摘要
现在主流的sequence2sequence的模型都是基于复杂的CNN或RNN结构,目前效果最好的几个模型都采用了attention机制,本文提出了一种新的简单的网络结构,能够完全抛弃CNN和RNN,只需要使用attention就能够让效果变得非常好。
模型
本文模型如下图所示:
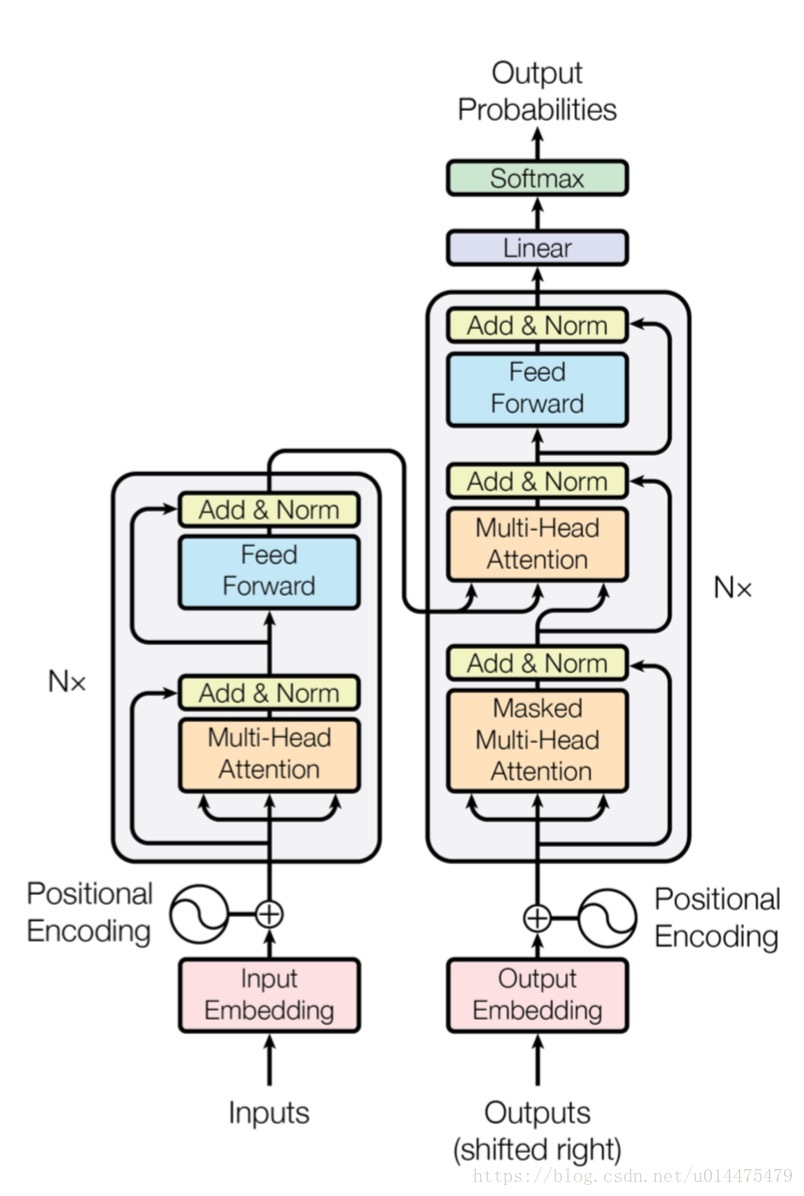
图中左侧灰色区域为encoder子结构,encoder总共包含 个这样的相同的结构。该结构包含两个子层,分别为一个称为“multi-head attention”的子层,和一个全连接的神经网络。这两个子层都采用了残差连接的方式,在加上了残差之后还做了一个归一化,公式表示为: 其中 代表每个特定的子层,为了保证残差的计算能够正常进行,每个子层的输出维度都规定为 维。
图中右侧灰色区域为decoder子结构,decoder总共包含 个这样的相同的结构。该结构包含三个子层,分别为一个称为“multi-head attention”的子层用于连接encoder的输出,一个称为“Masked multi-head attention”的子层,该层在“multi-head attention”的基础上进行了调整(为使位置 处的预测仅依赖于 之前的输出, 在 multi-head attention 内使用了 mask),最后一个子层是一个全连接的神经网络。与encoder相同,我们每一个子层都应用了残差连接并且进行了归一化。
multi-head attention的结构如下图所示:
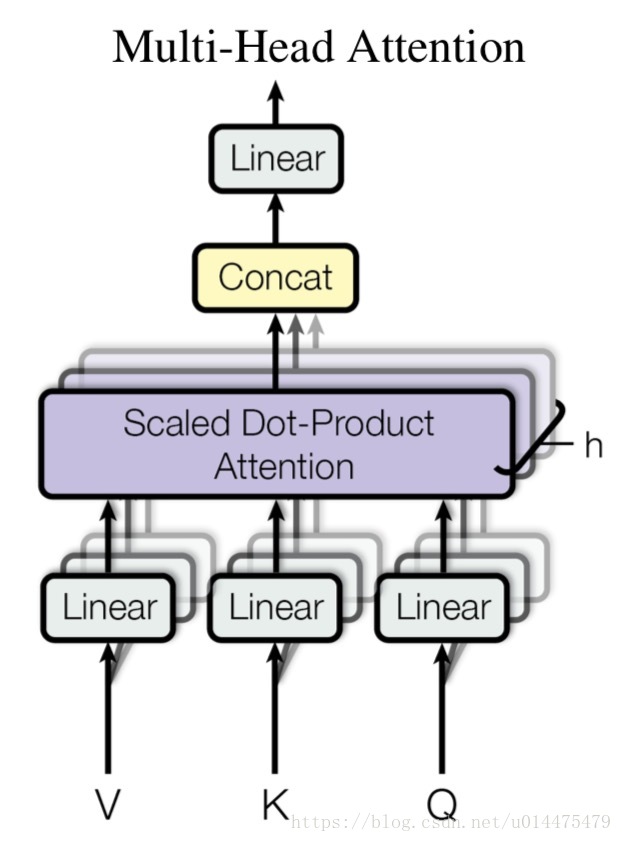
从图中可以看出,该结构中不止算了一次 Scaled Dot-Product Attention,而是对 Q, K, V 做了
次线性变换,得到
个平行的 Q, K, V,计算了
次 Scaled Dot-Product Attention,然后对所有的 Scaled Dot-Product Attention 输出做一次 concat之后再做一次线性变换. 公式:
, 其中
Scaled Dot-Product Attention的结构如下图所示:
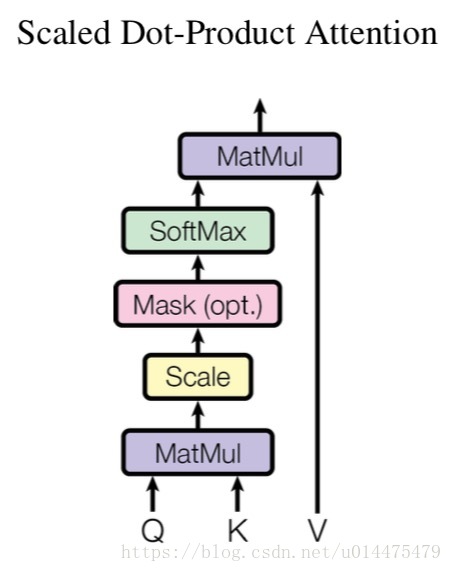
图中结构用公式可表示为: . 其中 Q 表示 query 的矩阵, K 表示 key 的矩阵, V 表示 value 的矩阵. 这个式子与 Dot-Product Attention 的区别在于多了一个分母 . (根据文章脚注的说法: 点积会随 的增大而增大, 从而使得 softmax 的梯度饱和. 假设 query 和 key 的值是均值为 0, 方差为 1 的独立变量, 的结果的方差将是 )其中 是Q和K的维度
总结
1.模型全程使用 Attention, 在 encoder 和 decoder 中使用 self-attention 来学习序列表示, 即 Q=K=V; 使用 encoder-decoder attention 将 encoder 与 decoder 连接起来. 注意, encoder-decoder attention 不是 self-attention, 因为 keys, values 来自 encoder, queries 来自 decoder。
2.不使用 RNN 与 CNN 带来了位置信息丢失的问题. 为此, 模型将 Input Embedding 与 Positional Encoding 相结合. 文中使用了
和
函数来编码位置信息.
;
. 对此, 文中的解释是: 该方法可以将相对位置注入模型, 因为对于任意固定的偏移量
,
都是
的线型函数; 此外, 该方法还能应付序列长度超出所有训练样本的情况。
3.使用 self-attention 学习序列表示的 3 个优点:
- 每层的计算复杂度降低了; (RNN 真的是很复杂很复杂啊)
- 计算可并行;
- 缓解了长期依赖 long-range dependencies问题. (使用 self-attention, 所有位置间的距离是一个常数. 带来的问题是, 每次 query 都得遍历整个输入序列, 对于超长序列, 计算开销极大。)
4.学习率的更新很有意思:
效果是, 在 wampup 阶段, 学习率增大, 之后再减小。
5.Regularization 技巧:
- Residual Dropout: 在每一个子层之后进行 dropout. 对 embedding 与 positional encoding 的和应用 dropout。
- Label Smoothing: 训练时使用该操作。 降低了 perplexity, 但提高了 accuracy 和 BLEU。
6.训练时, batch 应该是不固定的. 根据句子近似序列长度来组织 batch, 使得每一个 batch 包含约 25000 个 source token 和 25000 个 target token.