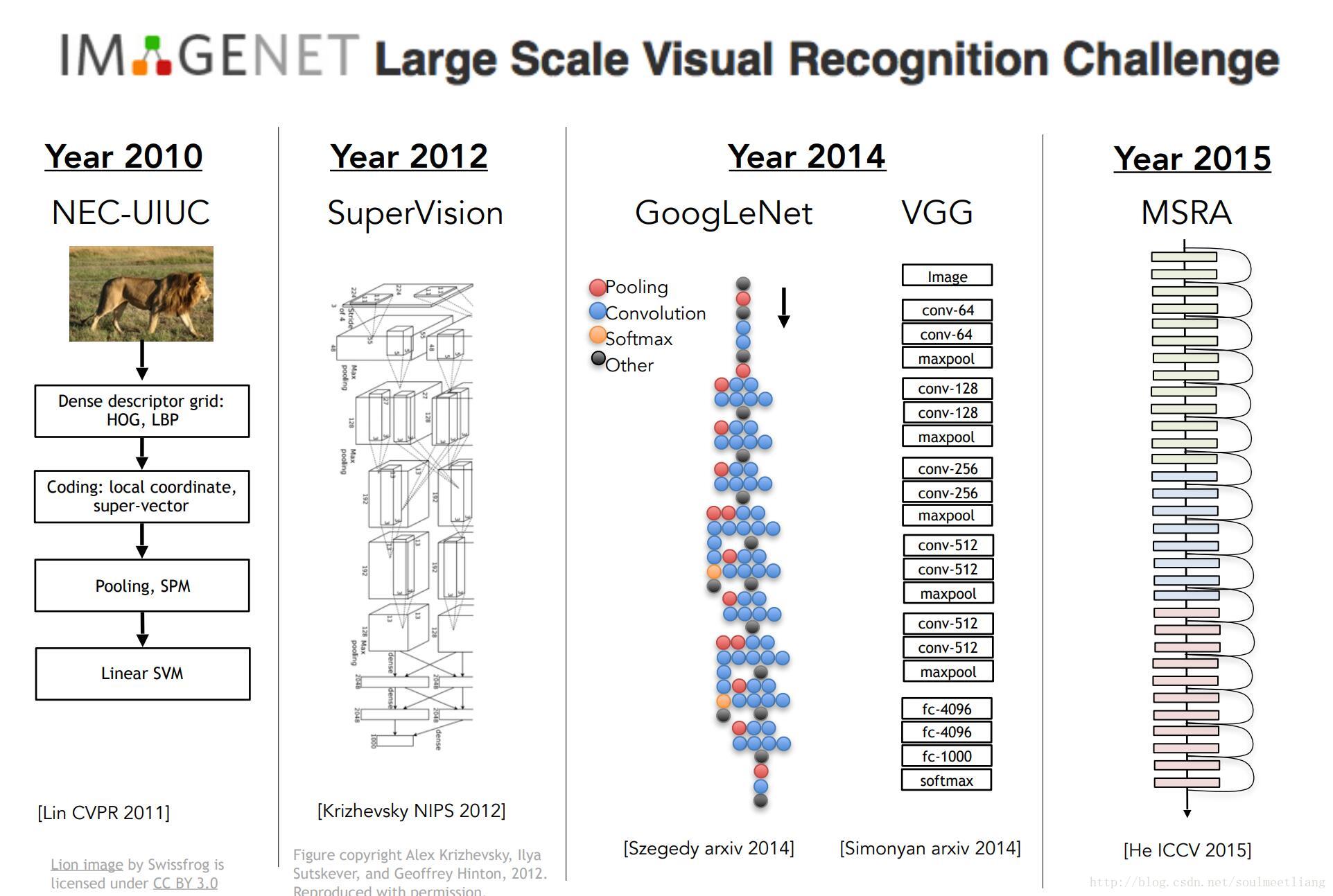
2012年CNN算法取得突破后,卷积神经网络几乎包揽了目标识别的所有成果,随着计算力的给力增长,网络也变得越来越深越来越复杂,but, Convolutional Neural Networks (CNN) were not invented overnight.
Visual Intelligence
人们不满足于算法仅仅能框出猫猫狗狗,更希望它能像人类视觉一样捕获更多东西,越来越多的开放型问题亟待解决。