继续整理之前看过的论文,这一次看又明白了很多之前没有细究的问题,也参考了不少资料,昨晚看high了看到了2点多,学习大概就是这样一个过程吧。
参考代码:https://github.com/Njust-taoye/transformer-tensorflow 感谢
开头先说创新点:
- 提出self-attention,自己和自己做attention,使得每个词都有全局的语义信息(长依赖):
- 由于 Self-Attention 是每个词和所有词都要计算 Attention,所以不管他们中间有多长距离,最大的路径长度也都只是 1。可以捕获长距离依赖关系
- 提出multi-head attention,可以看成attention的ensemble版本,不同head学习不同的子空间语义。
废话不多说,直接带着代码看论文介绍的网络结构。
下面总结是以论文实验 机器翻译来说的。

上面这个图看的很清楚整个transformer的架构。
我们分部分来看:

Stage1 Encode Input
和普遍的做法一样,对文本输入做word embedding 操作,
embedding_encoder = tf.get_variable("embedding_encoder", [Config.data.source_vocab_size, Config.model.model_dim], self.dtype)(注意这里的model_dim)
embedding_inputs = embedding_encoder
上面其实就是做个输入文本的embedding
矩阵而已。

模型里已经剔除了RNN,CNN,如何体现输入文本的先后关系呢?而这种序列的先后关系对模型有着至关重要的作用,于是论文中提出了Position Encoding骚操作~,论文是这样做的:
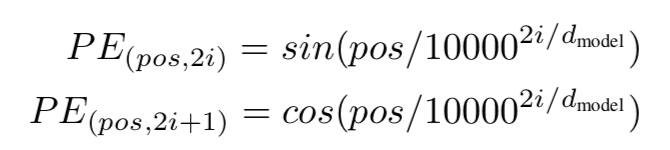
这里的dmodel指的是上面word embedding
的维度,pos就是当前的词在整个句子中的位置,例如第一个词还是第二个词等,i就是遍历dmodel
时的值,在代码中是这样做的:
def positional_encoding(dim, sentence_length, dtype=tf.float32):
encoded_vec = np.array([pos/np.power(10000, 2*i/dim) for pos in range(sentence_length) for i in range(dim)])#对每个位置处都产生一个维度为dim的向量。
encoded_vec[::2] = np.sin(encoded_vec[::2])#偶数位置处
encoded_vec[1::2] = np.cos(encoded_vec[1::2])#奇数位置处
return tf.convert_to_tensor(encoded_vec.reshape([sentence_length, dim]), dtype=dtype)
# Positional Encoding
with tf.variable_scope("positional-encoding"):
positional_encoded = positional_encoding(Config.model.model_dim, Config.data.max_seq_length, dtype=self.dtype)
上面生成的positional_encoded其实就是位置信息的embedding 矩阵。论文中提到这样做的原因,就是希望模型能很容易的学到相对先后的位置信息。具体的原理我会在文章结尾继续总结。
# Add
position_inputs = tf.tile(tf.range(0, Config.data.max_seq_length), [self.batch_size])#将range(0, max_seq_length)列表复制batch_size次,生成shape为[batch_size, max_seq_length]的张量。
position_inputs = tf.reshape(position_inputs,[self.batch_size, Config.data.max_seq_length]) # batch_size x [0, 1, 2, ..., n]#未经过embedding的位置输入信息。
好了输入文本和位置信息的embedding矩阵都做好了,该look_up 了。
encoded_inputs = tf.add(tf.nn.embedding_lookup(embedding_inputs, inputs), tf.nn.embedding_lookup(positional_encoded, position_inputs))这与输入文本信息就结合的其位置信息了,作为encoder
的整体输入,这部分对应的上面那张图的stage1
部分,这部分的操作就是如下:
![]()
decode_input embedding同理,就不再赘述了。
Stage2 Multi Head Attention

由上图我们可以看出multi head attention有三个相同的输入,不妨分别记为Q、K、V,其实就是上面的Encode Input,其shape均为[batch_size,max_seq_length,dim]。论文中提到对三个输入做num_head次不同的线性映射,即为:
def _linear_projection(self, q, k, v):
q = tf.layers.dense(q, self.linear_key_dim, use_bias=False)
k = tf.layers.dense(k, self.linear_key_dim, use_bias=False)
v = tf.layers.dense(v, self.linear_value_dim, use_bias=False)
return q, k, v
上述代码就是做线性映射,其中linear_key_dim、linear_value_dim就是映射的units个数。这里面相当于把num_head次的线性映射一起做了,后面需要把每一个head映射结果分割开,故需要保证linear_key_dim和 linear_value_dim能整除num_head。 经过线性映射后生成的q、k、v的shape分别为[batch_size,max_seq_length,linear_key_dim],[batch_size,max_seq_length,linear_key_dim],[batch_size,max_seq_length,linear_value_dim]然后按num_heads分割开来得:
def _split_heads(self, q, k, v):
def split_last_dimension_then_transpose(tensor, num_heads, dim):
┆ t_shape = tensor.get_shape().as_list()
┆ tensor = tf.reshape(tensor, [-1] + t_shape[1:-1] + [num_heads, dim // num_heads])
┆ return tf.transpose(tensor, [0, 2, 1, 3]) # [batch_size, num_heads, max_seq_len, dim]
qs = split_last_dimension_then_transpose(q, self.num_heads, self.linear_key_dim)
ks = split_last_dimension_then_transpose(k, self.num_heads, self.linear_key_dim)
vs = split_last_dimension_then_transpose(v, self.num_heads, self.linear_value_dim)
return qs, ks, vs
论文提到,这时生成的qs、ks、vs可以并行的放入到attention_function中,那么这个attention_function是个什么样的结构呢?
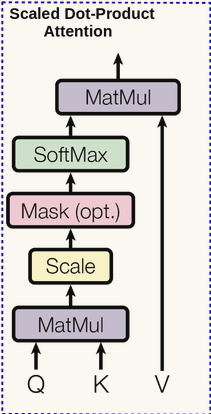
上图所示的结构在论文中被称为Scaled Dot_Product Attention,其attention值的计算公式如下:
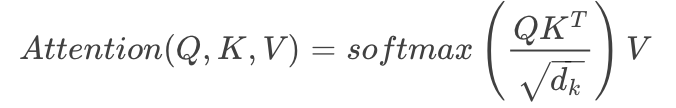
由上面可知,其公式中的Q、K、V分别对应的是qs、ks、vs,其实都是Encoder Input,只是做了不同的线性映射,其中qs、ks
的维度相同。我们可以这样理解QKT操作,假设Q为shape为[max_seq_length,dim]的矩阵,V为shape相同,那么经过QKT操作以后,变成了shape为[max_seq_length,max_seq_length]的矩阵(其实就是一个attention map),怎样理解这个生成的矩阵呢?其实就是做了个self_attention操作,即是当前句子中每个词和其他词做个乘积形成的矩阵,以得到每个词的权重,以便学习当前应该foucs到哪个词。那么为什么要除以根号dk呢?论文中说到,当两个矩阵做dot product时,可能会变得很大(试想一下,两个矩阵相互独立,且均值为0,方差为1,那么经过矩阵相乘以后,均值还为0,方差变成dk),经过softmax后,梯度可能会变得很小,为了抵消这种效果,再除以根号dk。其代码如下:
def _scaled_dot_product(self, qs, ks, vs):
key_dim_per_head = self.linear_key_dim // self.num_heads
o1 = tf.matmul(qs, ks, transpose_b=True)
o2 = o1 / (key_dim_per_head**0.5)
if self.masked:
┆ diag_vals = tf.ones_like(o2[0, 0, :, :]) # (batch_size, num_heads, query_dim, key_dim)
┆ tril = tf.contrib.linalg.LinearOperatorTriL(diag_vals).to_dense() # (q_dim, k_dim)
┆ masks = tf.tile(tf.reshape(tril, [1, 1] + tril.get_shape().as_list()),
┆ ┆ ┆ ┆ ┆ [tf.shape(o2)[0], tf.shape(o2)[1], 1, 1])
┆ paddings = tf.ones_like(masks) * -1e9
┆ o2 = tf.where(tf.equal(masks, 0), paddings, o2)
o3 = tf.nn.softmax(o2)
return o3
好了,过了self_attention后:

由上图可知,再过concat操作:
def _concat_heads(self, outputs):
def transpose_then_concat_last_two_dimenstion(tensor):
┆ tensor = tf.transpose(tensor, [0, 2, 1, 3]) # [batch_size, max_seq_len, num_heads, dim]
┆ t_shape = tensor.get_shape().as_list()
┆ num_heads, dim = t_shape[-2:]
┆ return tf.reshape(tensor, [-1] + t_shape[1:-2] + [num_heads * dim])
return transpose_then_concat_last_two_dimenstion(outputs)
论文中提到,这样做后,再过一层线性映射。(为了和输入保持纬度一致,后面要进行残差操作)
output = tf.layers.dense(output, self.model_dim)故整个Multi Head Attention 操作如下:
def multi_head(self, q, k, v):
q, k, v = self._linear_projection(q, k, v)
qs, ks, vs = self._split_heads(q, k, v)
outputs = self._scaled_dot_product(qs, ks, vs)
output = self._concat_heads(outputs)
output = tf.layers.dense(output, self.model_dim)
return tf.nn.dropout(output, 1.0 - self.dropout)
然后在做个resNet和layerNormalization(后面会总结它和bn的区别):
def _add_and_norm(self, x, sub_layer_x, num=0):
with tf.variable_scope(f"add-and-norm-{num}"):
┆ return tf.contrib.layers.layer_norm(tf.add(x, sub_layer_x)) # with Residual connection
这里面的sub_layer_x就是上面mutli head的输出,x就是encoder_input。上面就是Stage2 的整个过程。
Stage3 Feed Forward
这一步就比较简单了,就是做两层的fully_connection而已,只不过内层的fully_connection会过relu激活。
FFN(x)=max(0,xW1+b1)W2+b2
同理再过reNet、normalization。
Decode部分和上面差不多,只不过在Decode Input的Stage1部分,做self attention时,我们不能使当前词的后面的词对当前词产生影响,因为在当前我们实际是不知道后面应该有哪些词的,只不过在train的时候可以批量的训练,但是在decode的时候是不知道的。那么该怎么消除后面词对当前词的影响呢?在self attention时,会得到attention矩阵,我们只需要保留该矩阵的下三角部分即可,然后再做softmax,既可消除后面词对当前词的影响。
def _scaled_dot_product(self, qs, ks, vs):
key_dim_per_head = self.linear_key_dim // self.num_heads
o1 = tf.matmul(qs, ks, transpose_b=True)
o2 = o1 / (key_dim_per_head**0.5)
if self.masked:
┆ diag_vals = tf.ones_like(o2[0, 0, :, :]) # (batch_size, num_heads, query_dim, key_dim)
┆ tril = tf.contrib.linalg.LinearOperatorTriL(diag_vals).to_dense() # (q_dim, k_dim)
┆ masks = tf.tile(tf.reshape(tril, [1, 1] + tril.get_shape().as_list()),
┆ ┆ ┆ ┆ ┆ [tf.shape(o2)[0], tf.shape(o2)[1], 1, 1])
┆ paddings = tf.ones_like(masks) * -1e9
┆ o2 = tf.where(tf.equal(masks, 0), paddings, o2)
o3 = tf.nn.softmax(o2)
return o3
剩余部分的Stage4、Stage5与上面类似,就不再赘述了。
整个论文的过程可以用如下动画解释:

文章一些技术点的总结:
1.layer normalization
batch normalization是对一个每一个节点,针对一个batch,做一次normalization,即纵向的normalization:

layer normalization(LN),是对一个样本,同一个层网络的所有神经元做normalization,不涉及到batch的概念,即横向normalization:

BN适用于不同mini batch数据分布差异不大的情况,而且BN需要开辟变量存每个节点的均值和方差,空间消耗略大;而且 BN适用于有mini_batch的场景。
LN只需要一个样本就可以做normalization,可以避免 BN 中受 mini-batch 数据分布影响的问题,也不需要开辟空间存每个节点的均值和方差。
但是,BN 的转换是针对单个神经元可训练的——不同神经元的输入经过再平移和再缩放后分布在不同的区间,而 LN 对于一整层的神经元训练得到同一个转换——所有的输入都在同一个区间范围内。如果不同输入特征不属于相似的类别(比如颜色和大小,scale不一样),那么 LN 的处理可能会降低模型的表达能力。
2.position embeding
因为模型不包括recurrence/convolution,因此是无法捕捉到序列顺序信息的,例如将K、V按行进行打乱,那么Attention之后的结果是一样的。但是序列信息非常重要,代表着全局的结构,因此必须将序列的token相对或者绝对position信息利用起来。
将原本的input embedding和position embedding加起来组成最终的embedding作为encoder/decoder的输入。其中position embedding计算公式如下:
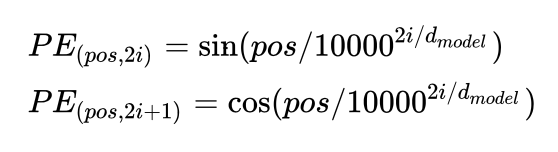
其中 pos表示位置index, i表示dimension index。
Position Embedding本身是一个绝对位置的信息,但在语言中,相对位置也很重要,Google选择前述的位置向量公式的一个重要原因是:由于我们有:

这表明位置p+k的向量可以表示成位置p的向量的线性变换,这提供了表达相对位置信息的可能性。
在其他NLP论文中,大家也都看过position embedding,通常是一个训练的向量,但是position embedding只是extra features,有该信息会更好,但是没有性能也不会产生极大下降,因为RNN、CNN本身就能够捕捉到位置信息,但是在Transformer模型中,Position Embedding是位置信息的唯一来源,因此是该模型的核心成分,并非是辅助性质的特征。
也可以采用训练的position embedding,但是试验结果表明相差不大,因此论文选择了sin position embedding,因为
- 这样可以直接计算embedding而不需要训练,减少了训练参数
- 这样允许模型将position embedding扩展到超过了training set中最长position的position,例如测试集中出现了更大的position,sin position embedding依然可以给出结果,但不存在训练到的embedding。