论文地址:https://arxiv.org/abs/1706.03762
Abstract
主要的sequence transduction 模型是基于复杂的递归或卷积神经网络,其中包括一个编码器和一个解码器。性能最好的模型也是通过一种注意机制来连接编码器和解码器。我们提出了一种新的简单的网络架构,the Transformer,完全基于注意机制,完全免除循环和卷积。在两个机器翻译任务上的实验表明,这些模型质量优越,同时更并行,需要的训练时间减少。我们的模型在WMT2014英德翻译任务上实现了28.4BLEU,比现有的最佳结果,包括集合,提高了超过2BLEU。我们证明,通过将Transformer成功地应用于使用大的和有限的训练数据的英语选区分析,Transformer可以很好地推广到其他任务中。
1 Introduction
最近的RNN,LSTM,门RNN均是在序列模型和tranduction 问题上sota的方法,但是存在顺序计算的基本约束条件。
在多数情况下注意力机制被用于RNN网络中。
我们提出Transformer,一种没有RNN仅依赖于attention机制来描述输入和输出之间的全局依赖关系的模型结构。Transformer允许高度并行化,可在8个P100GPU上训练12个小时让翻译达到sota的水平。
2 Background
略......
3 Model Architecture
编码器将符号表示的输入序列(x1,x2,...xn)映射到一个连续表示的序列Z=(z1,z2...,zn).给定z,解码器一次生成一个元素的符号输出序列(y1,……,ym)。在每一步,模型都是自动回归的[10],在生成下一个符号时使用之前生成的符号作为附加输入.
Transformer遵循这个整体架构,使用编码器和解码器的堆叠自我和点连接层,分别如图1的左半部分和左右半部分所示。

3.1 Encoder and Decoder Stacks
Encoder:
编码器由N=6相同层的堆叠组成。每一层都有两个子层。
(1)是多头自注意机制,
(2)是一个简单的、在位置上完全连接的前馈网络。
(3)两个子层都使用残差连接,每个子层的输出为LayerNorm(x+subLayer(x)),
为了方便这些剩余的连接,模型中的所有子层以及嵌入层都会产生尺寸数据模型=512的输出。
Decoder:
解码器也由N=6个相同的层组成。除了每个编码器层中的两个子层外,解码器插入第三个子层,该子层对编码器堆栈的输出执行多头注意力(MSA)。与编码器类似,在每个子层使用残差连接,然后是LayerNorm。
3.2 Attention
注意力函数可以描述为将查询query和一组键值对key-value映射到输出。其中查询query、键keys、值values和输出output都是向量。output作为values的加权和被计算,其中分配给每个value的权重是由query和key计算的。

3.2.1 Scaled Dot-Product Attention
"Scaled Dot-Product Attention" (Figure 2).计算如下:
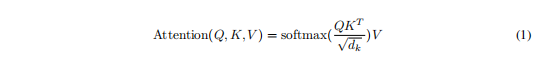
3.2.2 Multi-Head Attention
多头注意力机制,h次不同的线性投影是有增益效果的。如图2所示。

3.2.3 Applications of Attention in our Model
Transformer以三种不同的方式使用多头注意力:
- 在“编码器-解码器注意力”层中,这些Q来自于解码器层,而K和V来自于编码器的输出。这模拟了[38,2,9]等序列对序列模型中的典型编码器-解码器注意机制。
- 编码器自注意力层。在自我注意层中,所有的K、V和Q都相同。编码器中的每个位置都可以与上一层中的所有位置相关。
- 解码器自注意力层允许解码器中的每个位置关注解码器中的所有位置。
3.3 Position-wise Feed-Forward Networks
在进行了Attention操作之后,encoder和decoder中的每一层都包含了一个全连接前向网络,对每个position的向量分别进行相同的操作,包括两个线性变换和一个ReLU激活输出

其中每一层的参数都不同。