基于Transformer时间序列预测模型
特色:1、单变量,多变量输入,自由切换
2、单步预测,多步预测,自动切换
3、基于Pytorch架构
4、多个评估指标(MAE,MSE,R2,MAPE等)
5、数据从excel文件中读取,更换简单
6、标准框架,数据分为训练集、验证集,测试集
全部完整的代码,保证可以运行的代码看这里。
http://t.csdn.cn/obJlC![]() http://t.csdn.cn/obJlC
http://t.csdn.cn/obJlC
!!!如果第一个链接打不开,请点击个人首页,查看我的个人介绍。
(搜索到的产品后,点头像,就能看到全部代码)
黑科技小土豆的博客_CSDN博客-深度学习,32单片机领域博主

Transformer 模型是一种基于自注意力机制的神经网络模型,由 Google 在 2017 年提出,用于处理序列到序列(sequence-to-sequence)的自然语言处理任务。相较于传统的循环神经网络(RNN)、卷积神经网络(CNN)模型,Transformer 模型不需处理输入序列的时序关系,能够更好地捕捉序列间的全局关系,提高模型的性能。
Transformer 模型源于 encoder-decoder 框架,其中 encoder 用于将输入序列转换成一组特征向量,decoder 用于将这些特征向量转化到输出序列。Transformer利用自注意力机制代替了传统 RNN 模型中的循环意见机制。
Transformer 模型的优点包括:
- Transformer 模型通过自注意力机制处理序列数据,可以直接对整个序列建模,捕捉序列之间的全局关系,极大提高了建模效率和精度。
- Transformer 模型中的多头注意力机制使其具有更好的可解释性,并且能够较好地处理较长序列和大规模数据。
因此,Transformer 模型是一种适用于自然语言处理、语言翻译、词向量处理等领域的强有力的深度学习模型,在文本生成、情感分析、智能问答等任务中表现优异。
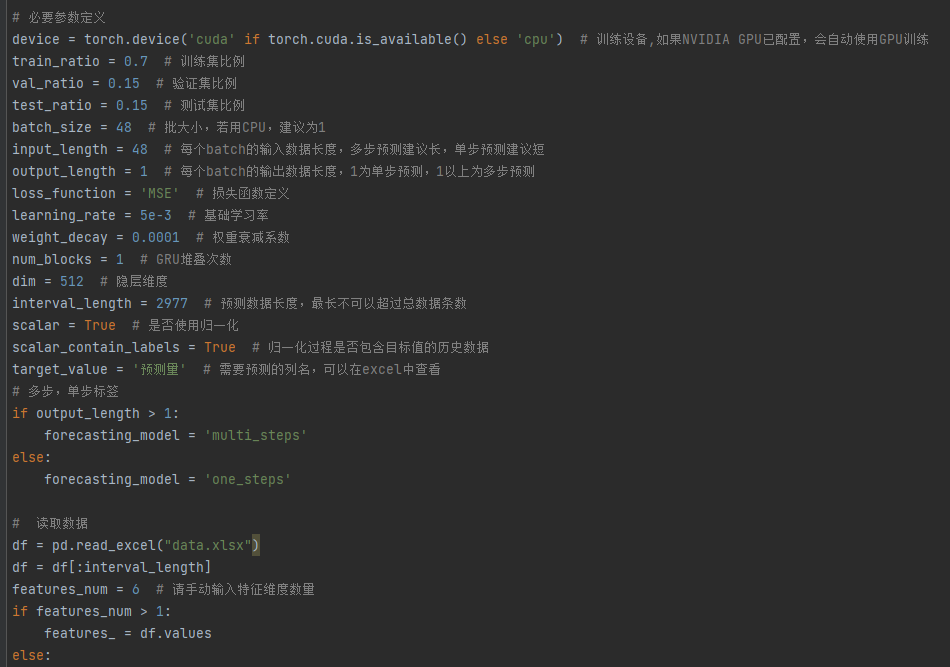
train_ratio = 0.7 # 训练集比例
val_ratio = 0.15 # 验证集比例
test_ratio = 0.15 # 测试集比例
input_length = 48 # 输入数据长度,多步预测建议长,单步预测建议短
output_length = 1 # 输出数据长度,1为单步预测,1以上为多步预测 请注意,随着输出长度的增长,模型训练时间呈指数级增长
learning_rate = 0.1 # 学习率
estimators = 100 # 迭代次数
max_depth = 5 # 树模型的最大深度
interval_length = 2000 # 预测数据长度,最长不可以超过总数据条数
scalar = True # 是否使用归一化
scalar_contain_labels = True # 归一化过程是否包含目标值的历史数据
target_value = 'load' # 需要预测的列名,可以在excel中查看