
(图片来自百度)
数据
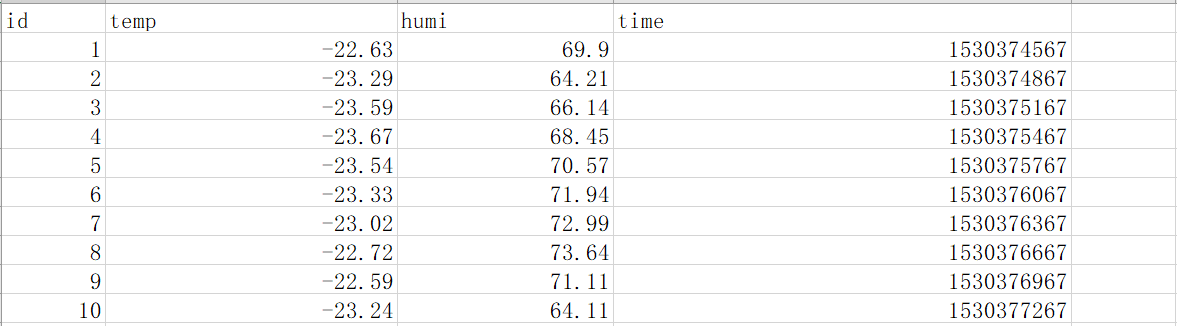
分析数据第一步还是套路------画图
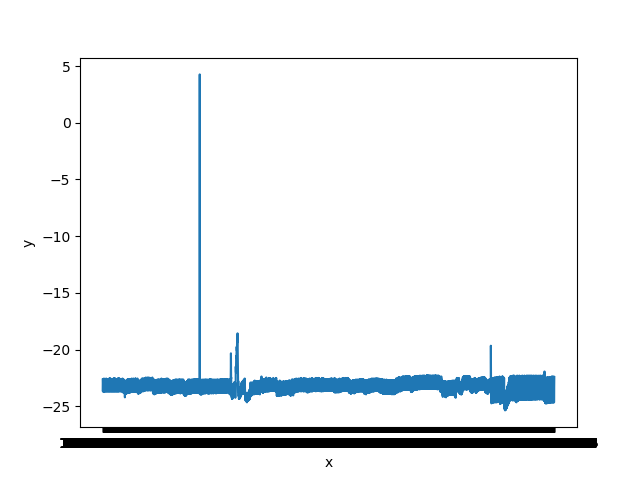
数据看上去比较平整,但是由于数据太对看不出具体情况,于是将只取前300个数据再此画图
这数据看上去很不错,感觉有隐藏周期的意思
代码
#coding:utf-8 import csv import matplotlib.pyplot as plt def read_csv_data(aim_list_1, aim_list_2, file_name): i = 0 csv_file = csv.reader(open(file_name,'r')) for data in csv_file: if (i == 0): i += 1 continue aim_list_1.append(float(data[1])) aim_list_2.append(data[3]) return def plot_picture(x, y): plt.xlabel('x') plt.ylabel('y') plt.plot(x, y) plt.show() return if __name__ == '__main__': temp = [] tim = [] file_name = 'C:/Users/lichaoxing/Desktop/testdata.csv' read_csv_data(temp, tim, file_name) plot_picture(tim[:300], temp[:300])
使用RAIMA模型(RAMA)

第一步观察数据是否是平稳序列,通过上图可以看出是平稳的
如果不平稳,则需要进行预处理,方法有 对数变换 差分
对于平稳的时间序列可以直接使用RAMA(p, q)模型进行拟合
RAMA (p, q) : RA(p) + MA(q)
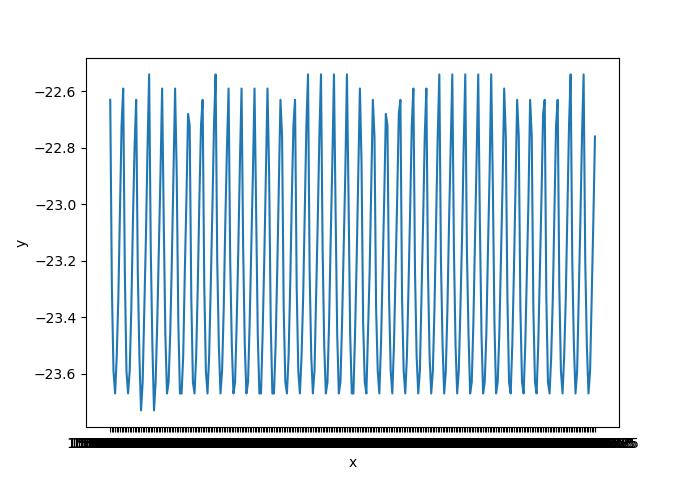
此时参数p和q的确定可以通过观察ACF和PACF图来确定
通过观察PACF图可以看出,阶数为9也就是p=9,这里ACF图看出自相关呈现震荡下降收敛,但是怎么决定出q,我没太明白,这里姑且拍脑袋才一个吧就q=3
但是这里我遇到了一个问题,没有搞懂,就是平稳的序列,如果我进行一阶差分后应该仍然是平稳的序列,但是这个时候我又画了一个ACF与PACF图,竟然是下图这样,lag的范围是-0.04到0.04(不懂)
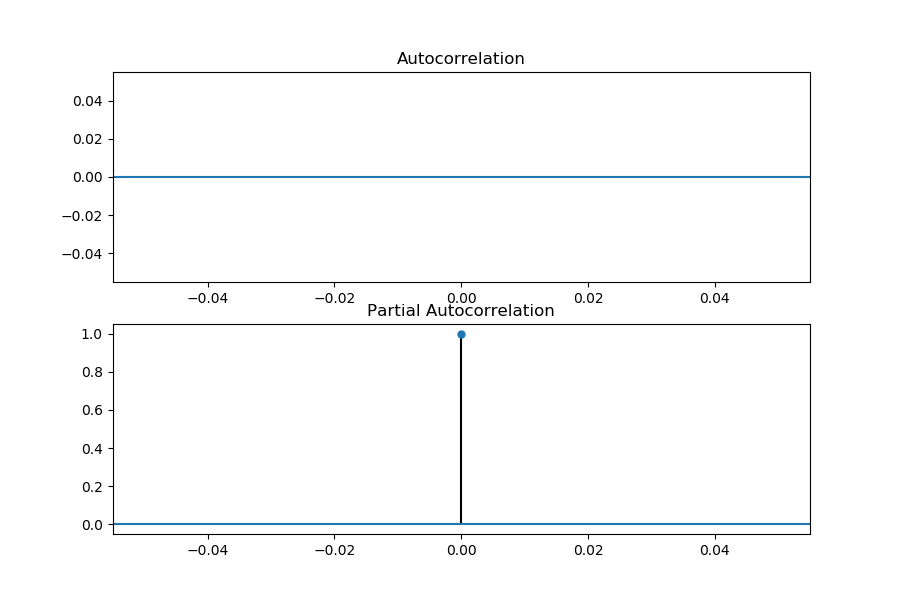
其实还有就是使用ADF检验,得到的结果如图,这个p值很小===》平稳

画图代码
def acf_pacf(temp, tim): x = tim y = temp dta = pd.Series(y, index = pd.to_datetime(x)) fig = plt.figure(figsize=(9,6)) ax1 = fig.add_subplot(211) fig = sm.graphics.tsa.plot_acf(dta,lags=50,ax=ax1) ax2 = fig.add_subplot(212) fig = sm.graphics.tsa.plot_pacf(dta,lags=50,ax=ax2) show()
ADF检验代码
def test_stationarity(timeseries): dftest = adfuller(timeseries, autolag='AIC') return dftest[1]
这里先使用RAMA(9,3)来实验测试一下效果,取前300个数据中的前250个作为train,后面的作为test
效果
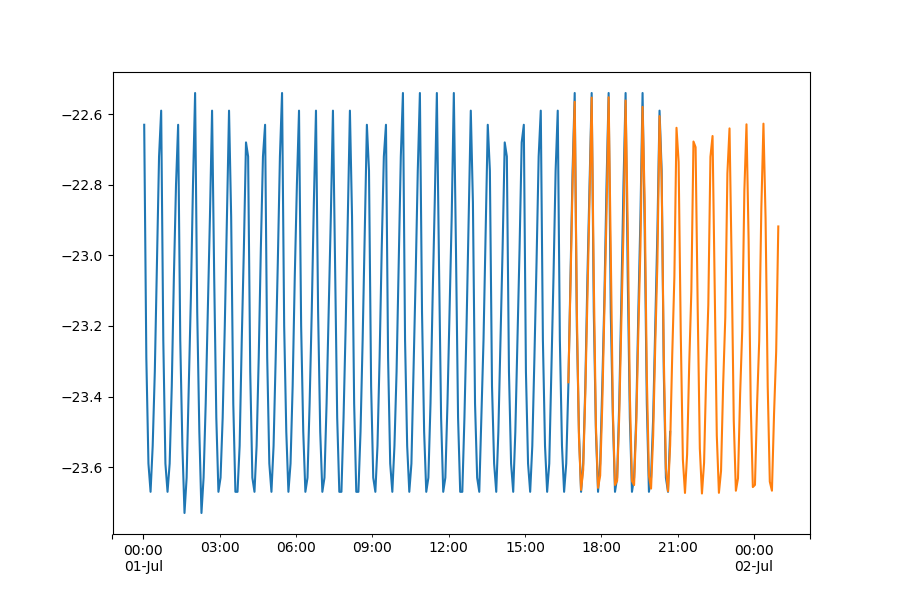
可以说这个模型是真的强大,预测的还是十分准确的
代码
def test_300(temp, tim): x = tim[0:300] y = temp[0:300] dta = pd.Series(y[0:249], index = pd.to_datetime(x[0:249])) fig = plt.figure(figsize=(9,6)) ax1 = fig.add_subplot(211) fig = sm.graphics.tsa.plot_acf(dta,lags=30,ax=ax1) ax2 = fig.add_subplot(212) fig = sm.graphics.tsa.plot_pacf(dta,lags=30,ax=ax2) arma_mod = sm.tsa.ARMA(dta, (9, 3)).fit(disp = 0) predict_sunspots = arma_mod.predict(x[200], x[299], dynamic=True) fig, ax = plt.subplots(figsize=(9, 6)) ax = dta.ix[x[0]:].plot(ax=ax) predict_sunspots.plot(ax=ax) show()
其实,可以通过代码来自动的选择p和q的值,依据IBC准则,目标就是ibc越小越好
代码
def proper_model(timeseries, maxLag): init_bic = 100000000 init_properModel = None for p in np.arange(maxLag): for q in np.arange(maxLag): model = ARMA(timeseries, order=(p, q)) try: results_ARMA = model.fit(disp = 0, method='css') except: continue bic = results_ARMA.bic if bic < init_bic: init_properModel = results_ARMA init_bic = bic return init_properModel
遇到的问题,预测时predict函数没怎么使用明白
当写于某些预测区间的时候,会报 “start”或“end”的相关错误,还有一个函数forcast,这个函数使用就是forcast(N):预测后面N个值
返回的是预测值(array型)标准误差(array型)置信区间(array型)

还有:
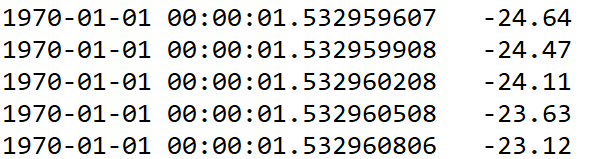
对于构造时间序列,时间可以是时间格式:如 “2018-01-01” 或者就是个时间戳,在用时间戳的时候,其实在序列里它会自动识别时间戳,并加上起始时间1970-01-01 00:00:01
形式
附录(代码)
预测一序列中某一点的值
#coding:utf-8 import csv import time import pandas as pd import numpy as np from statsmodels.tsa.arima_model import ARMA import argparse import warnings warnings.filterwarnings('ignore') def timestamp_datatime(value): value = time.localtime(value) dt = time.strftime('%Y-%m-%d %H:%M',value) return dt def time_timestamp(my_date): my_date_array = time.strptime(my_date,'%Y-%m-%d %H:%M') my_date_stamp = time.mktime(my_date_array) return my_date_stamp def read_csv_data(aim_list_1, aim_list_2, file_name): i = 0 csv_file = csv.reader(open(file_name,'r')) for data in csv_file: if (i == 0): i += 1 continue aim_list_1.append(float(data[1])) #1:温度 2:湿度 dt = int(data[3]) aim_list_2.append(dt) return def proper_model(timeseries, maxLag): init_bic = 100000000 init_properModel = None for p in np.arange(maxLag): for q in np.arange(maxLag): model = ARMA(timeseries, order=(p, q)) #bug try: results_ARMA = model.fit(disp = 0, method='css') except: continue bic = results_ARMA.bic if bic < init_bic: init_properModel = results_ARMA init_bic = bic return init_properModel def test_300(temp, tim, time_in): x = [] y = [] end_index = len(tim) for i in range(0, len(tim)): if (time_in - (tim[i]) < 300): end_index = i break if (end_index < 100): x = tim[0: end_index] y = temp[0: end_index] else: x = tim[end_index - 100: end_index] y = temp[end_index - 100: end_index] tidx = pd.DatetimeIndex(x, freq='infer') dta = pd.Series(y, index = tidx) print(dta) arma_mod = proper_model(dta, 9) predict_sunspots = arma_mod.forecast(1) return predict_sunspots[0] def predict_temperature(file_name, time_in): temp = [] tim = [] read_csv_data(temp, tim, file_name) result_temp = test_300(temp, tim, time_in) return result_temp if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument('-f', action='store', dest='file_name') parser.add_argument('-t', action='store', type = int, dest='time_') args = parser.parse_args() file_name = args.file_name time_in = args.time_ result_temp = predict_temperature(file_name, time_in) print ('the temperature is %f ' % result_temp)
在上面的代码中,预测某一点的值我采用序列中此点的前100个点作为训练集
如果给出待预测的多个点,由于每次都要计算模型的p和q以及拟合模型,时间会很慢,于是考虑将给定的待预测时间点序列切割成小段,使每一段中最大与最小的时间间隔在某一范围内
在使用forcast(n)函数一次预测多点,然后在预测值中找到与待预测的时间值相近的值,速度大大提升,思路如图
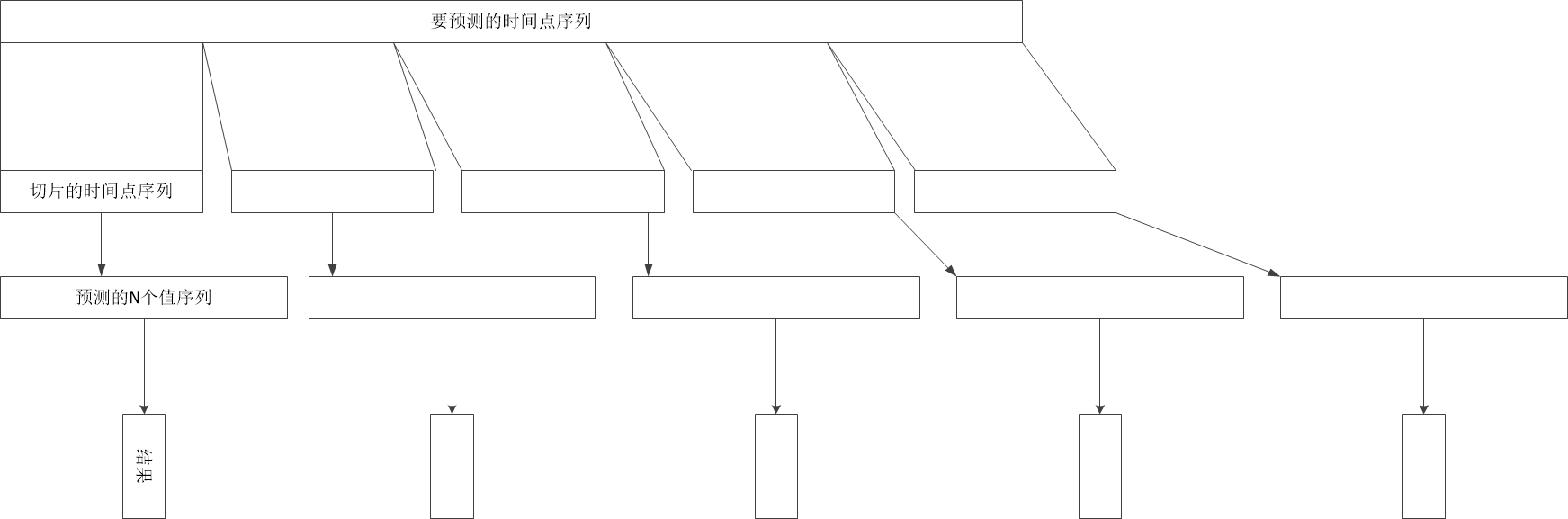
代码
#coding:utf-8 import csv #import time import pandas as pd import numpy as np from statsmodels.tsa.arima_model import ARMA import warnings warnings.filterwarnings('ignore') def proper_model(timeseries, maxLag): init_bic = 1000000000 init_p = 1 init_q = 1 for p in np.arange(maxLag): for q in np.arange(maxLag): model = ARMA(timeseries, order=(p, q)) try: results_ARMA = model.fit(disp = 0, method='css') except: continue bic = results_ARMA.bic if bic < init_bic: init_p = p init_q = q init_bic = bic return init_p, init_q def read_csv_data(file_name, clss = 1): i = 0 aim_list_1 = [] #temperature(1) or humidity(2) aim_list_2 = [] #time csv_file = csv.reader(open(file_name,'r')) for data in csv_file: if (i == 0): i += 1 continue aim_list_1.append(float(data[clss])) dt = int(data[3]) aim_list_2.append(dt) tidx = pd.DatetimeIndex(aim_list_2, freq = None) dta = pd.Series(aim_list_1, index = tidx) init_p, init_q = proper_model(dta[:aim_list_2[100]], 9) return init_p, init_q, aim_list_2, dta def for_kernel(p, q, tim, dta, tmp_time_list, result_dict): interval = 20 end_index = len(tim) - 1 for i in range(0, len(tim)): if (tmp_time_list[0]["time"] - tim[i] < tim[1] - tim[0]): end_index = i break if (end_index < 100): dta = dta.truncate(after = tim[end_index]) else: dta = dta.truncate(before= tim[end_index - 101], after = tim[end_index]) arma_mod = ARMA(dta, order=(p, q)).fit(disp = 0, method='css') #为未来interval天进行预测, 返回预测结果, 标准误差, 和置信区间 predict_sunspots = arma_mod.forecast(interval) #################################### for tim_i in tmp_time_list: for tim_ in tim: if tim_i["time"] - tim_ >= 0 and tim_i["time"] - tim_ < tim[1] - tim[0]: result_dict[tim_i["time"]] = predict_sunspots[0][tim.index(tim_) - end_index] return def kernel(p, q, tim, dta, time_in_list): interval = 20 time_first = time_in_list[0] det_time = tim[1] - tim[0] result_dict = {} tmp_time_list = [] for time_ in time_in_list: if time_first["time"] + det_time * interval > time_["time"]: tmp_time_list.append(time_) continue time_first = time_ for_kernel(p, q, tim, dta, tmp_time_list, result_dict) tmp_time_list = [] tmp_time_list.append(time_first) for_kernel(p, q, tim, dta, tmp_time_list, result_dict) return result_dict def predict_temperature(file_name, time_in_list, clss = 1): p, q, tim, dta = read_csv_data(file_name, clss) result_temp_dict = kernel(p, q, tim, dta, time_in_list) return result_temp_dict def predict_humidity(file_name, time_in_list, clss = 2): p, q, tim, dta = read_csv_data(file_name, clss) result_humi_dict = kernel(p, q, tim, dta, time_in_list) return result_humi_dict if __name__ == '__main__': file_name = "testdata.csv" time_in = [{"time":1530419271,"temp":"","humi":""},{"time":1530600187,"temp":"","humi":""},{"time":1530825809,"temp":"","humi":""}] #time_in = [{"time":1530600187,"temp":"","humi":""},] result_temp = predict_temperature(file_name, time_in) print(result_temp)
参考(作者写的很不错,感谢分享):
https://blog.csdn.net/u011596455/article/details/78650517
https://www.cnblogs.com/xuanlvshu/p/5410721.html
http://www.cnblogs.com/foley/p/5582358.html
后记:还有好多不明白的地方,需要进一步探究,但是对于学习一项新的知识,我觉得还是要先把车开起来,用它解决问题,这样对于后续的理解也会有很大的帮助