一、写在前面
前段时间为了重新学习一遍BERT,顺便把Transformer的论文Attention is all you need翻译了一遍,在个人水平基础上进行的翻译,存在翻译不妥的请指正。查看原论文请点击。
二、译文
以下是翻译部分
摘要
目前主流的序列转换模型的编码器、解码器都是基于复杂的CNN和RNN模型,包括性能最好的模型都是由attention机制连接编码器和解码器。我们提出了一种新的简单的网络结构—Transformer,仅仅基于attention机制,完全不依赖CNN和RNN。在两个机器翻译任务当中,实验表明Transformer模型在性能上更好,同时更具并行化,更重要的是Transformer模型训练所需时间更少。在2014年WMT国际机器翻译大赛的英德翻译任务中,我们的模型达到了28.4BLEU,在已有的最好成绩上,包括集成学习方法,提升了2BLEU。在8个GPU上训练3.5天之后,我们的模型最终在单一模型上面取得了41.8BLEU分数,我们的训练开销只是目前文献当中最好模型训练开销的一小部分(这句话是经过自己理解之后翻译的)。无论是大量还是有限的训练数据下,我们都成功的将Transformer应用于英语依存句法分析任务当中,由此可以说明Transformer可以很好地应用于其他任务。
1、简介
RNN,特别是LSTM[13]和Gated RNN [7],最终在序列模型和转换问题(比如语言模型和机器翻译)当中已经成为最先进的方法[35,2,5]。自那以后,很多工作不断地扩大了递归语言模型和编码器-解码器体系结构的界限[38,24,15]。
循环模型在实际计算过程中都隐含的有输入输出的位置特征在内。为了在计算的时候考虑位置信息,他们生成了一个序列隐状态ht,ht包含了之前隐状态信息ht-1和t时刻输入的位置信息。很自然的训练样本(training examples)中固有顺序性让我们无法进行并行,在处理很长的序列长度时并行显得很重要,因为内存约束限制了批次处理样本(此处翻译自我感觉不是很恰当,大致意思是硬件设备的缘故)。近来的工作通过因式分解技巧(factorization tricks)[21]和条件计算(conditional computation)[32]在计算效率上实现了很大的提升(对于这两种方式不了解,不知道翻译的是否准确),同时后者使得模型效果得到了提升。然而阻碍计算效率的根本因素顺序性仍然存在。
在很多任务中attention机制已经成为许多优秀的序列模型和转换模型必不可少的一部分,使得在输入或者输出序列当中不用考虑它门之间的距离而靠依赖关系进行建模[2,19](翻译有点牵强,可结合原文再进行理解)。除了极少数情况下,attention机制被广泛的应用于循环网络当中。
在这个工作当中我们提出Transformer,一种避免使用循环取而代之的是完全依靠attention机制去捕获输入和输出之间的全局依赖关系的模型结构。Transformer 允许更大程度的并行化,可以在8个p100 gpu上经过短短12小时的训练后,在翻译质量上达到一个新的水平。
2、背景
减少序列处理计算量的目标同时也是Extended Neural GPU [16],ByteNet[18]和ConvS2S[9]形成的基础,所有这些都是使用CNN作为基本构建模块,来计算所有输入和输出位置相应的隐藏表示。在这些模型当中,关联来自两个任意输入或输出位置的信号所需的操作数随位置间的距离增长而增长,比如ConvS2S呈线性增长,ByteNet呈现以对数形式增长,这会使学习较远距离的两个位置之间的依赖关系变得更加困难。在Transformer 中,这被减少到一个常数的操作次数,尽管由于计算 attention-weighted positions的平均值导致了有效分辨率 (resolution )的降低,我们将用在3.2节中描述的多头注意力(Multi-Head Attention)来抵消这个影响。
自注意力(Self-attention),有时被称为内注意力(intra-attention),它将一个序列的不同位置联系起来,以计算序列的表示。它能够很好地应用到很多任务中,包括阅读理解(reading comprehension)、文本摘要(abstractive summarization)、文本蕴涵(textual entailment),以及学习独立于任务的句子表示 [4, 27, 28, 22]。端到端的记忆网络都是基于attention机制的循环网络而不是序列对齐方式的循环网络,并且端到端记忆网络已经在简单的语言问答和语言模型任务当中有很好的表现[34].
据我们所知,Transformer 是第一个完全依赖self-attention机制,而不是使用序列对齐式RNN或者CNN的方法去计算输入和输出表示的转换模型。在接下来的部分,我们将介绍Transformer,说明Self-attention和讨论相对于[17,18]和[19]模型有哪些优势。
3、模型结构
大部分热门的神经序列转换模型都有编码器-解码器结构[5,2,35]。Encoder将输入序列(x1,…,xn)映射到一个连续表示序列 z=(z1,…,zn)。对于编码得到的z,Decoder每次解码生成一个符号,直到生成完整的输出序列:(y1,…,ym)。对于每一步解码,模型都是自回归(auto-regressive)[10]的,即在生成下一个符号时将先前生成的符号作为附加输入。Transformer 总体遵循下面的总体结构,它的编码器和解码器都是堆栈了很多self-attention层和point-wise全连接层。Encoder和decoder的大致结构分别如下图的左半部分和右半部分所示。
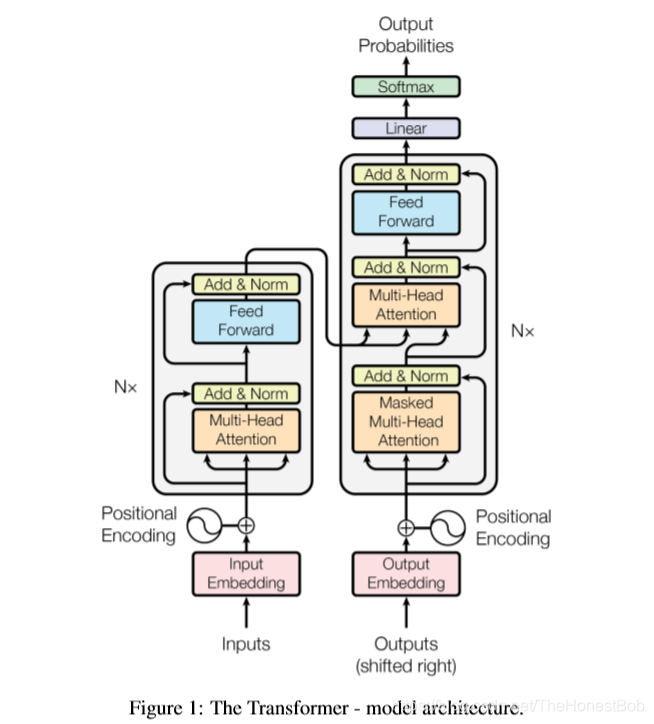
3.1 Encoder and Decoder
Encoder:编码器是由完全相同的N=6层堆栈而成。每一层都有两个子层。第一层是multi-head self-attention机制,第二层是一个简单的position-wise全连接的前馈神经网络,我们在每一个子层的两端都应用了残差连接[11](residual connection)和层归一化[1](layer normalization)。也就是说,每一个子层的输出是LayerNorm(x + Sublayer(x)),其中 Sublayer(x)函数是由子层自己实现的。为了能方便地使用这些残差连接,模型中所有的子层和Embedding层的输出都设定成了相同的维度,即d_model=512。
Decoder:解码器同样是由完全相同的N=6 层堆栈而成。除了每一个编码器中的两个子层之外,解码器加入了第三个子层,它对编码器堆栈的输出结果进行multi-head attention处理。
类似于编码器,我们在每个子层的两端都应用了残差连接,然后进行层归一化。我们还对解码器堆栈的self-attention子层进行了修改,防止当前位置影响了其后的位置。这种masking是考虑到输出的embeddings是要偏移一个位置的事实,确保预测位置i的时候仅仅是依赖小于i位置的已知输出(相当于把后面不该看到的信息屏蔽掉)。
3.2 Attenion
一个attention作用过程可以看作是一个用query和一组key-value对与output的映射关系(就是函数映射),其中query、keys、values和output都是向量。每一个output都是values加权求和计算的结果,每一个与values对应的权重(weight)都是由一个关于query和相应key的调和函数(compatibility function翻译可能不准确,后面不会进行翻译,总之就是一个计算权重的函数,后面会提到权重的计算方式)计算出来的。
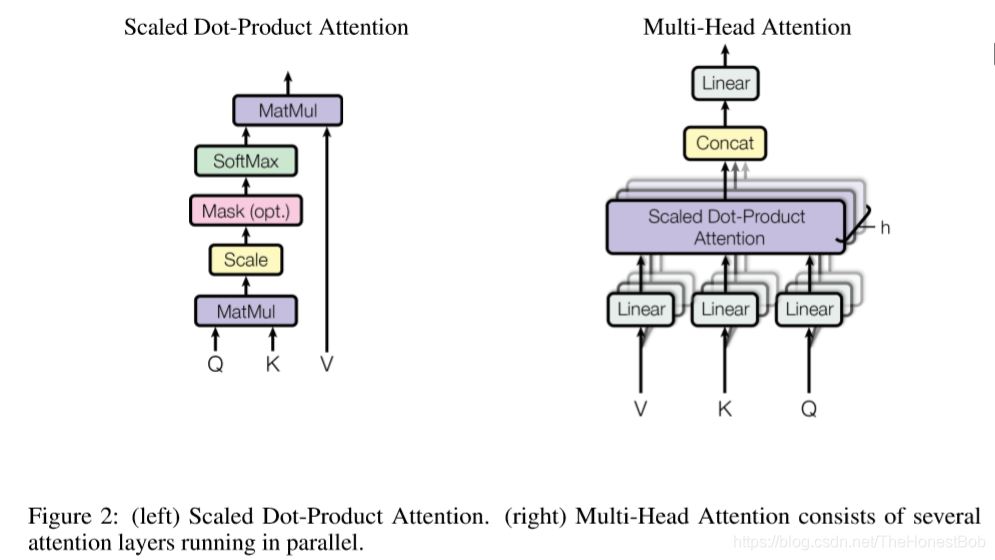
3.2.1 Scaled Dot-Product Attention
我们把我们所特指的attention称之为“Scaled Dot-Product Attention”(Figure 2)。Input是由dk维的queries和keys组成,并且values是dv维的。我们计算出query和所有keys的点积结果,然后每一个结果除以√dk,最后应用softmax函数获得所有values的权重(weights)。
在实际计算过程中,我们在用attention function(attention函数)计算一组queries的同时会把queries组合成为一个矩阵Q。keys和values同样也被组合成为矩阵K和V。我们最终计算出的输出矩阵是这样子的:
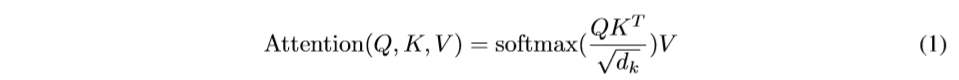
通常最常用的attention函数是additive attention [2],dot-product (multi-plicative) attention。除了我们这里用了1/√dk这个缩放因子,Dot-product attention和我们的算法是完全一样的。 Additive attention 使用一个带有单独隐层的前馈神经网络来计算compatibility function。虽然两种计算方式在理论复杂度上是差不多的,但是实际上dot-product attention运算更快并且更加space-efficient(本人不了解这方面知识,暂不做翻译),因为它可以使用高度优化的矩阵乘法代码来实现。
对于一个小的dk值来说两种机制的效果差不多,但是由于additive attention不会缩放一个较大的dk值而优于dot-product attention(可以简单的理解为乘法运算会有dk倍数的内在因素影响)。我们猜测对于一个很大的dk值而言,点积的结果增幅会很大,它会使softmax函数落到梯度值极小的区域^4(个人理解就是梯度消失的问题)。为了抵消这种影响,我们用1/√dk因子来缩放点积的结果。
3.2.2 Multi-Head Attention
相比于单一的对d_model维度的keys,values和queries进行attention处理,我们发现将queries,keys和values经过h次不同的线性映射之后,能够分别训练得到(learned)d_k,d_k,和d_v维度的线性投影。随后我们将在每一个进行线性投影之后的queries,keys和values之上并行进行attention函数处理,最终得到d_v维的输出值(output values)。如图2所示,它们被连接(concat)起来并再次进行线性投影,从而产生最终值。
Multi-head attention允许模型关注来自不同位置上不同子空间的表示信息。用single attention head就可以解决这种情况。
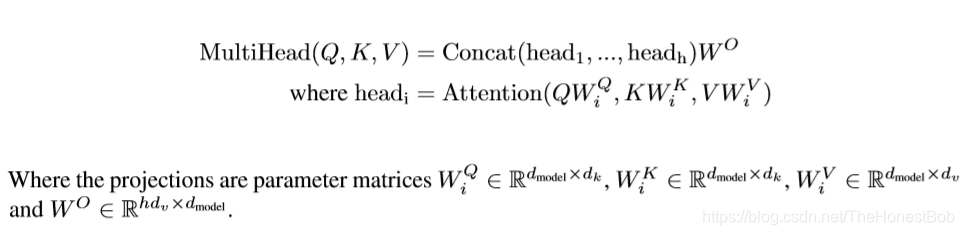
在这份工作中,我们使用的h=8个并行的attention layers或者说是attention heads。对于每一个attention layer我用的参数是dk = dv = dmodel/h = 64。为了减少每个头的规模,使之能够让总体的计算开销和全维度的single-head attention差不多。
3.2.3 Applications of Attention in our Model(Attention在我们模型上的应用)
Transformer在使用multi-head attention上有三处不同的地方:
1、在“encoder-decoder attention”层当中,queries来自之前decoder层,并且memory keys and values来自于encoder的输出。这使得decoder的每个位置都会留意输入序列的所有位置。这模仿了seq2seq模型中典型的encoder-decoder attention机制,例如[38, 2, 9]。
2、编码器包含了self-attention 层。self-attention层中的所有queries,keys和values都来自于同一个地方,在本例中,就是前一层编码器的输出。编码器中的每个位置都能够注意前一层编码器的所有位置
3、类似的,在解码器的self-attention层允许解码器的每个位置去关注包括当前位置之前的所有位置。为了维持自回归(auto-regressive)特性,我们需要阻止解码器中在左边的信息发生流动。我们在scaled dot-product attention里面实施了这个想法,就是屏蔽掉(设置为−∞)所有将要输入到softmax中的值相当于一个无效的连接(这句话掺杂了自己的理解,可结合原文进行理解)。详见Figure 2。
3.3 Position-wise Feed-Forward Networks(位置方面的前馈神经网络)
除了attention子层之外,在我们的编码器和解码器的每一层都包含了一个全连接的前馈神经网络子层,它被分别的应用于每一层相同的位置。它是由两个线性转换组成,激活函数用的是ReLU。
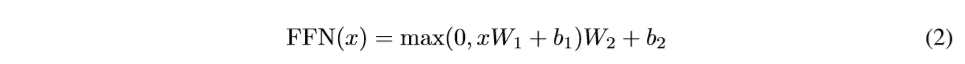
虽然在不同的位置使用的线性变换是一样的,但是他们在层与层之间使用的参数是不一样的,另外一种描述方式就是可以看成是两个卷积核尺寸为1的卷积。输入输出的维度是d_(model )= 512,内层维度是d_ff=2048。
3.4 Embeddings and Softmax
和其他序列转换模型一样,我们使用learned(通过训练形成的意思) embeddings来把输入输出tokens表示为d_(model )维的向量。同样的,我们使用常用的learned线性转换和softmax函数把decoder输出转换为预测下一个token的概率。在我们的模型里面,在嵌入层(embedding layers)和pre-softmax线性转换层之间共享相同的参数矩阵,类似于[30]。在嵌入层(embedding layers),我们将这些权重乘以√(d_(model ) )。
3.5 Positional Encoding
尽管我们的模型没有循环和卷积,为了使模型能够利用序列的顺序性,我们必须注入一些关于序列中tokens之间的关系信息或者绝对位置信息。为此,我们为最底层的编码器和解码器的输入embeddings添加了“positional encodings”。位置编码拥有和embeddings一样的维度d_(model ),如此才能够相加。对于位置编码的选择有很多,learned(可学习的)和fixed(固定的)[9]。
在这项工作当中,我们将使用不同频率的正余弦函数:
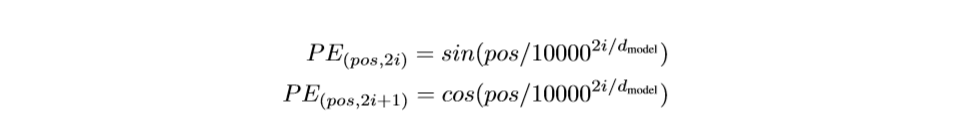
其中,pos是位置,i是维度。也就是说,位置编码的每一个维度都符合正弦曲线。波长就形成了一条2π到10000*2π的等比数列。我们之所以选择这个函数是因为我们假设它能够让模型更容易学习到位置关系,而对于任何固定的设定值k,PE_(pos+k)都能够表示为PE_pos的线性函数。
我们也对learned positional embeddings [9]进行了实验,并且发现这两种方式产生了近乎一样的结果(参考表格3第E行)。我们之所以会选择正弦曲线,是因为它能够允许模型外推(extrapolate)比训练时更长的序列长度的序列。
4 Why Self-Attention
在这个部分,我将self-attention层的很多方面和通常把一个符号表示的变长序列(x1,…,xn)映射到另一个等长的序列(z1,…,zn) ,其中xi,zi ∈ Rd,的循环和卷积进行了比较,比如经典的序列转换中的编码器或者解码器中的隐层。使用self-attention我们考虑了三点必要性。
第一是每一层总体计算复杂度。另外一个是大量的计算量能够并行化,用所需最少的有序操作数来衡量。
第三个就是网络中长程依赖之间的路径长度。学习长程依赖关系在许多序列转换任务当中是一个难点。遍历网络路径长度上的向前向后传递的信息是影响了学习这种长程依赖关系的能力关键原因(此处可以结合原文进行理解)。输入和输出序列中任意两个位置之间的路径越短,就越容易学习到长程依赖关系[12]。因此我们还比较了不同类型的层组成的网络中任意两个输入输出位置之间的最大路径长度。
如表一所示,一个self-attention层连接所有位置只需要常数量级的有序执行操作,然而循环层需要O(n)量级的有序操作。从计算复杂度来看,当序列长度n比表示维度d小的时候,self-attention层比循环(recurrent)层更快,在机器翻译中使用了句子表示法(sentence representations)的先进模型通常都是这样的情况,例如word-piece[38]和byte-pair [31]表示方法。为了提高在涉及很长序列任务的计算效果,self-attention只能考虑输入序列中以各自输出位置为中心,size为r的邻域范围。这会把路径长度的最大值增加到O(n/r)。在未来的工作中我们打算更进一步的研究这个方法。
对于卷积核宽度k<n的单独卷积层来说,它不能够连接所有的输入输出对的位置。为了增加网络中任意两个位置之间的最大路径长度,我们需要堆栈O(n/k)的连续核(contiguous kernels)卷积层或者是O(logk(n))的空洞卷积[18](dilated convolutions)(此处可能存在翻译不准,可以结合原文再去理解)。由于k,卷积层开销通常来说比循环层还要大。然而可分离卷积[6](Separable convolutions)极大的降低了计算复杂度到O(k •n•d + n•d2)。即使k=n,分离卷积的复杂度和我们模型采用的self-attention层和point-wise前馈神经网络层组合的方法相同。
self-attention可以附带产生更多可解释的模型。我们检查了模型中attention的分配,并且在附录中详细论述了呈献的样本。不仅个别的attention heads能够明确的学会如何执行不同的任务,而且很多attention heads似乎展现出和句子语法、语义结构相关的行为。(此处翻译存在翻译不准)
5 Training
这部分我们将叙述我们模型的训练过程。
5.1 Training Data and Batching
我们是在由450万个句子对组成的WMT 2014 标准的English-German 数据集上进行训练的。句子都使用byte-pair[3]进行编码,拥有源目标词汇量37000个tokens。对于English-French,我们使用了更大的WMT 2014English-French数据集,该数据集包含3600万句句子,并将标记拆分为32000个词条词汇[38]。句子对以相近的句子长度分批在一起。每个训练批次包含一组句子对,其中包含大约25000个源标记和25000个目标标记。
5.2 Hardware and Schedule
我们在一台有8个NVIDIA P100 GPU机器上训练我们的模型。对于我们论文中所描述的基础模型使用的超参数,每一个训练批次花费了0.4秒。我们的基础模型总共训练了100000步12个小时。对于我们的大模型(在表格3中最后一行),每步花费1秒。大模型总共训练了300000步(3.5天)。
5.3 Optimizer(优化器)
我们使用的是Adam优化器[20],其中β1 = 0.9, β2 = 0.98 and ϵ = 〖10〗^(-9)。我们在训练过程中使用的是一个变化的学习率,符合下面的公式:
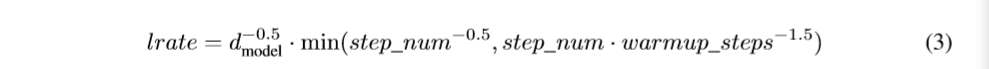
相当于在第一个warmup_steps训练步骤当中线性的增加学习率,并且之后学习率会按步数的平方根反比例减小。我们使用的参数warmup_steps = 4000。
5.4 Regularization(正则化)
我们在训练的时候采用了三种类型的正则化:
Residual Dropout 每个子层的输出在加入子层的输入和进行归一化之前,我们对其进行dropout [33]。除此之外,我们还对编码器和解码器堆的embeddings和位置编码的总和进行了dropout。在基础模型当中,我们设置P_drop=0.1。
Label Smoothing 在训练期间,我们采用了标签平滑(label smoothing),其值为 ϵ_ls=0.1[36]。让人不解的是,这使得模型学习到更多不确定性,但是却提高了准确率和BLEU分数。
6 Results(总结)
6.1 Machine Translation
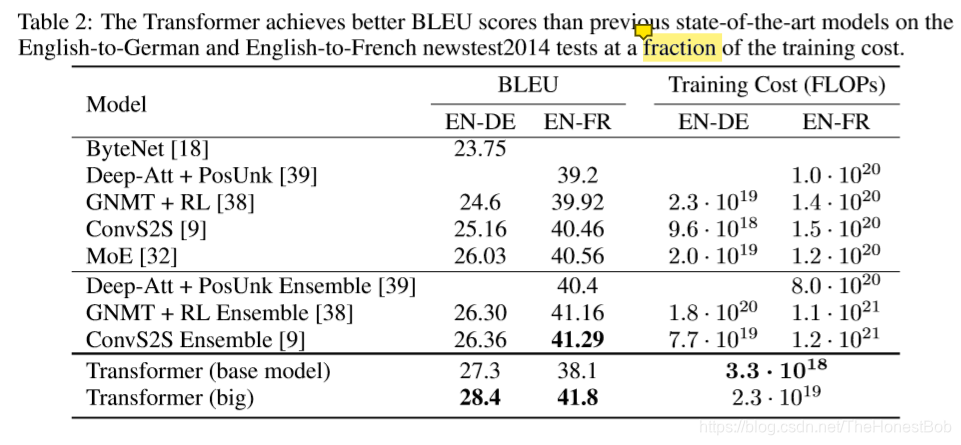
在WMT 2014英德翻译任务中,大的Transformer模型(Transformer (big) in Table 2)比之前报道过的最好模型(其中包括集成模型)高出2.0BLEU,创下了一个新的最好成绩28.4BLEU。这个模型的配置参数会在表格3的底部那行列出。在8块P100 GPU上训练了3.5天。我们的训练开销只是所有具有竞争力的模型中的一小部分,这方面我们的基础模型甚至都超越了之前所有发表的模型和集成模型。
在WMT 2014英法翻译任务中,我们的大模型达到了41.0BLEU,效果比之前发表的所有单一模型都要好,训练开销只是之前最先进模型开销的1/4。大的Transformer在训练English-to-French时P_drop=0.1,而不是0.3。
对于基础模型,我们使用的单个模型来自最后5个检查点的平均值,这些检查点每10分钟写一次。对于大型模型,我们对最后20个检查点进行了平均。我们使用beam search,beam大小为4,长度惩罚α=0.6[38]。这些超参数是在开发集上进行试验后选定的。在推断输入长度时我们设置输出长度的上限+50(很多论文翻译都不一样,以后看了代码才知道原文是什么意思,先留着)。如果可以的话可以提前结束(解码,自己理解的)。
表格2中总结了我们的结果,并和其他文献中的模型结构进行了翻译质量和训练开销方面的比较。We estimate the number of floating point operations used to train a model by multiplying the training time, the number of GPUs used, and an estimate of the sustained single-precision floating-point capacity of each GPU 5.(不清楚这种操作,以后来翻译)。
6.2 Model Variations(模型变体)
为了评估Transformer不同组件的重要性,我们以不同的方式改变我们的基础模型,测量开发集newstest2013上英文-德文翻译的性能变化。 我们使用前一节所述的beam搜索,但没有平均检查点。我们在表格3中列出了这些结果。
在表3的行(A)中,我们改变attention head的数量和attention key和value的维度,保持计算量不变,如3.2.2节所述。虽然只有一个head attention比最佳设置差0.9 BLEU,但质量也随着head太多而下降。
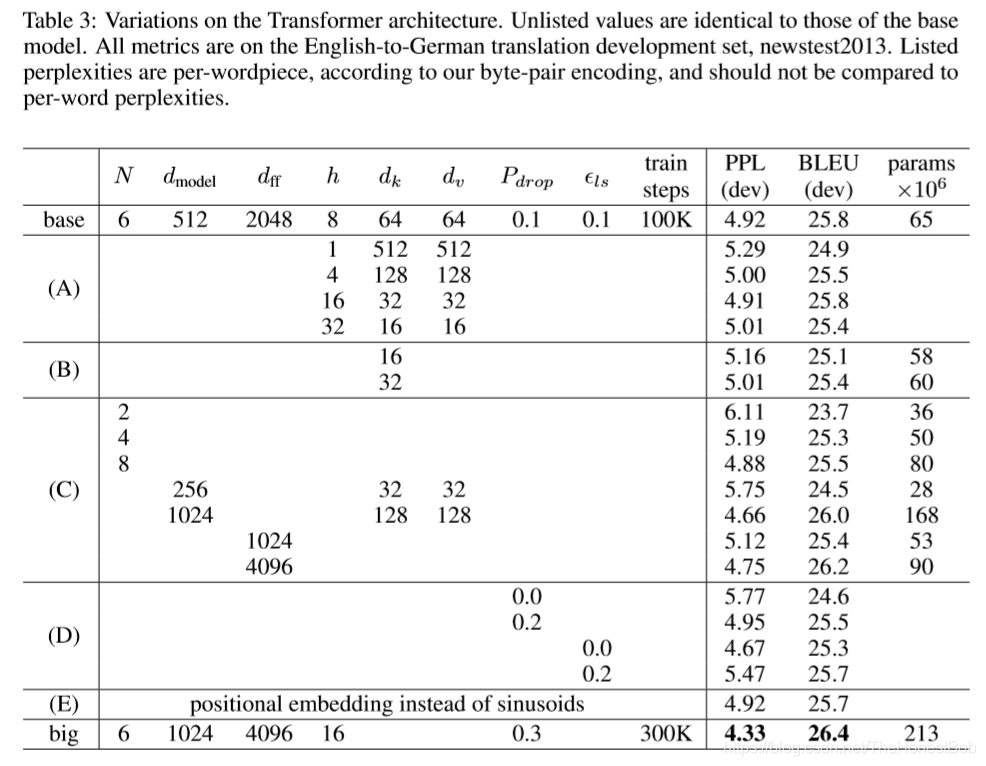
在表3行(B)中,我们观察到减小key的大小dk会有损模型质量。这表明确定其兼容性并不容易,并且比点积更复杂的compatibility function可能更有用。我们在行(C)和(D)中进一步观察到,如预期的那样,更大的模型更好,并且dropout对避免过拟合非常有帮助。在行(E)中,我们用学习到的位置嵌入[9]来替换我们的正弦位置编码,并观察到与基本模型几乎相同的结果。
6.3 English Constituency Parsing
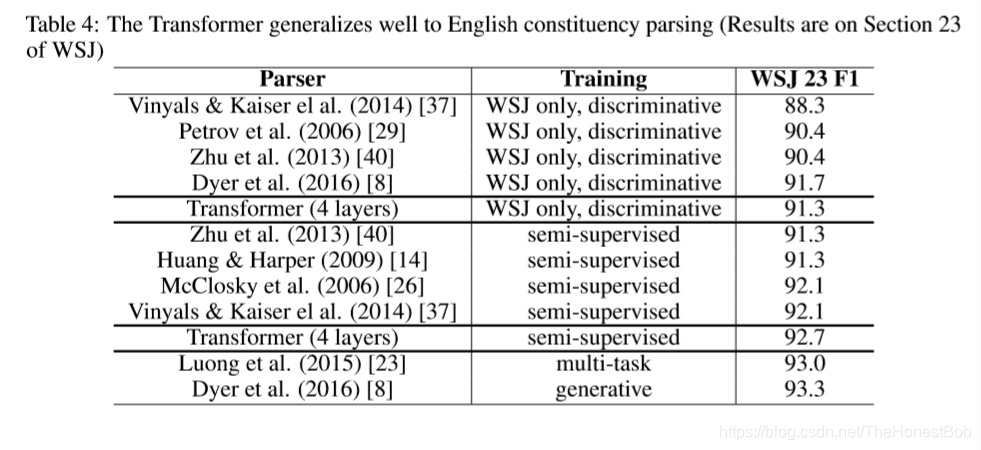
为了评估我们的模型是否能够应用到其他任务中,我们在英语的句法成分分析(constituency parsing)做了实验。这个任务呈现出一个特殊的挑战:输出是有严格的结构条件约束的(也就是句法成分结构是严格的),并且比输入要长的多。此外,RNN seq2seq模型在小数据体系[37]中还没有取得最好的结果。
我们利用Penn Treebank [25]的Wall Street Journal (WSJ)部分训练了一个4层d_model=1024的transformer,大约4万条训练句子。我们在有1.7亿条句子高置信度的BerkleyParser语料库上进行半监督训练。我们使用了一个1.6万token的词汇表作为WSJ唯一设置,和一个3.2万token的词汇表用于半监督设置。我们只进行了少量的实验来选择dropout率,包括attention和residual(5.4部分)层的learning rates和22部分开发集的beam size,所有其他的参数均和English-to-German基础翻译模型保持一样。在inference期间,我们把输入长度的最大值提高到输入长度+300。我们对WSJ和半监督学习都使用beam大小21,α=0.3。
我们表格4的结果表明,尽管缺少特定任务的微调,但是依然表现非常好,除了Recurrent Neural Network Grammar [8]之外,我们的模型获得了比之前所有报道过的模型更好的结果,
与RNN序列到序列模型[37]相比,即使仅在WSJ训练40K句子组训练时,Transformer也胜过BerkeleyParser [29]。(此处翻译感觉有问题)
7 Conclusion
在这一工作中,我们呈现了第一个完全基于attention的序列转换模型—Transformer,用multi-headed self-attention替代了大多数编码-解码结构中的循环层。
对于翻译任务而言,Transformer比基于循环或者卷积的结构要快很多。在WMT2014的English-to-German和English-to-French翻译任务上,我们都取得了最好的成绩。在以往的任务上,我们最好的模型甚至超越了之前所有报道过的集成模型。
我们对基于attention的模型的未来充满信心,并且准备将他们运用到其他任务当中去。我们计划将Transformer扩展到除文本之外的涉及输入和输出模式的问题,并调查局部的、受限attention机制以有效处理大型输入和输出,如图像、音频和视频。让生成具有更少的顺序性是我们的另一个研究目标。
我们用于训练和评估模型的代码可以在https://github.com/tensorflow/tensor2tensor上找到。
Acknowledgements We are grateful to Nal Kalchbrenner and Stephan Gouws for their fruitful comments, corrections and inspiration.
