本次分享的论文是鼎鼎有名的
自己水平有限,在读这篇论文和实现代码时,感觉比较吃力,花了两三天才搞懂了一些,在此总结下。
废话不多说,直接带着代码看论文介绍的网络结构。
下面总结是以论文实验 机器翻译来说的。

我们分部分来看:
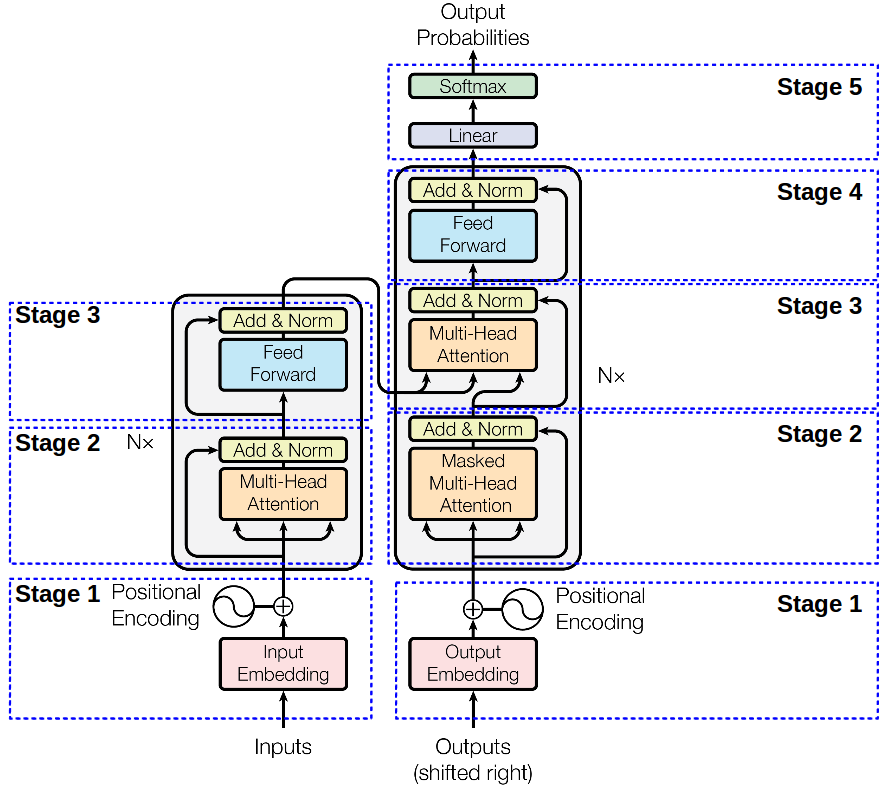
Stage1 Encode Input
和普遍的做法一样,对文本输入做
embedding_encoder = tf.get_variable("embedding_encoder", [Config.data.source_vocab_size, Config.model.model_dim], self.dtype)(注意这里的model_dim)
embedding_inputs = embedding_encoder上面其实就是做个输入文本的
模型里已经剔除了
这里的
def positional_encoding(dim, sentence_length, dtype=tf.float32):
encoded_vec = np.array([pos/np.power(10000, 2*i/dim) for pos in range(sentence_length) for i in range(dim)])#对每个位置处都产生一个维度为dim的向量。
encoded_vec[::2] = np.sin(encoded_vec[::2])#偶数位置处
encoded_vec[1::2] = np.cos(encoded_vec[1::2])#奇数位置处
return tf.convert_to_tensor(encoded_vec.reshape([sentence_length, dim]), dtype=dtype)# Positional Encoding
with tf.variable_scope("positional-encoding"):
positional_encoded = positional_encoding(Config.model.model_dim, Config.data.max_seq_length, dtype=self.dtype)上面生成的
# Add
position_inputs = tf.tile(tf.range(0, Config.data.max_seq_length), [self.batch_size])#将range(0, max_seq_length)列表复制batch_size次,生成shape为[batch_size, max_seq_length]的张量。
position_inputs = tf.reshape(position_inputs,[self.batch_size, Config.data.max_seq_length]) # batch_size x [0, 1, 2, ..., n]#未经过embedding的位置输入信息。好了
encoded_inputs = tf.add(tf.nn.embedding_lookup(embedding_inputs, inputs), tf.nn.embedding_lookup(positional_encoded, position_inputs))这与输入文本信息就结合的其位置信息了,作为
Stage2 Multi Head Attention
当时论文读到这里有点懵逼,什么叫
由上图我们可以看出
def _linear_projection(self, q, k, v):
q = tf.layers.dense(q, self.linear_key_dim, use_bias=False)
k = tf.layers.dense(k, self.linear_key_dim, use_bias=False)
v = tf.layers.dense(v, self.linear_value_dim, use_bias=False)
return q, k, v上述代码就是做线性映射,其中
然后按
def _split_heads(self, q, k, v):
def split_last_dimension_then_transpose(tensor, num_heads, dim):
┆ t_shape = tensor.get_shape().as_list()
┆ tensor = tf.reshape(tensor, [-1] + t_shape[1:-1] + [num_heads, dim // num_heads])
┆ return tf.transpose(tensor, [0, 2, 1, 3]) # [batch_size, num_heads, max_seq_len, dim]
qs = split_last_dimension_then_transpose(q, self.num_heads, self.linear_key_dim)
ks = split_last_dimension_then_transpose(k, self.num_heads, self.linear_key_dim)
vs = split_last_dimension_then_transpose(v, self.num_heads, self.linear_value_dim)
return qs, ks, vs
论文提到,这时生成的
上图所示的结构在论文中被称为
由上面可知,其公式中的
def _scaled_dot_product(self, qs, ks, vs):
key_dim_per_head = self.linear_key_dim // self.num_heads
o1 = tf.matmul(qs, ks, transpose_b=True)
o2 = o1 / (key_dim_per_head**0.5)
if self.masked:
┆ diag_vals = tf.ones_like(o2[0, 0, :, :]) # (batch_size, num_heads, query_dim, key_dim)
┆ tril = tf.contrib.linalg.LinearOperatorTriL(diag_vals).to_dense() # (q_dim, k_dim)
┆ masks = tf.tile(tf.reshape(tril, [1, 1] + tril.get_shape().as_list()),
┆ ┆ ┆ ┆ ┆ [tf.shape(o2)[0], tf.shape(o2)[1], 1, 1])
┆ paddings = tf.ones_like(masks) * -1e9
┆ o2 = tf.where(tf.equal(masks, 0), paddings, o2)
o3 = tf.nn.softmax(o2)
return o3
好了,过了
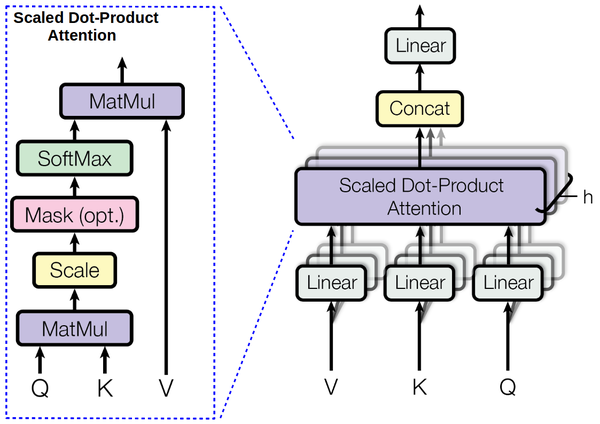
由上图可知,再过
def _concat_heads(self, outputs):
def transpose_then_concat_last_two_dimenstion(tensor):
┆ tensor = tf.transpose(tensor, [0, 2, 1, 3]) # [batch_size, max_seq_len, num_heads, dim]
┆ t_shape = tensor.get_shape().as_list()
┆ num_heads, dim = t_shape[-2:]
┆ return tf.reshape(tensor, [-1] + t_shape[1:-2] + [num_heads * dim])
return transpose_then_concat_last_two_dimenstion(outputs)论文中提到,这样做后,再过一层线性映射。
output = tf.layers.dense(output, self.model_dim)故整个
def multi_head(self, q, k, v):
q, k, v = self._linear_projection(q, k, v)
qs, ks, vs = self._split_heads(q, k, v)
outputs = self._scaled_dot_product(qs, ks, vs)
output = self._concat_heads(outputs)
output = tf.layers.dense(output, self.model_dim)
return tf.nn.dropout(output, 1.0 - self.dropout)然后在做个
def _add_and_norm(self, x, sub_layer_x, num=0):
with tf.variable_scope(f"add-and-norm-{num}"):
┆ return tf.contrib.layers.layer_norm(tf.add(x, sub_layer_x)) # with Residual connection
这里面的
上面就是
Stage3 Feed Forward
这一步就比较简单了,就是做两层的
别问我为啥
同理再过
在
def _scaled_dot_product(self, qs, ks, vs):
key_dim_per_head = self.linear_key_dim // self.num_heads
o1 = tf.matmul(qs, ks, transpose_b=True)
o2 = o1 / (key_dim_per_head**0.5)
if self.masked:
┆ diag_vals = tf.ones_like(o2[0, 0, :, :]) # (batch_size, num_heads, query_dim, key_dim)
┆ tril = tf.contrib.linalg.LinearOperatorTriL(diag_vals).to_dense() # (q_dim, k_dim)
┆ masks = tf.tile(tf.reshape(tril, [1, 1] + tril.get_shape().as_list()),
┆ ┆ ┆ ┆ ┆ [tf.shape(o2)[0], tf.shape(o2)[1], 1, 1])
┆ paddings = tf.ones_like(masks) * -1e9
┆ o2 = tf.where(tf.equal(masks, 0), paddings, o2)
o3 = tf.nn.softmax(o2)
return o3剩余部分的

整个论文的过程可以用如下动画解释:

个人看法
- 该论文摈弃了
RNN、CNN 等作为基本的模型,而是单纯的采用Attention 结构,使得计算并行性大大提高。 - 没想到
attention 也可以单独的作为神经网络的一层,甚至可以看作对input 的repesentation 。