1. 引言
文字是人类最重要的创作之一,它使人们在时空上可以有效地、可靠的传播或获取信息。
场景中的文字的检测和识别对我们理解世界很有帮助,它应用在图像搜索、即时翻译、机器人导航、工业自动化等领域。
一个场景文字识别检测示例:
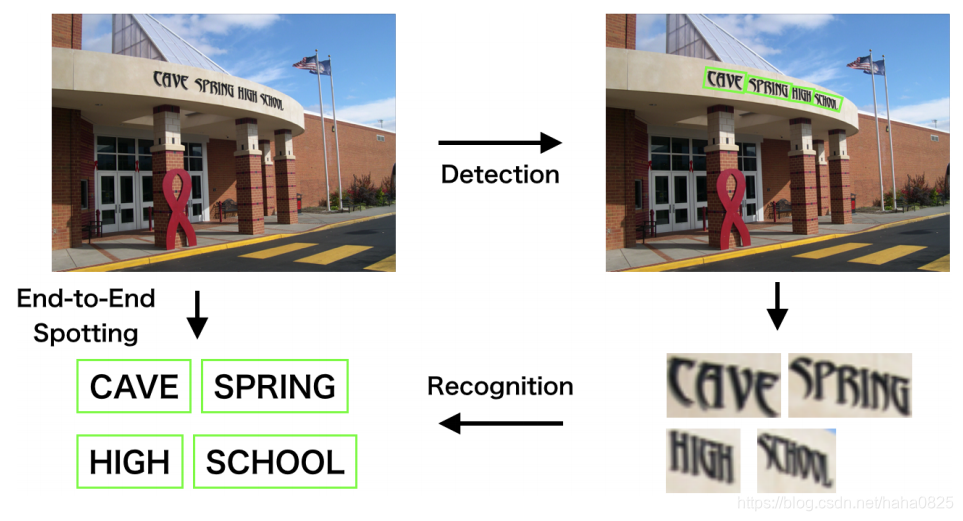
目前,场景文字检测和识别主要存在3个难点:
- 自然场景中文本多样性和变异性:文本的颜色、大小、字体、形状、方向、宽高比等属性变化较多。
- 背景的复杂性和干扰:背景存在与文本相似的形状的物体(例如砖块、窗户、交通标志等);存在遮挡问题。
- 不完善的成像条件(低分辨率、失真、模糊、低/高亮度、阴影等)。
近些年来也获得了较大的发展,主要内容有:
- 融入深度学习,基于深度学习方法。
- 面向挑战的算法模型和数据集(例如,长文本、模糊文本、弯取文本等)。
- 辅助技术的发展,例如合成数据。
场景文字检测和识别任务主要细分为文本检测、文本识别、检测和识别同时进行以及辅助方法四个子任务。
2. 文本检测
文本检测一般都是基于常规目标检测方法进行改进得来的。发展主要经过了3个阶段:首先是多步骤方式、接着是一般的目标检测方法,最后是基于文本组件的特殊表示的方法。
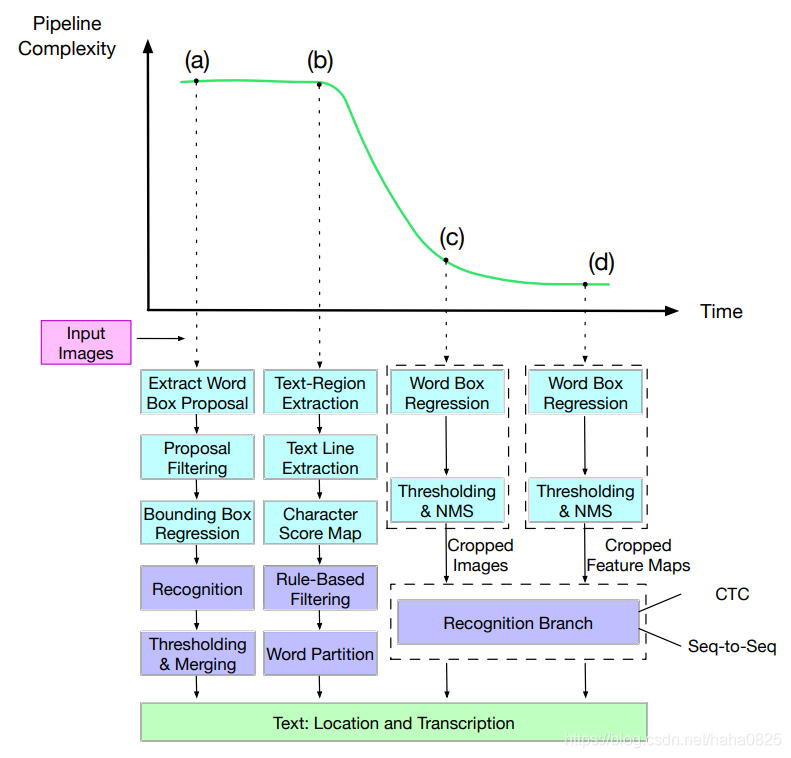
主要介绍后两种。
2.1 启发自目标检测的方法
在此阶段,通过修改通用目标检测器的区域提议和边界框回归模块来直接定位文本实例来设计场景文本检测算法。
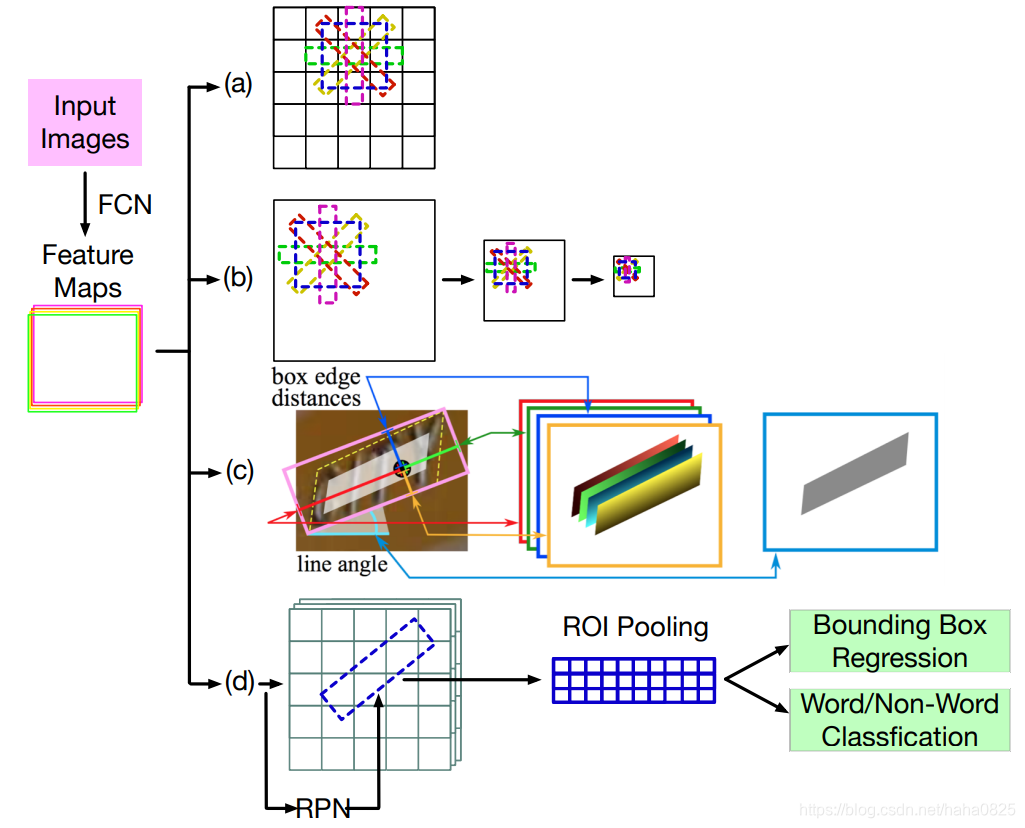
如图所示。它们主要由堆叠的卷积层组成,这些卷积层将输入图像编码为特征图。 特征图上的每个空间位置都对应于输入图像的一个区域。 然后将特征图输入到分类器中,以预测每个空间位置处文本实例的存在和定位。
- (a)与YOLO相似,基于每个anchor位置的默认边界框对偏移量进行回归。
- (b)SSD的变体,在不同比例的特征图上进行预测。
- (c)预测每个anchor的位置并直接使边界框回归。
- (d)分两个阶段的方法,并有一个额外阶段来校正初始回归结果。
具体来说:
- 受一阶段目标检测器的启发,TextBoxes [1] 使用SSD,并把默认框更改为适应文本的不同方向和宽高比的具有不同宽高比规格的四边形。
- EAST [2] 通过采用U形设计整合了不同层次的特征,输入图像被编码为一个多通道特征图,在每个空间位置处的要素都用于直接回归文本实例。
- 基于两阶段检测框架的方法,其中第二阶段根据ROI Pooling获得的特征校正定位结果。
- 在 [3] 中,旋转区域建议网络适用于生成旋转区域建议,以便适合任意方向的文本,而不是与轴对齐的矩形。
- 在FEN [4] 中,使用了不同大小的ROI Pooling的加权总和。 通过利用文本得分对4种不同大小的pooling 进行最终预测。
- [5] 建议递归执行ROI和定位分支,以修改文本实例的预测位置。 这是在边界框的边界处捕获特征的好方法,该方式比区域建议网络(RPN)更好地定位文本。
- [6] 建议使用参数化实例转换网络(Instance Transformation Network-ITN),该网络学会预测适当的仿射转换,在基础网络提取的最后一个特征层上执行,以纠正面向文本的实例。 使用ITN可以进行端到端的训练。
- 为了适应形状不规则的文本,[7] 提出了具有多达14个顶点的边界多边形,然后利用Bi-LSTM[8] 层以细化顶点的预测坐标。
- 用类似的方法,[9] 建议使用递归神经网络(RNN)来读取基于RPN的两阶段物体解码器编码的特征,并预测可变长度的边界多边形。 该方法不需要后期处理或复杂的中间步骤,并且在Total-Text上实现了更快的10.0 FPS速度。
此阶段的主要贡献是简化了检测pipeline并提高了效率。 但是,当面对弯曲,定向或长文本时,由于一阶段方法的感受野的限制,性能仍然受到限制。而对于两阶段方法,则效率受到限制。
2.2 基于子文本组件(Sub-Text Components)的方法
文本检测与常规目标检测之间的主要区别在于:文本在整体上是同质的,并具有其局部性。同质性指的是文本实例的任何部分仍然是文本的属性。局部性指的是人们不必看到整个文本实例就知道它属于某些文本。这样的属性催生出仅预测子文本组件然后组合它们为一个文本实例的检测方法。这种方法可以应用于弯曲、长和定向文本中。
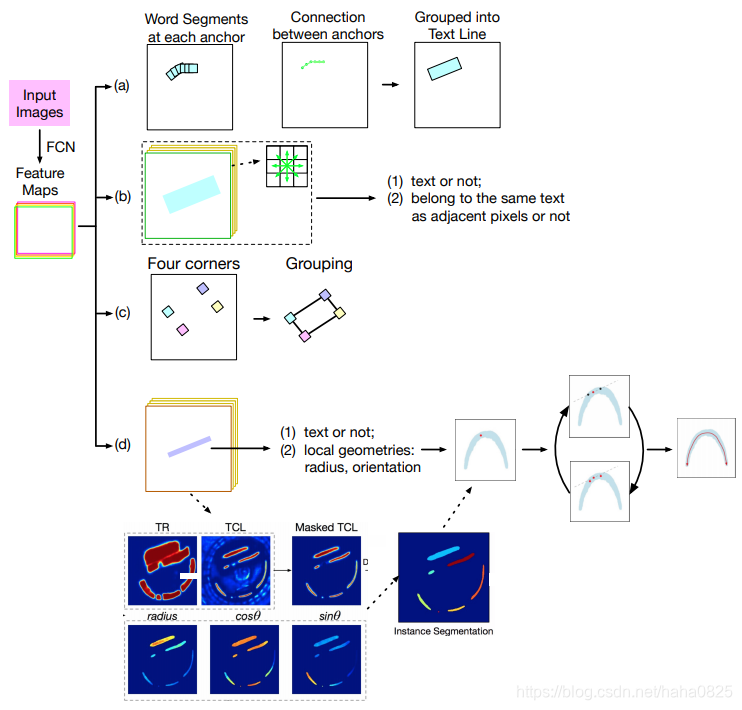
- (a)以SSD为基础网络,预测每个anchor位置的词段,以及相邻anchor之间的连接。
- (b)对于每个像素,预测文本/非文本分类以及它是否与相邻像素属于同一文本。
- (c)预测每个文本的四个角点并将属于同一文本实例的那些角点分组。
- (d)预测文本/非文本和局部几何形状,用于重建文本实例。
具体来说,根据级别不同主要分为三种:像素级、组件级以及字符级。
2.2.1 像素级方法
- 使用全卷积神经网络端到端地学习生成密集的预测图,以指示原始图像中的每个像素是否属于任何文本实例。 然后,后处理方法取决于哪些像素属于同一文本实例,将像素分组在一起。 基本上,它们可以看作是实例分割的一种特殊情况。 由于文本可以出现在使预测像素相互连接的簇中,因此像素级方法的核心是将文本实例彼此分开。
- [11] 通过添加额外的输出通道来指示相邻像素之间的链接,学习预测两个相邻像素是否属于同一文本实例。
- 边界学习方法[12] 假设边界可以很好地分隔文本实例,则将每个像素分为三类:文本,边界和背景。
- 在[13] 中,像素根据其颜色一致性和边缘信息进行聚类。 融合的图像段称为超像素。 这些超像素还用于提取字符和预测文本实例。
- 在分割框架上,[14] 建议添加一个损失项,以使属于不同文本实例的像素嵌入矢量之间的欧几里得距离最大化,并最小化属于同一实例的像素嵌入矢量之间的欧几里得距离,以更好地分离相邻文本。
- [15] 建议预测不同收缩比例的文本区域,并逐个扩大检测到的文本区域,直到与其他实例碰撞为止。 但是,不同尺度的预测本身就是上述边界学习的一种变体。
2.2.2 组件级
组件级方法通常以中等粒度进行预测。 组件是指文本实例的局部区域,有时与一个或多个字符重叠。
- 代表性的组件级方法是连接主义者文本提案网络(CTPN)[16]。 CTPN模型继承了anchor和场景文本检测和识别的思想:7个递归神经网络用于序列标记。 在CNN上堆叠RNN。 最终特征图中的每个位置代表由相应anchor指定的区域中的特征。 假设文本水平显示,要素的每一行将被送入RNN并标记为文本/非文本。 还可以预测诸如段大小的几何形状。 CTPN是第一个使用深层神经网络预测场景文本片段并将其连接的方法。
- [17] 通过考虑段之间的多方向链接来扩展CTPN。段的检测基于SSD,其中每个默认框代表一个文本段。 默认框之间的链接被预测为指示相邻的段是否属于同一文本实例。 [18] 通过使用图卷积网络来预测段之间的链接,从而进一步改善SegLink。
- 角点定位方法[19] 建议检测每个文本实例的四个角点。由于每个文本实例仅具有4个角,因此预测结果及其相对位置可以指示应将哪些角分组到同一文本实例中。
- [20] 认为文本可以表示为沿着文本中心线(TCL)的一系列滑动圆盘,这与文本实例的运行方向一致,如图所示:

它以新颖的表示形式提出了一个新模型TextSnake,该模型可学习预测局部属性,包括TCL /非TCL,文本区域/非文本区域,半径和方向。 TCL像素和文本区域像素的交集给出了像素级TCL的最终预测。 然后使用局部几何图形以有序点列表的形式提取TCL。 使用TCL和半径,可以重建文本行。 它可以在多个弯曲文本数据集以及更广泛使用的数据集上实现最新的性能。 值得注意的是,[21] 提出跨不同数据集的交叉验证测试,其中模型仅在具有纯文本实例的数据集上进行微调,然后在弯曲数据集上进行测试。 在所有现有的弯曲文本数据集中,TextSnake与F1-Score中的其他基线相比,性能最多可提高20%。
2.2.3 字符级
- 字符级表示是另一种有效的方法。 [22] 建议学习字符中心及其之间的链接的分割图。 组件和链接都以高斯热图的形式进行预测。 但是,由于现实世界的数据集很少配备字符级标签,因此,此方法需要迭代的弱监督。
总体而言,基于子文本成分的检测在文本实例的形状和纵横比方面具有更好的灵活性和泛化能力。 主要缺点是,用于将片段分组为文本实例的模块或后处理步骤可能容易受到噪声的影响,并且此步骤的效率高度依赖于实际实现,因此在不同平台之间可能会有所不同。
3. 字符识别
场景文本识别的输入是仅包含一个单词的裁剪的文本实例图像。在深度学习时代,场景文本识别模型使用CNN将图像编码到特征空间中。 各方法的主要区别在于文本内容解码模块。
两种主要技术是连接主义者的时间分类(CTC)和编码器-解码器框架。 主流框架如图所示:
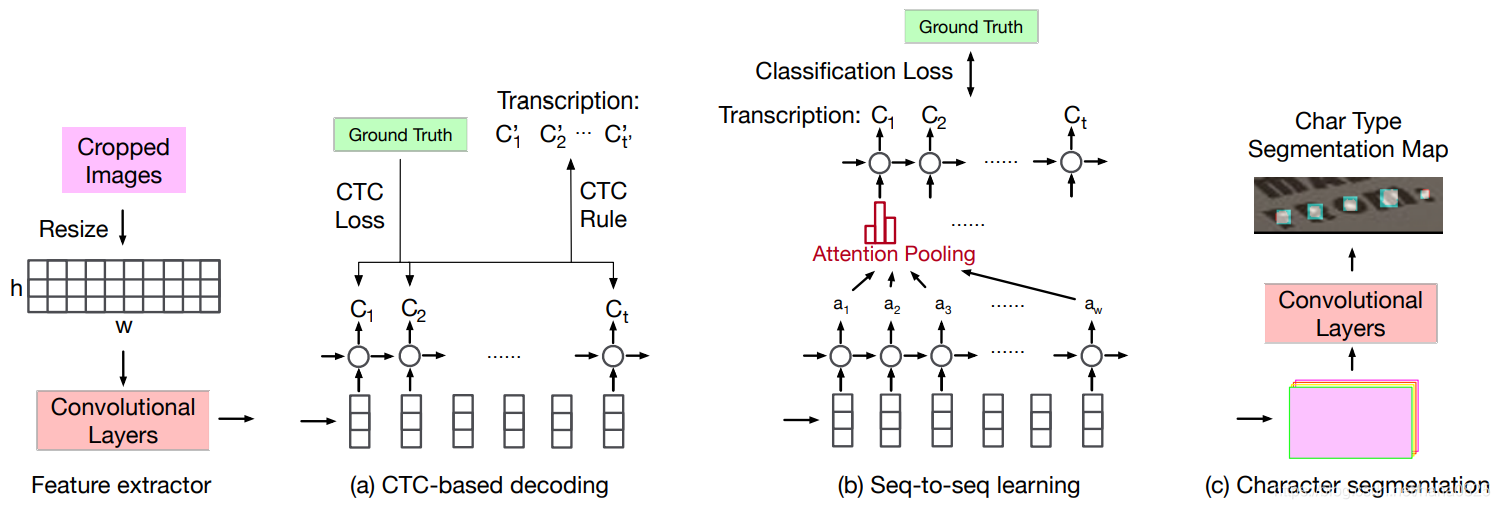
- (a)表示序列标签模型,并使用CTC进行训练和推理。
- (b)表示一个序列到序列模型,并且可以使用交叉熵直接学习。
- (c)表示基于细分的方法。
CTC和编码器-解码器框架最初都是为一维顺序输入数据设计的,因此适用于识别直线文本和水平文本,CNN可以将它们编码为一系列特征帧而不会丢失重要信息。 但是,定向和弯曲文本中的字符分布在二维空间上。 有效地在特征空间中表示定向文本和弯曲文本以适应CTC和编码器-解码器框架(其解码需要一维输入)仍然是一个挑战。 对于定向和弯曲的文本,将特征直接压缩为一维形式可能会丢失相关信息,并会引起背景噪声,从而导致识别精度下降。
3.1 基于CTC的方法
如果将CTC应用到场景文本识别中,则将输入图像视为一系列垂直像素帧。 网络输出每帧预测,指示每帧标签的概率分布。然后应用CTC规则将每帧预测编辑为文本字符串。 在训练期间,将损失计算为可以通过CTC规则生成目标序列的所有可能的每帧预测的负对数概率的总和。因此,CTC方法使其仅使用单词级注释即可进行端到端训练,而无需使用字符级注释。
- 最初的基于CTC的方法为卷积递归神经网络(CRNN)。 这些模型是通过将RNN堆叠在CNN之上并使用CTC进行训练和推理而构成的。 DTRN[23] 是第一个CRNN模型。 它在输入图像上滑动CNN模型以生成卷积特征切片,然后将其输入RNN。 [24] 利用CNN不受输入空间大小限制的特性,采用全卷积方法对输入图像进行整体编码以生成特征切片,从而进一步改进了DTRN。
- [25] 替换RNN,采用堆叠的卷积层来有效捕获输入序列的上下文相关性,其特点是计算复杂度较低,并行计算更容易。
- [26] 通过使用字符模型滑动文本行图像来同时检测和识别字符,这是在标记有文本记录的文本行图像上端到端学习的。
3.2 基于Encoder-Decoder的方法
[27] 最初提出了一种用于序列到序列学习的编码器-解码器框架,用于机器翻译。 编码器RNN读取输入序列,并将其最终的潜在状态传递给解码器RNN,解码器RNN以自回归的方式生成输出。 编码器-解码器框架的主要优点是它提供可变长度的输出,可以满足场景文本识别的任务设置。 编码器-解码器框架通常与注意力机制结合,后者共同学习对齐输入序列和输出序列。
- [28] 提出了具有注意力模型的递归循环神经网络,用于无词典场景文本识别。 该模型首先将输入图像传递给递归卷积层,以提取编码的图像特征,然后通过具有隐式学习的字符级语言统计信息的递归神经网络将它们解码为输出字符。 基于注意力的机制执行软特征选择,以更好地使用图像特征。
- [29] 观察了现有基于注意力的方法中的注意力漂移问题,并建议对注意力得分实施局部监督以减弱它。
- [30] 提出了一种编辑概率(edit probability-EP)度量标准,以处理GT字符串与注意力的概率分布输出序列之间的失准。 与前面提到的通常采用逐帧最大似然损失的基于注意力的方法不同,EP尝试根据输入图像上的概率分布的输出序列来估计生成字符串的概率,同时考虑丢失或多余字符的可能出现。
- [31] 提出了一种有效的基于注意力的编码器-解码器模型,其在二进制约束下训练编码器部分以减少计算成本。
CTC和编码器-解码器框架都简化了识别流程,并使得仅使用单词级注释而不是字符级注释来训练场景文本识别器成为可能。 与CTC相比,Encoder-Decoder框架的解码器模块是隐式语言模型,因此它可以包含更多的语言先验。出于同样的原因,编码器-解码器框架需要具有较大词汇量的较大训练数据集。 否则,当识别训练中看不见的单词时,模型可能会退化。 相反,CTC较少依赖语言模型,并且具有更好的字符到像素对齐方式。 因此,对于字符集较大的中文和日语等语言,CTC可能会更好。 这两种方法的主要缺点是它们假定文本是笔直的,因此不能适应不规则的文本。
3.3 适应不规则文本识别的方法
- 纠正模块(Rectification-modules)是不规则文本识别的流行解决方案。[32]提出了一种文本识别系统,该系统将空间转换网络(Spatial
Transformer Network -STN)[33]和基于注意力的序列识别网络相结合。STN模块使用全连接层预测文本边界多边形,以进行Thin-Plate-Spline转换,从而将输入的不规则文本图像校正为更规范的形式,即垂直的文本。纠正(Rectification)被证明是一种成功的策略,并成为ICDAR 2019 ArT2不规则文本识别竞赛中获奖解决方案的基础[34] 。 - 还存在一些基于纠正的识别的改进版本。[35] 建议多次纠正,以逐步纠正文本。 它们还用多项式函数代替文本边界多边形来表示形状。
- [36] 建议以类似于TextSnake的方式预测局部属性,例如文本中心区域内像素的半径和方向值。 方向定义为基础字符框的方向,而不是文本边界多边形。 基于这些属性,以纠正字符的透视畸变的方式重建边界多边形。
- [37] 引入了辅助密集字符检测任务,以鼓励学习有利于文本模式的视觉表示。并且他们采用对齐损失来调整每个时间步的估计注意力。 此外,他们使用坐标图作为第二输入以增强空间意识。
- [38] 认为大多数方法将文本图像编码为特征的一维序列,是不够的。 它们将输入图像编码为四个方向的四个特征序列:水平,水平反转,垂直和垂直反转。 应用加权机制来组合四个特征序列。
- [39] 提出了一种分层注意力机制(hierarchical attention
mechanism -HAM),该机制由循环RoIWarp层和字符级注意力层组成。 他们采用局部变换对单个字符的变形进行建模,从而提高了效率,并且可以处理难以通过单个全局转换建模的不同类型的变形。 - [40] 将识别任务转换为语义分割,并将每种字符类型都视为一个类别。 该方法对形状不敏感,因此对不规则的文本有效,但是缺少端到端训练和序列学习使其易于出现单字符错误,尤其是在图像质量较低时。 它也是第一个通过填充和转换测试图像来评估其识别方法的鲁棒性的方法。
- 解决不规则场景文本识别的另一种解决方案是二维注意力[41] ,这已在[42] 中得到了验证。与顺序编码器-解码器框架不同,二维注意力模型保持二维编码特征,并且针对所有空间位置计算注意力得分。 与空间注意力类似,[43] 建议首先检测字符,然后,特征沿着字符中心线进行插值和聚集,形成连续的特征帧。
- 除了上述技术,[44] 表明,简单地将特征图从2维展平到1维并将结果序列特征馈送到基于RNN的注意力编解码器模型就足以在不规则文本上产生最新的识别结果, 是一个简单而有效的解决方案。
- 除了量身定制的模型设计,[45] 合成了弯曲文本数据集,这在不牺牲纯文本数据集的情况下显着提高了现实世界中弯曲文本数据集的识别性能。
尽管已经提出了许多优雅而整洁的解决方案,但仅基于相对较小的数据集CUTE80(仅包含288个单词样本)对它们进行评估和比较。 此外,这些作品中使用的训练数据集仅包含极少比例的不规则文本样本。 对更大的数据集和更合适的训练数据集进行评估可能有助于我们更好地理解这些方法。
3.4 其他方法
- [46] 在图像分类的框架下,通过将图像分类为一组预定义的词汇来执行单词识别。该模型由合成图像训练,并在仅包含英语单词的某些基准上达到了最新的性能。 但是,此方法的应用非常有限,因为它不能应用于识别看不见的序列,例如电话号码和电子邮件地址。
- 为了提高在困难情况下的性能,例如遮挡给单字符识别带来歧义,[47] 提出了一种基于转换器的语义推理模块,该模块执行从解码器的粗略,容易出错的文本输出到精细的语言校准输出的转换,这与机器翻译的审议网络有些相似[48]:先翻译然后重新编写句子。
尽管到目前为止我们已经看到了识别方法的进步,但是识别方法的评估却比较落后。 由于大多数检测方法都可以检测到定向的和不规则的文本,甚至可以纠正它们,因此识别此类文本似乎显得多余。 另一方面,很少验证当使用略微不同的边界框裁剪时识别的鲁棒性。 在现实情况下,这种鲁棒性可能更为重要。
3.5 End-to-End System
在过去,文本检测和识别通常被视为两个独立的子问题来完成从图像中读取文本。最近,许多端到端的文本检测和识别系统(也称为文本定位系统)已经被提出,是现在的趋势。

- (a) :在SEE中,检测结果用网格矩阵表示。图像区域在输入到识别分支之前被裁剪和变换。
- (b) :一些方法从特征图中裁剪并将其输入到识别分支。
- (c) :当(a)和(b)使用基于CTC和基于注意力的识别分支时,也可以将每个字符作为通用目标检测并合成文本。
3.5.1 Two-Step Pipelines
虽然早期的工作(Wang等人,2011年,2012年)首先检测输入图像中的单个字符,但最近的系统通常在单词级别或行级别检测和识别文本。其中一些系统首先使用文本检测模型生成文本建议,然后使用另一个文本识别模型对其进行识别。
- [49] 使用边缘盒建议和经过训练的聚合通道特征检测器的组合来生成候选字边界框。提案框在被发送到识别模型之前被过滤和修正。
- [50] 将基于SSD的文本检测器与CRNN相结合,以识别图像中的文本。
在这些方法中,检测到的单词是从图像中裁剪出来的,因此,检测和识别是两个独立的步骤。这两种方法的一个主要缺点是检测和识别模型之间的误差传播会导致性能较差。
3.5.2 Two-Stage Pipelines
最近提出了端到端可训练网络来解决上一问题,其中裁剪并输入到识别模块的是特征图不是图片。
- [51] 提出了一种利用STN循环关注输入图像中的每个单词,然后分别识别它们的解决方案。联合网络以弱监督方式训练,不使用字边界盒标签。
- [52] 用基于编解码器的文本识别模型代替了Faster-RCNN中的物体分类模块,组成了文本识别系统。
- [53] 和 [54] 分别采用EAST和YOLOv2作为检测分支,并有一个类似的文本识别分支,其中文本建议通过双线性采样汇集到固定高度张量中,然后由基于CTC的识别模块转录成字符串。
- [55] 还采用EAST生成文本建议,并在基于注意的识别分支中引入字符空间信息作为显式监督。
- [56] 提出了一种改进的Mask R-CNN。对于每个感兴趣的区域,生成字符分割图,指示单个字符的存在和位置。将这些字符从左到右排序的后处理步骤将给出最终结果。
- 与上述基于定向边界框执行ROI Pooling的工作不同,[57] 建议使用轴对齐的边界框,并使用0/1文本分割掩码来mask裁剪的特征。
3.5.3 One-Stage Pipeline
除了两阶段的方法,[58] 并行预测字符和文本边界框以及字符类型分割图。然后使用文本边界框对字符框进行分组,以形成最终的单词转录结果。这是第一个单阶段的方法。
3.6 辅助技术
3.6.1 合成数据
大多数深度学习模型都需要数据。只有当有足够的数据可用时,才能保证它们的性能。在文本检测和识别领域,这个问题更为迫切,因为大多数人工标注的数据集都很小,通常只包含1K-2K个数据实例。幸运的是,已经有一些工作生成了相对高质量的数据,并被广泛用于训练模型,以获得更好的性能。
- [59] 建议生成用于文本识别的合成数据。他们的方法是重排字体、边框/阴影、颜色和分布后,将文本与来自人类标签数据集的随机裁剪的自然图像混合在一起。结果表明,仅对这些合成数据进行训练就可以达到最先进的性能,并且合成数据可以作为所有数据集的补充数据源。
- SynthText [60] 首先提出在自然场景图像中嵌入文本,然后用于文本检测的训练。而以往的研究大多只在裁剪区域嵌入文本,这些合成数据仅用于文本识别。在整个自然图像上嵌入文本带来了新的挑战,因为它需要保持语义的一致性。为了生成更真实的数据,SynthText使用深度预测和语义分割。语义分割将像素集合成语义簇,每个文本实例嵌入在一个语义面上,而不是重叠在多个语义面上。密集深度图进一步用于确定文本实例的方向和变形。仅在SynthText上训练的模型在许多文本检测数据集上达到了最先进的水平。后来在其他工作以及初始预训练中使用。
- 此外,[61] 将文本合成与其他深度学习技术相结合,以生成更真实的样本。它们引入了选择性的语义分割,使得单词实例只出现在可感知的物体上,例如桌子或墙上,而不是某人的脸上。在他们的方法中,文本渲染是根据图像进行调整的,这样既能适应艺术风格,又不会显得尴尬。
- SynthText3D[62] 使用著名的开源游戏引擎Unreal engine 4(UE4)和UnrealCV合成场景文本图像。文本与场景一起渲染,因此可以实现不同的照明条件、天气和自然遮挡。然而,SynthText3D只是遵循SynthText的流水线,只使用游戏引擎提供的真实深度和分割图。因此,synthext3d依赖于手动选择相机视图,这限制了它的可伸缩性。此外,本文提出的文本区域是通过裁剪从分割图中提取的最大矩形边界框生成的,因此仅限于大的、定义良好的区域的中间部分,这是一个不利的位置偏差。
- Unaltext [63] 是另一个使用游戏引擎合成场景文本图像的作品。它的特点是在合成过程中与三维世界进行深入的交互。提出了一种基于光线投射的三维场景漫游算法,能够自动生成不同的摄像机视图。文本区域建议模块基于碰撞检测,可以将文本放到整个曲面上,从而消除位置偏差。unaltext实现了显著的加速和更好的检测器性能。
文本编辑: 最近提出的文本编辑任务也值得一提([64]、[65])。两部作品都试图替换文本内容,同时保留自然图像中的文本样式,例如字符、文本字体和颜色的空间排列。文本编辑本身在诸如使用手机摄像头的即时翻译等应用程序中非常有用。虽然我们还没有看到任何相关的实验结果,但是它在增强现有场景文本图像方面也有很大的潜力。
3.6.2 弱监督/半监督
…(待补充)
4. 数据集及评估
4.1 数据集

上图是从一些数据集中选取一些有代表性的图像样本
然后选择了一些有代表性的数据集并讨论了它们的特点:
- ICDAR 2015 [66] 数据集侧重于小型和定向文本。这些图片是由谷歌眼镜拍摄的,不考虑图像质量。图像中很大比例的文本非常小、模糊、遮挡和多方向,这使得它非常具有挑战性。
- ICDAR MLT 2017和2019 [67] 数据集分别包含9种和10种语言的脚本。它们是迄今为止唯一的多语言数据集。
- Total Text [68] 有很大比例的曲线文本,而以前的数据集只包含很少的曲线文本,这些图像主要取自街道广告牌,并标注为顶点数可变的多边形。
- The Chinese Text in the Wild (CTW)[69] 数据集包含32285幅高分辨率街景图像,在字符级别进行注释,包括其底层字符类型、边界框和详细属性,例如是否使用word-art。该数据集是今为止最大的数据集,也是唯一包含详细注释的数据集。但是,它只为中文文本提供注释,而忽略了其他语言,例如英语。
- LSVT [70] 由两个数据集组成。一种是用单词边界框和单词内容完全标记的。另一个,虽然大得多,但只使用主导文本实例的单词内容进行注释。作者建议研究这样的部分标记数据,这些数据要在制作上简单得多。
- IIIT 5K Word [71] 是最大的场景文本识别数据集,包含数字和自然场景图像。它在字体、颜色、大小和其他噪音方面的差异使它成为迄今为止最具挑战性的一个。
4.2 评估方法
作为不同算法性能比较的指标,通常参考它们的精确度、召回率和F1分数。要计算这些性能指标,首先应该将预测的文本实例列表与GT标签相匹配。
- 精度,表示为P,计算为预测的文本实例与GT标签匹配的比例。
- Recall,用R表示,是在预测结果中有对应的GT标签的比例。
- F1分数计算公式为 F 1 = 2 ∗ P ∗ R P + R F_{1}=\frac{2 * P * R}{P+R} F1=P+R2∗P∗R,同时考虑精度和召回率。预测的实例和GT实例之间的匹配是第一位的。
4.2.1 文本检测
文本检测主要有两种不同的协议,基于IOU的PASCAL Eval和基于重叠的DetEval。它们在预测文本实例和GT实例的匹配标准上存在差异。
在下面的部分中,使用这些符号: S G T S_{GT} SGT是GT边界框的面积, S P S_{P} SP是预测边界框的面积, S I S_{I} SI是预测和GT边界框的相交面积, S U S_{U} SU是他们联合的面积。
- DetEval:精确度(即 S I S P \frac{S_{I}}{S_{P}} SPSI)和召回(即 S I S G T \frac{S_{I}}{S_{GT}} SGTSI)施加了限制。只有当两者都大于各自的阈值时,它们才会匹配在一起。
- PASCAL:基本思想是,如果预测和GT的交集,即 S I S U \frac{S_{I}}{S_{U}} SUSI大于指定的阈值,则预测和GT边界框将匹配在一起。
大多数方法遵循两种评估协议中的任何一种,但有一些小的修改:
- ICDAR-2003/2005:匹配分数m的计算方法与IOU类似。它被定义为相交面积与包含两者的最小矩形边界框的面积之比。
- ICDAR-2011/2013:ICDAR2003/2005评估协议的一个主要缺陷是它只考虑一对一匹配。它没有考虑一对一、多对多、多对一的匹配,低估了实际性能。因此,ICDAR2011/2013采用:一对一匹配的得分为1,其他两种类型的匹配被惩罚为小于1的常数,通常设置为0.8。
- MSRA-TD 500:提出了一种新的旋转边界框盒评估协议,其中预测和GT边界框都围绕其中心水平旋转。只有当标准IOU分数高于阈值且原始边界框的旋转小于预定义值(在实践中为Pi/4)时,才匹配它们。
- TIoU:紧密性IoU考虑到场景文本识别对检测结果中的缺失部分和多余部分非常敏感。未检索的区域将导致识别结果中缺少字符,冗余区域将导致意外字符。建议的度量标准通过按缺失区域的比例和与其他文本重叠的多余区域的比例缩小IOUs来惩罚IOUs。
现有评价方案的主要缺点是只考虑在任意选择的置信阈值下对测试集的最优F1分数。应该用一般目标检测中广泛采用的平均精度(AP)度量来评估他们的方法。F1分数只是精度-召回率曲线上的单点,而AP值考虑了整个精度-召回率曲线。因此,AP是一个更全面的指标,建议这一领域的研究人员使用AP而不是单独使用F1分数。
4.2.2 文本识别和端到端系统
在场景文本识别中,预测的文本串直接与GT进行比较。性能评估是在字符级的识别率(即识别多少个字符)或单词级(预测的单词是否与GT完全相同)。ICDAR还引入了基于编辑距离的性能评估。在端到端评估中,首先以与文本检测相似的方式执行匹配,然后比较文本内容。
端到端系统使用最广泛的数据集是ICDAR 2013(Karatzas et al.,2013)和ICDAR 2015(Karatzas et al.,2015)。对这两个数据集的评估是在两种不同的设置下进行的,即Word Spotting setting 和 End-toEnd setting [http://rrc.cvc.uab.es/files/Robust_Reading_2015_v02.pdf]。在Word Spotting下,性能评估只关注场景图像中出现在预先设计的词汇表中的文本实例,而忽略其他文本实例。相反,出现在场景图像中的所有文本实例都包含在“端到端”下。三种不同的词汇表提供给候选文本。它们包括强语境化、弱语境化和泛化(Strongly Contextualised, Weakly Contextualised, and Generic)。
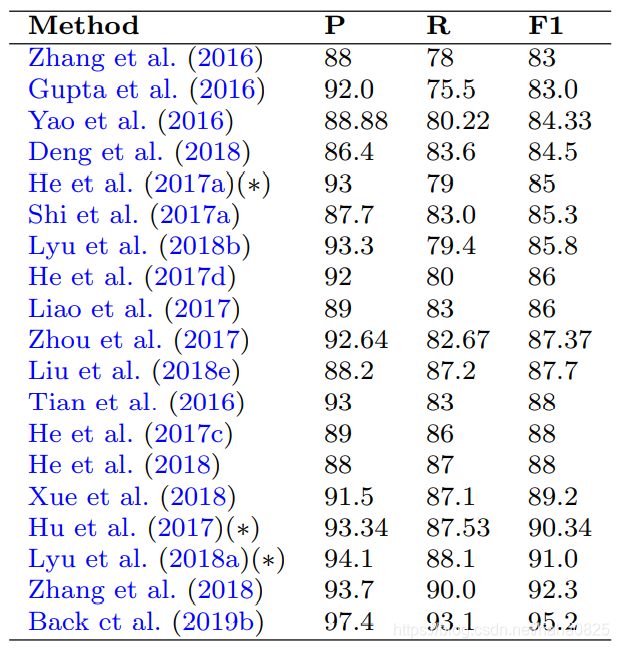
对几种广泛采用的基准数据集的最新方法的评价结果汇总如下表(用*表示多尺度性能的方法。由于一些工作中使用了不同的主干特征抽取器,所以除非没有提供,否则只报告基于ResNet-50的性能):
(1)Detection on ICDAR 2013
(2)Detection on ICDAR MLT 2017
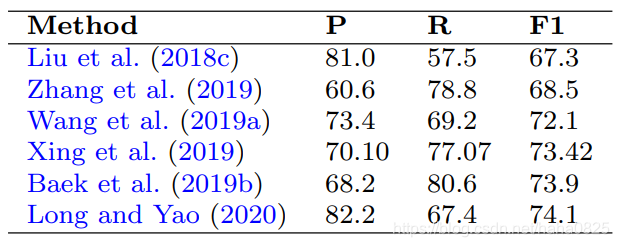
(3) Detection on ICDAR 2015

(4)Detection and end-to-end on Total-Text
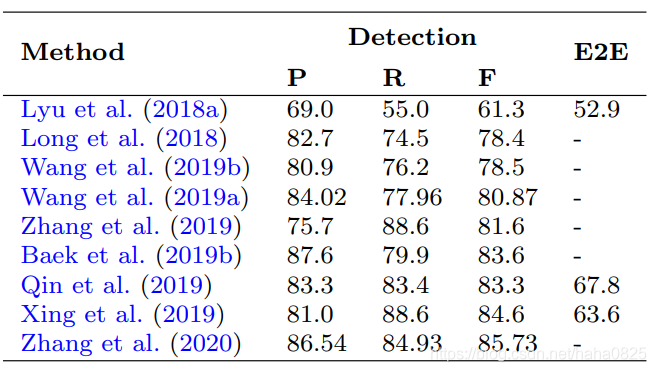
(5)Detection on CTW1500

(6)Detection on MSRA-TD 500

(7)识别
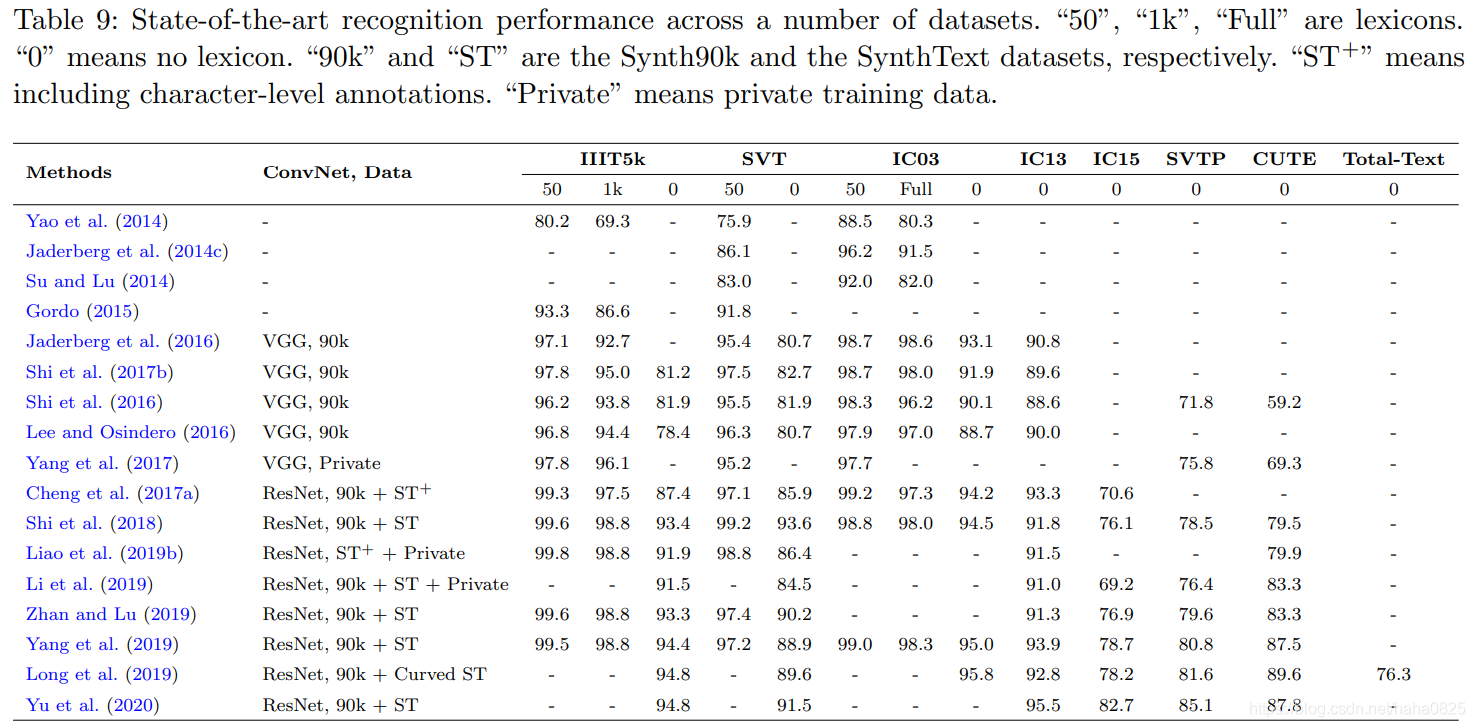
(8)Performance of End-to-End and Word Spotting on ICDAR 2015 and ICDAR 2013

请注意,当前场景文本识别的评估可能存在问题。大多数研究人员在引用同一个数据集时实际上使用了不同的子集,从而导致了性能的差异。此外,在广泛采用的基准数据集中,有一半的注释是不完善的,例如忽略区分大小写和标点符号,并为这些数据集提供新的注释。尽管大多数论文声称训练他们的模型以区分大小写的方式识别,并且还包括标点符号,但他们可能会在评估时将其输出限制为数字和不区分大小写的字符。
参考文献
[1] Liao, B. Shi, X. Bai, X. Wang, and W. Liu.Textboxes: A fast text detector with a single deep neural network. In AAAI, pages 4161–4167, 2017
[2] Zhou, C. Yao, H. Wen, Y. Wang, S. Zhou, W. He,and J. Liang. EAST: An efficient and accurate scene text detector. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[3] Ma, W. Shao, H. Ye, L. Wang, H. Wang, Y. Zheng,and X. Xue. Arbitrary-oriented scene text detection via rotation proposals. In IEEE Transactions on Multimedia, 2018, 2017.
[4] Zhang, Y. Liu, L. Jin, and C. Luo. Feature enhancement network: A refined scene text detector. In Proceedings of AAAI, 2018, 2018.
[5] Zhan and S. Lu. Esir: End-to-end scene text recognition via iterative image rectification. In Proceedings of the IEEE Conference on Computer Vision
and Pattern Recognition, 2019.
[6] Wang, L. Zhao, X. Li, X. Wang, and D. Tao.Geometry-aware scene text detection with instance transformation network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1381–1389, 2018.
[7] Liu, L. Jin, S. Zhang, and S. Zhang. Detecting curve text in the wild: New dataset and new solution. arXiv preprint arXiv:1712.02170, 2017.
[8] Hochreiter and J. Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
[9] Wang, Y. Jiang, Z. Luo, C.-L. Liu, H. Choi, and S. Kim. Arbitrary shape scene text detection with adaptive text region representation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6449–6458, 2019b.
[10]
[11] Deng, H. Liu, X. Li, and D. Cai. Pixellink: Detecting
scene text via instance segmentation. In Proceedings of AAAI, 2018, 2018.
[12] Wu and P. Natarajan. Self-organized text detection
with minimal post-processing via border learning. In Proceedings of the IEEE Conference on CVPR, pages
5000–5009, 2017
[13] Wang, F. Yin, and C.-L. Liu. Scene text detection with novel superpixel based character candidate extraction. In 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), volume 1, pages 929–934. IEEE, 2017.
[14] Tian, M. Shu, P. Lyu, R. Li, C. Zhou, X. Shen, and
J. Jia. Learning shape-aware embedding for scene text detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4234–4243, 2019
[15] . Wang, E. Xie, X. Li, W. Hou, T. Lu, G. Yu, and S. Shao. Shape robust text detection with progressive scale expansion network. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019a
[16] Tian, W. Huang, T. He, P. He, and Y. Qiao. Detecting text in natural image with connectionist text proposal network. In In Proceedings of European Conference on Computer Vision (ECCV), pages 56–72. Springer, 2016.
[17] Shi, X. Bai, and S. Belongie. Detecting oriented text in natural images by linking segments. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017a.
[18] Zhang, X. Zhu, J.-B. Hou, C. Liu, C. Yang,H. Wang, and X.-C. Yin. Deep relational reasoning graph network for arbitrary shape text detection. arXiv preprint arXiv:2003.07493, 2020.
[19] Lyu, C. Yao, W. Wu, S. Yan, and X. Bai. Multioriented scene text detection via corner localization and region segmentation. In 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018b.
[20] Long, J. Ruan, W. Zhang, X. He, W. Wu, and C. Yao. Textsnake: A flexible representation for detecting text of arbitrary shapes. In In Proceedings of European Conference on Computer Vision (ECCV),2018.
[21]
[22] Baek, B. Lee, D. Han, S. Yun, and H. Lee. Character region awareness for text detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 9365–9374, 2019b.
[23] He, W. Huang, Y. Qiao, C. C. Loy, and X. Tang. Reading scene text in deep convolutional sequences. In Thirtieth AAAI conference on artificial intelligence, 2016.
[24] Shi, X. Bai, and C. Yao. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE
transactions on pattern analysis and machine intelligence, 39(11):2298–2304, 2017b.
[25] Gao, Y. Chen, J. Wang, and H. Lu. Reading scene text with attention convolutional sequence modeling. arXiv preprint arXiv:1709.04303, 2017.
[26] Yin, Y.-C. Wu, X.-Y. Zhang, and C.-L. Liu. Scene text recognition with sliding convolutional character models. arXiv preprint arXiv:1709.01727, 2017.
[27] Sutskever, O. Vinyals, and Q. V. Le. Sequence to sequence learning with neural networks. In Advances in neural information processing systems, pages 3104– 3112, 2014.
[28] Liu, C. Chen, K.-Y. K. Wong, Z. Su, and J. Han. Star-net: A spatial attention residue network for scene text recognition. In BMVC, volume 2, page 7,2016b.
[29] Cheng, F. Bai, Y. Xu, G. Zheng, S. Pu, and S. Zhou. Focusing attention: Towards accurate text recognition in natural images. In 2017 IEEE International Conference on Computer Vision (ICCV), pages 5086–5094. IEEE, 2017a.
[30] Bai, Z. Cheng, Y. Niu, S. Pu, and S. Zhou. Edit probability for scene text recognition. In CVPR 2018, 2018.
[31] Liu, Y. Li, F. Ren, H. Yu, and W. Goh. Squeezedtext:A real-time scene text recognition by binary convolutional encoder-decoder network. AAAI, 2018d.
[32] Shi, X. Wang, P. Lyu, C. Yao, and X. Bai. Robust scene text recognition with automatic rectification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4168–4176, 2016.
[33] Jaderberg, K. Simonyan, A. Zisserman, et al. Spatial transformer networks. In Advances in neural information processing systems, pages 2017–2025, 2015.
[34] Long, Y. Guan, B. Wang, K. Bian, and C. Yao. Alchemy: Techniques for rectification based irregular scene text recognition. arXiv preprint arXiv:1908.11834, 2019.
[35] Zhan and S. Lu. Esir: End-to-end scene text recognition via iterative image rectification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019.
[36] Yang, Y. Guan, M. Liao, X. He, K. Bian, S. Bai,C. Yao, and X. Bai. Symmetry-constrained rectification network for scene text recognition. In Proceedings of the IEEE International Conference on Computer Vision, pages 9147–9156, 2019.
[37] Yang, D. He, Z. Zhou, D. Kifer, and C. L. Giles. Learning to read irregular text with attention mechanisms. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI-17, pages 3280–3286, 2017.
[38] Cheng, X. Liu, F. Bai, Y. Niu, S. Pu, and S. Zhou. Arbitrarily-oriented text recognition. CVPR2018, 2017b.
[39] .Liu, C. Chen, and K. Wong. Char-net: A characteraware neural network for distorted scene text recognition. In AAAI Conference on Artificial Intelligence. New Orleans, Louisiana, USA, 2018b.
[40] Liao, J. Zhang, Z. Wan, F. Xie, J. Liang, P. Lyu, C. Yao, and X. Bai. Scene text recognition from twodimensional perspective. AAAI, 2019b.
[41] Xu, J. Ba, R. Kiros, K. Cho, A. Courville,R. Salakhudinov, R. Zemel, and Y. Bengio. Show, attend and tell: Neural image caption generation with visual attention. In International Conference on Machine Learning, pages 2048–2057, 2015.
[42] Li, P. Wang, C. Shen, and G. Zhang. Show, attend and read: A simple and strong baseline for irregular text recognition. AAAI, 2019.
[43] Long, Y. Guan, K. Bian, and C. Yao. A new perspective for flexible feature gathering in scene text recognition via character anchor pooling. In ICASSP
2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 2458–2462. IEEE, 2020.
[44] Qin, A. Bissacco, M. Raptis, Y. Fujii, and Y. Xiao. Towards unconstrained end-to-end text spotting. In Proceedings of the IEEE International Conference on Computer Vision, pages 4704–4714, 2019.
[45] Long, Y. Guan, B. Wang, K. Bian, and C. Yao. Alchemy: Techniques for rectification based irregular scene text recognition. arXiv preprint arXiv:1908.11834, 2019.
[46] Jaderberg, K. Simonyan, A. Vedaldi, and A. Zisserman. Deep structured output learning for unconstrained text recognition. ICLR2015, 2014a.
[47] Yu, X. Li, C. Zhang, J. Han, J. Liu, and E. Ding. Towards accurate scene text recognition with semantic reasoning networks. arXiv preprint arXiv:2003.12294, 2020.
[48] Xia, F. Tian, L. Wu, J. Lin, T. Qin, N. Yu, and T.-Y. Liu. Deliberation networks: Sequence generation beyond one-pass decoding. In Advances in Neural Information Processing Systems, pages 1784–1794, 2017.
[49] Jaderberg, K. Simonyan, A. Vedaldi, and A. Zisserman. Reading text in the wild with convolutional neural networks. International Journal of Computer
Vision, 116(1):1–20, 2016.
[50] Liao, B. Shi, X. Bai, X. Wang, and W. Liu. Textboxes: A fast text detector with a single deep neural network. In AAAI, pages 4161–4167, 2017.
[51] Bartz, H. Yang, and C. Meinel. See: Towards semisupervised end-to-end scene text recognition. arXiv preprint arXiv:1712.05404, 2017.
[52] Li, P. Wang, and C. Shen. Towards end-to-end text spotting with convolutional recurrent neural networks. In The IEEE International Conference on Computer Vision (ICCV), 2017a.
[53] Liu, D. Liang, S. Yan, D. Chen, Y. Qiao, and J. Yan. Fots: Fast oriented text spotting with a unified network. CVPR2018, 2018c.
[54] Busta, L. Neumann, and J. Matas. Deep textspotter: An end-to-end trainable scene text localization and recognition framework. In Proc. ICCV, 2017.
[55] He, Z. Tian, W. Huang, C. Shen, Y. Qiao, and C. Sun. An end-to-end textspotter with explicit alignment and attention. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition (CVPR), pages 5020–5029, 2018.
[56] Lyu, M. Liao, C. Yao, W. Wu, and X. Bai. Mask textspotter: An end-to-end trainable neural network for spotting text with arbitrary shapes. In In Proceedings of European Conference on Computer Vision (ECCV), 2018a.
[57] Qin, A. Bissacco, M. Raptis, Y. Fujii, and Y. Xiao. Towards unconstrained end-to-end text spotting. In Proceedings of the IEEE International Conference on Computer Vision, pages 4704–4714, 2019.
[58] Xing, Z. Tian, W. Huang, and M. R. Scott. Convolutional character networks. In Proceedings of the IEEE International Conference on Computer Vision, pages 9126–9136, 2019.
[59] Jaderberg, K. Simonyan, A. Vedaldi, and A. Zisserman. Synthetic data and artificial neural networks for natural scene text recognition. arXiv preprint
arXiv:1406.2227, 2014b.
[60] Gupta, A. Vedaldi, and A. Zisserman. Synthetic data for text localisation in natural images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2315–2324,2016.
[61] . Zhan, S. Lu, and C. Xue. Verisimilar image synthesis for accurate detection and recognition of texts in scenes. 2018.
[62] Liao, B. Song, M. He, S. Long, C. Yao, and X. Bai. Synthtext3d: Synthesizing scene text images from 3d virtual worlds. arXiv preprint arXiv:1907.06007,2019a.
[63] Long and C. Yao. Unrealtext: Synthesizing realistic scene text images from the unreal world. arXiv preprint arXiv:2003.10608, 2020.
[64] Wu, C. Zhang, J. Liu, J. Han, J. Liu, E. Ding, and X. Bai. Editing text in the wild. In Proceedings of the 27th ACM International Conference on Multimedia,
pages 1500–1508, 2019.
[65] Yang, H. Jin, J. Huang, and W. Lin. Swaptext: Image based texts transfer in scenes. arXiv preprint arXiv:2003.08152, 2020.
[66] Karatzas, L. Gomez-Bigorda, A. Nicolaou, S. Ghosh, A. Bagdanov, M. Iwamura, J. Matas, L. Neumann, V. R. Chandrasekhar, S. Lu, et al. Icdar 2015 competition on robust reading. In 2015 13th International Conference on Document Analysis and Recognition (ICDAR), pages 1156–1160. IEEE, 2015.
[67] N. Nayef et al., “ICDAR2019 Robust Reading Challenge on Multi-lingual Scene Text Detection and Recognition — RRC-MLT-2019,” 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 2019.
[68] https://github.com/cs-chan/Total-Text-Dataset
[69] Yuan, Z. Zhu, K. Xu, C.-J. Li, and S.-M. Hu. Chinese text in the wild. arXiv preprint arXiv:1803.00085, 2018.
[70] Sun, J. Liu, W. Liu, J. Han, E. Ding, and J. Liu. Chinese street view text: Large-scale chinese text reading with partially supervised learning. In Proceedings of the IEEE International Conference on Computer Vision, pages 9086–9095, 2019.
[71] Mishra, K. Alahari, and C. Jawahar. Scene text recognition using higher order language priors. In BMVC-British Machine Vision Conference. BMVA,
2012.