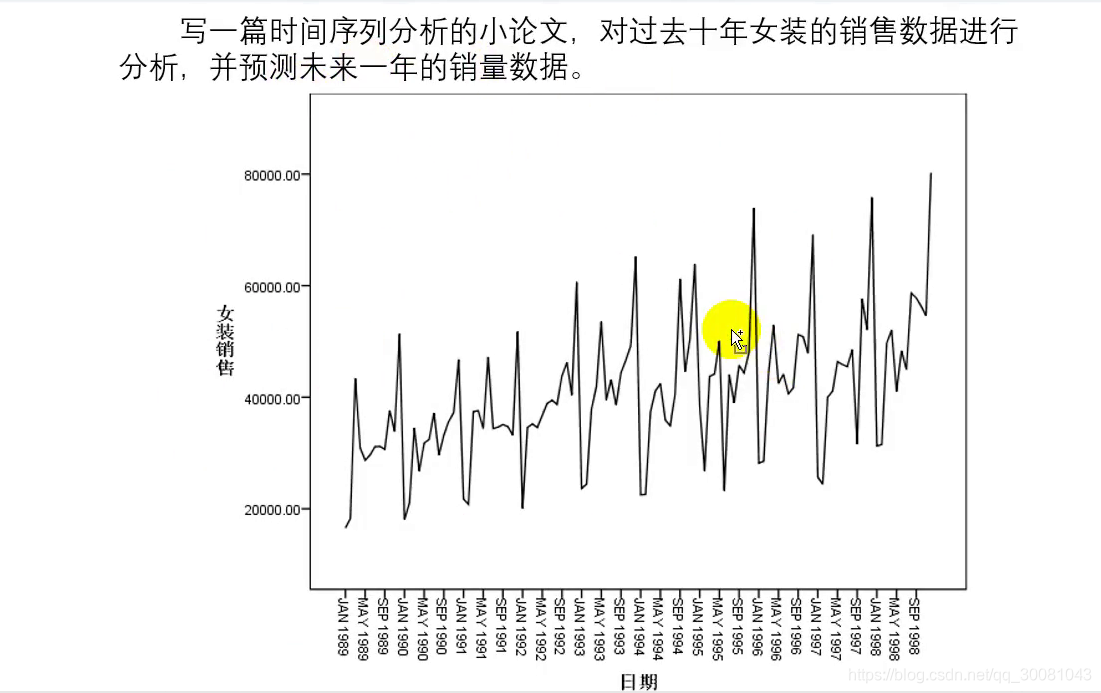
第1部分_时间序列分析的概念与时间序列分解模型

时间序列
时间序列的基本概念

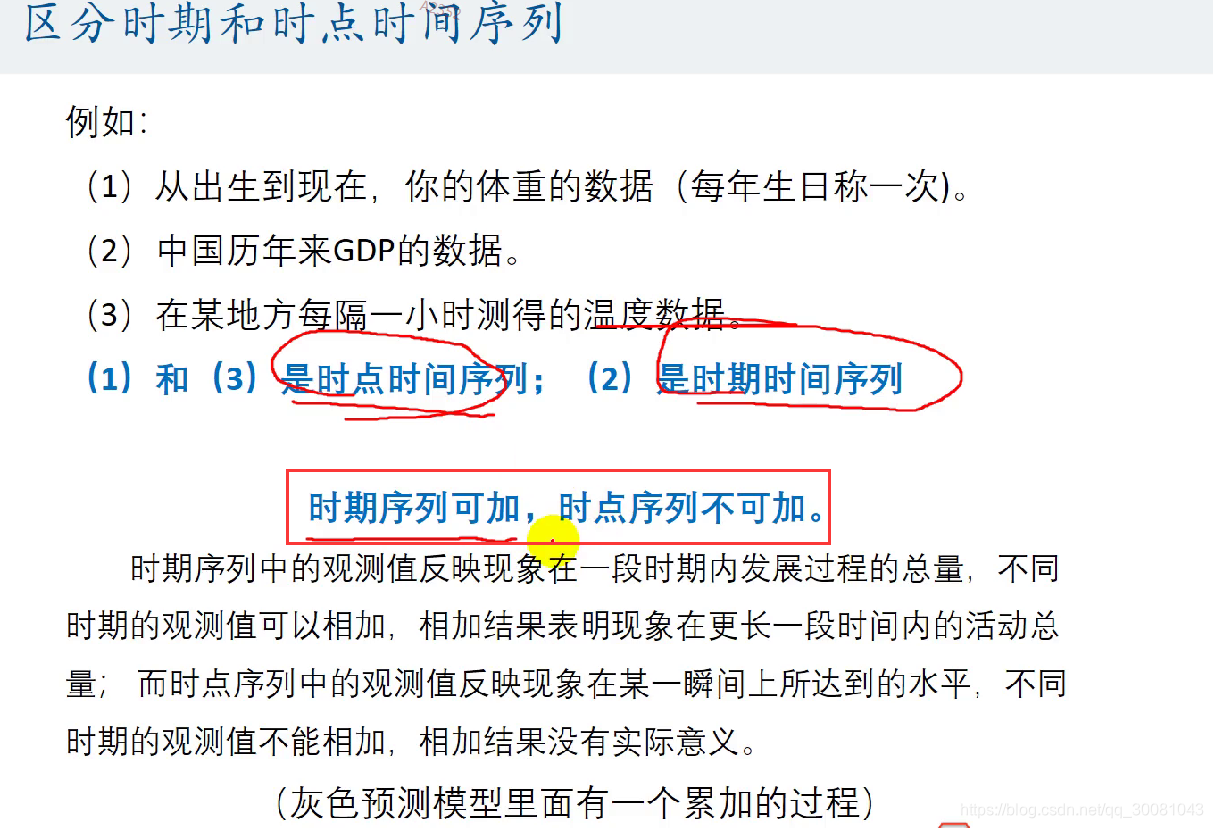
区分时期和时点序列
时期序列适用于灰色预测模型
时间序列分解
时间要小于1年,才能进行时间序列分解
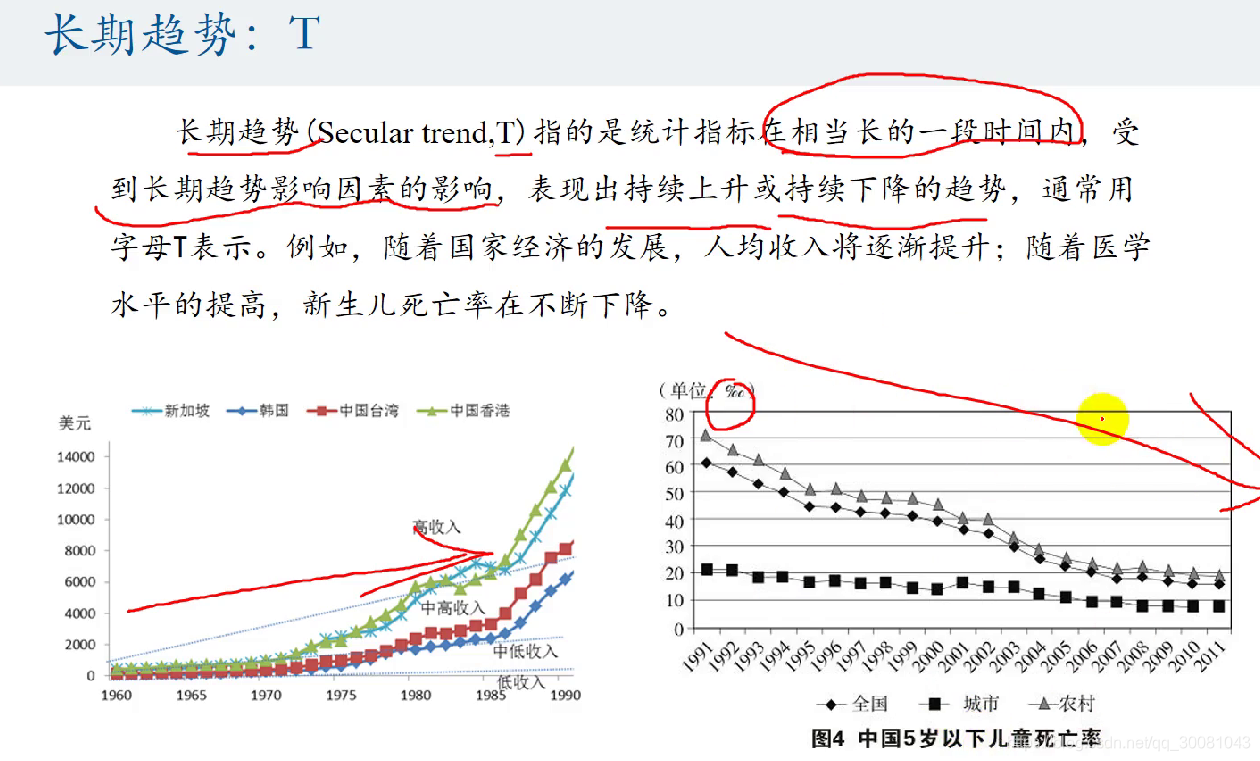
长期变动趋势 T
季节趋势 S
百度指数可以参考
不规则变动 (随机扰动项) I
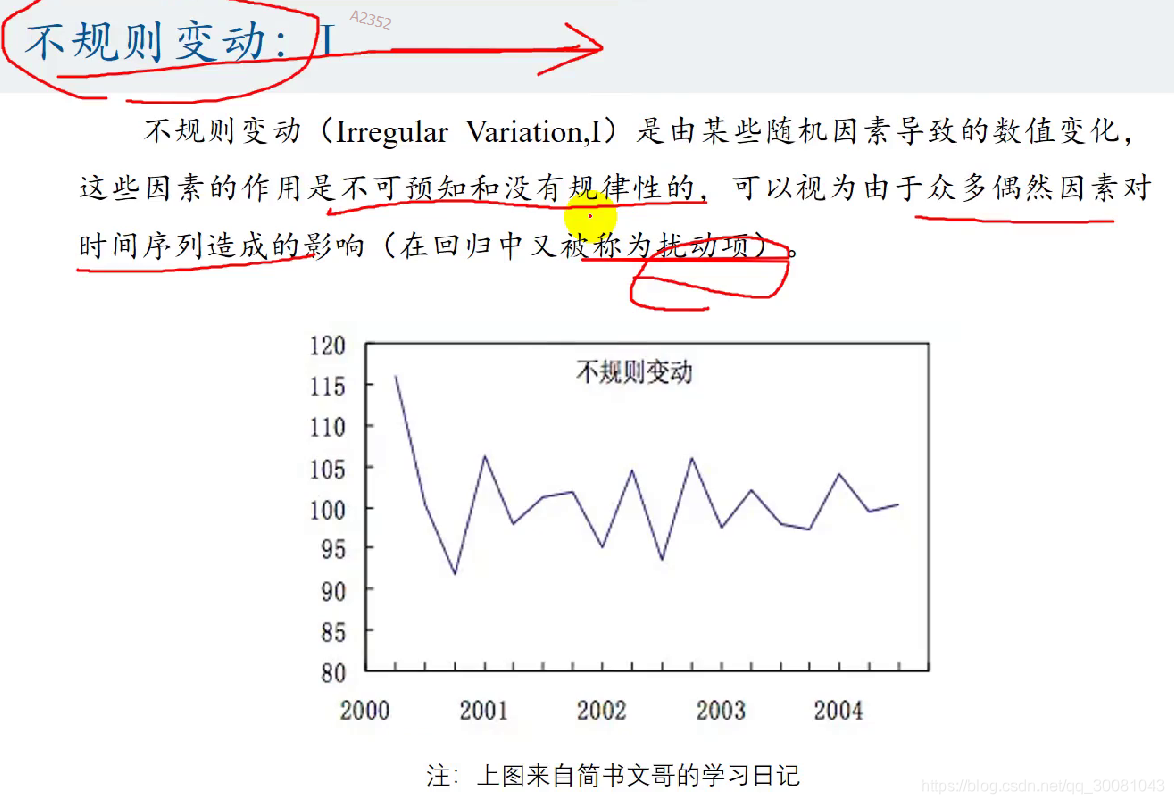
叠加模型和乘积模型
年份数据不能使用时间序列分解。
SPSS处理时间序列中的缺失值
如果缺失值在开头或者结尾,则直接删除缺失值即可。
如果缺失值在中间,则需要用SPSS来替换缺失值。
转换-替换缺失值
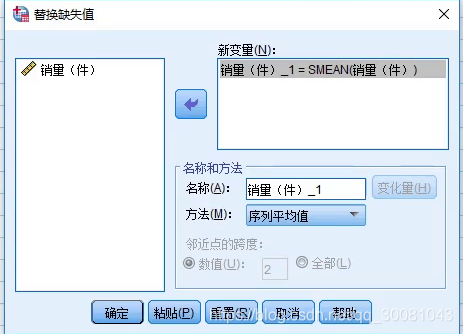
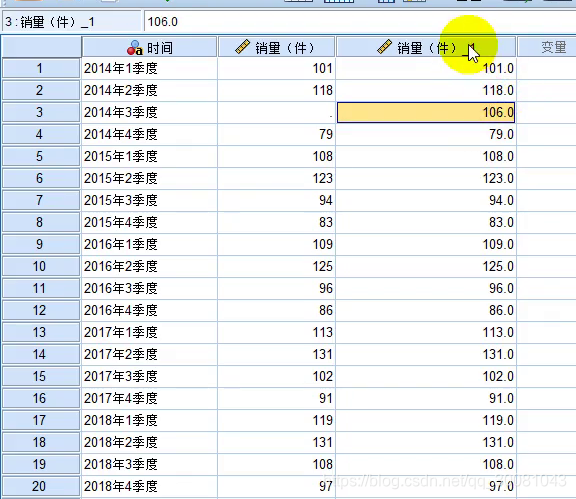
替换缺失值的五种方法
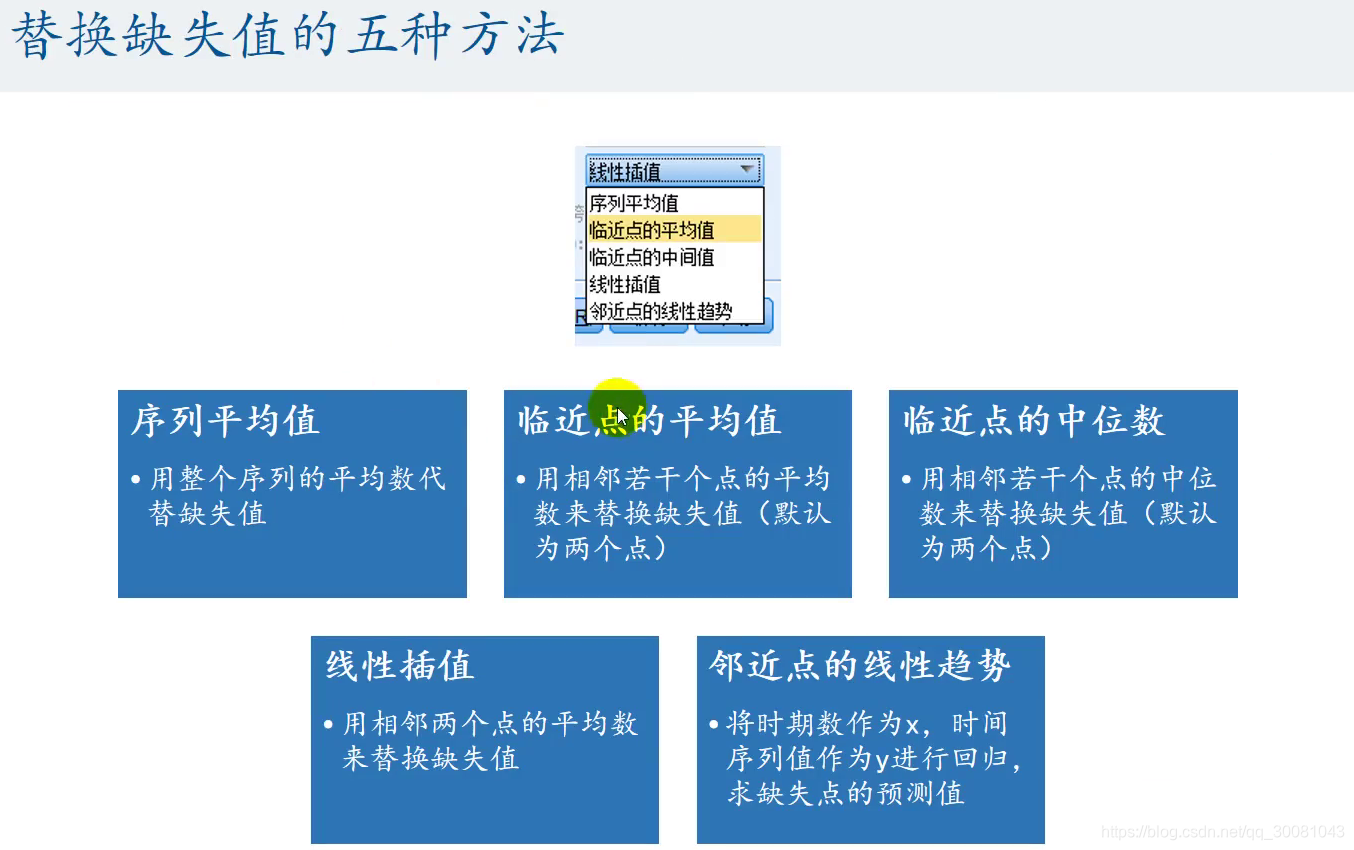
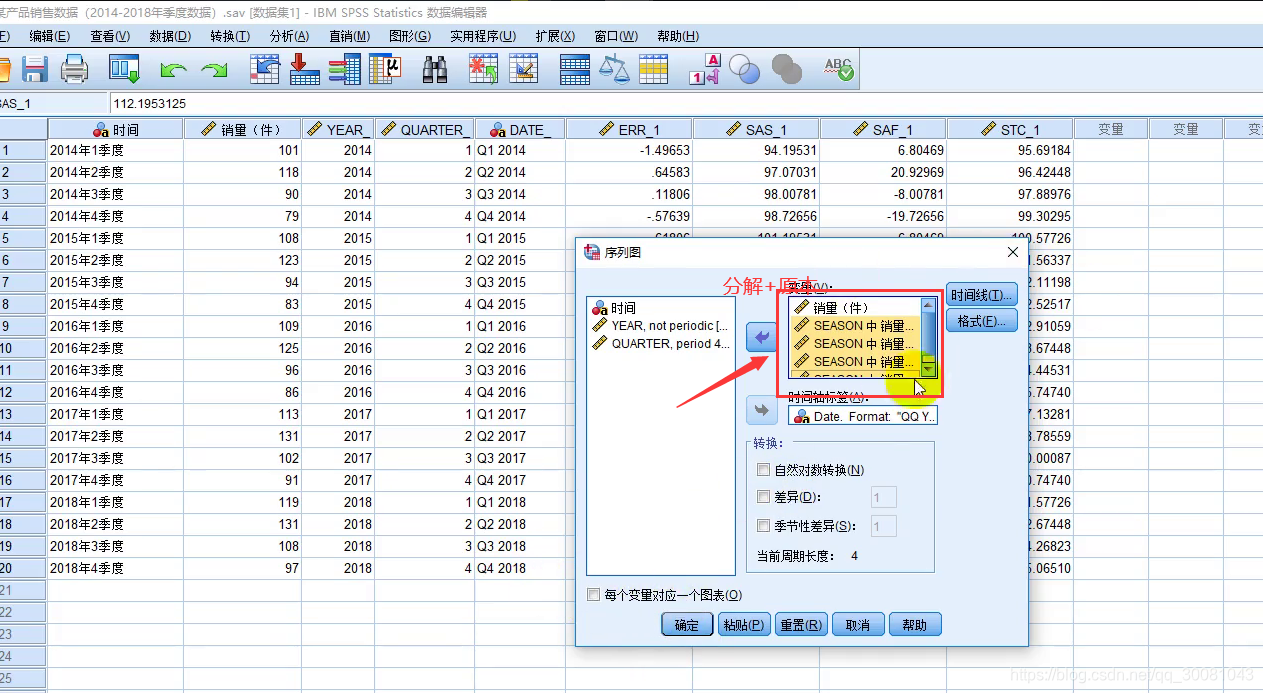
SPSS软件定义时间变量
- 数据-定义日期和时间
- 选择合适的日期时间格式
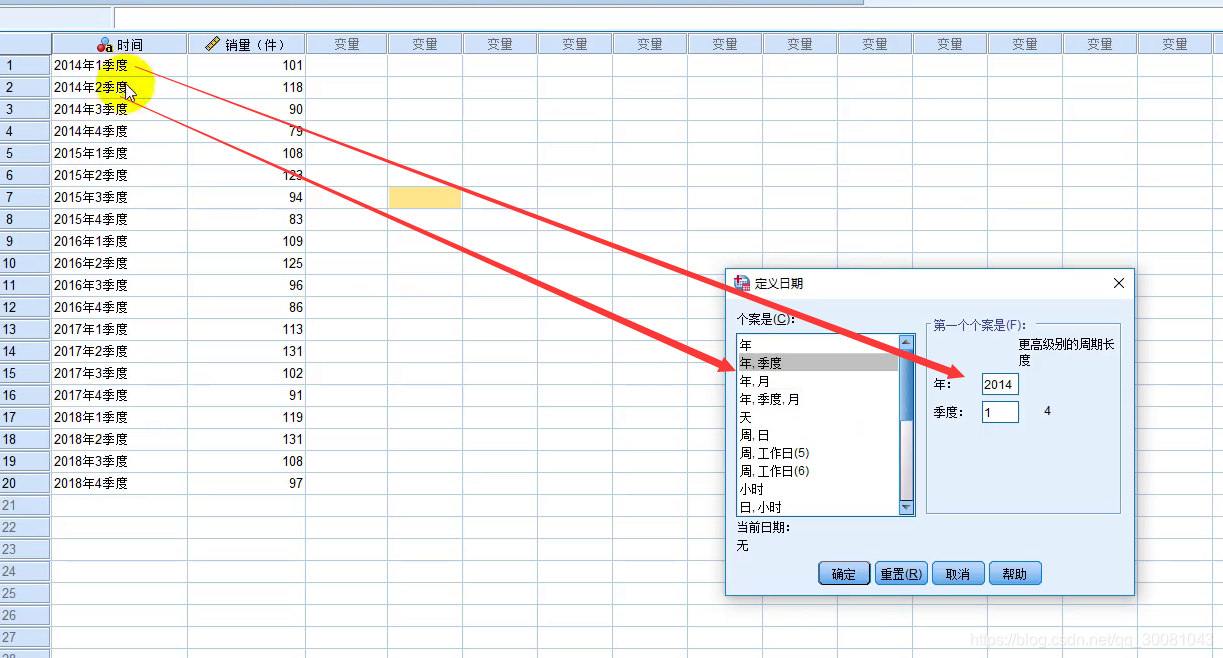
时间序列图
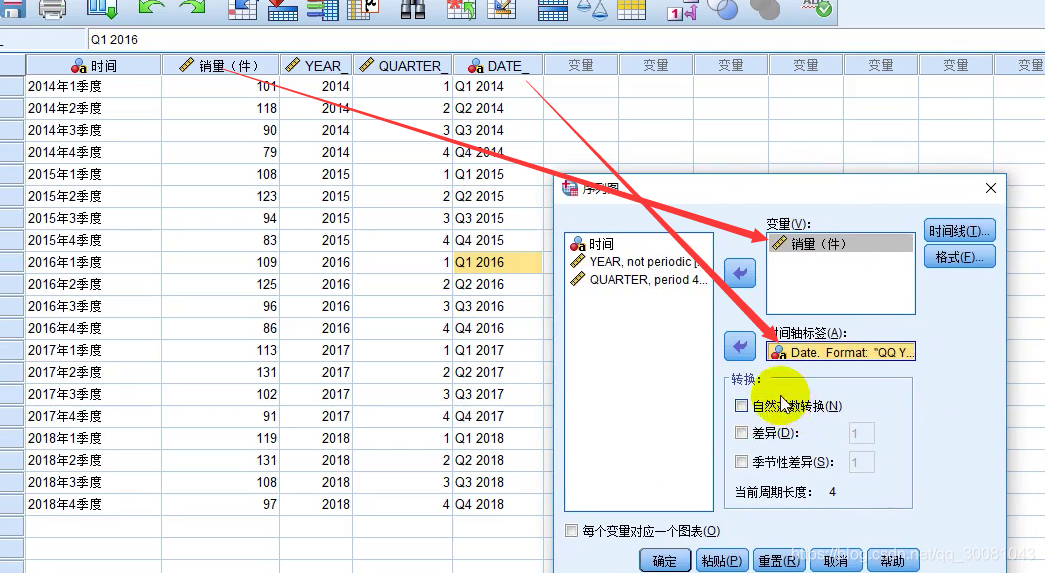
季节性分解

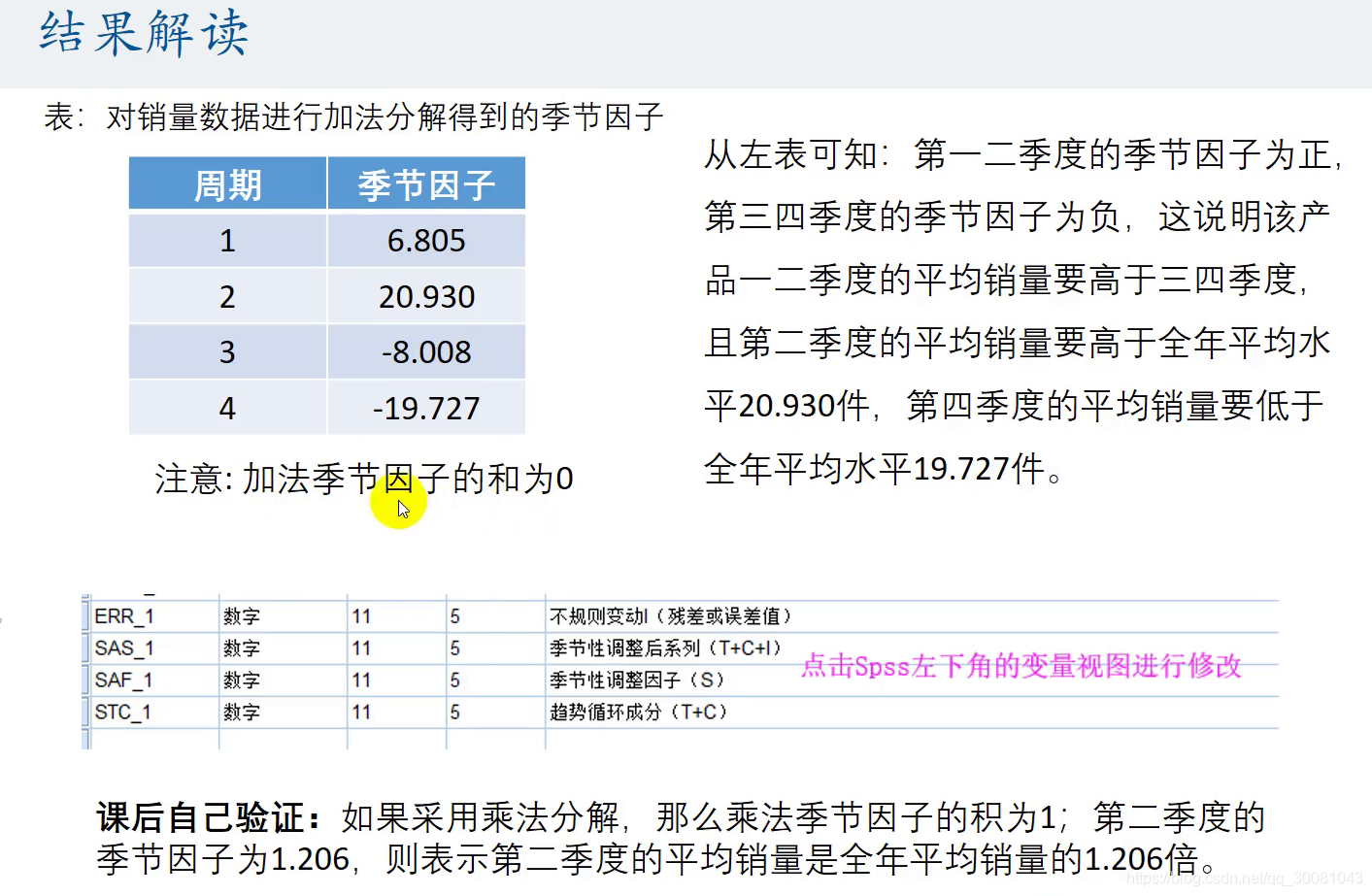
结果解读
乘法分解
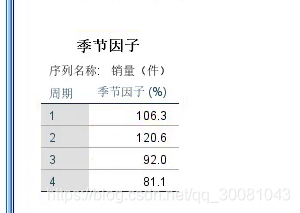
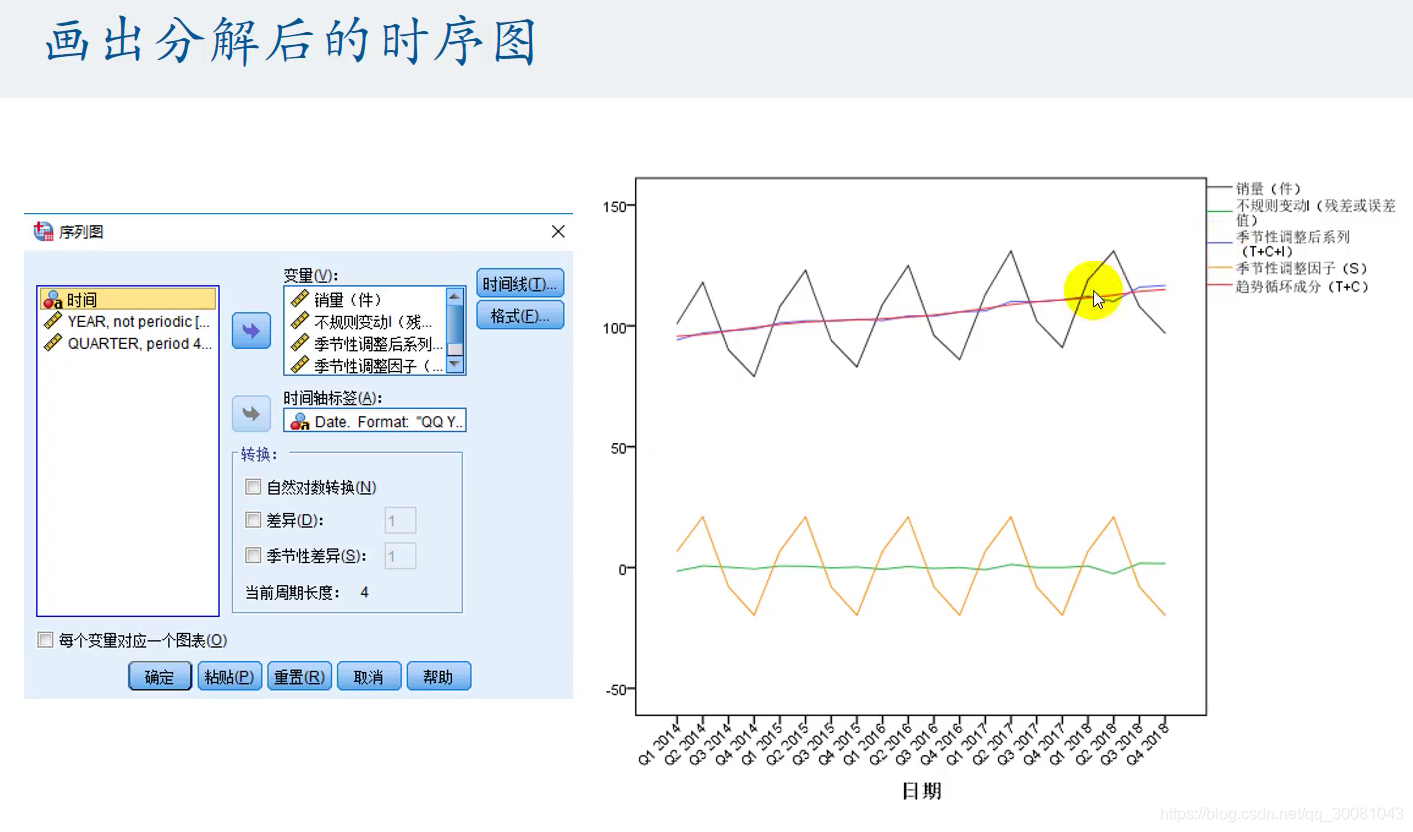
画出分解值之后的图
建立时间序列分析模型
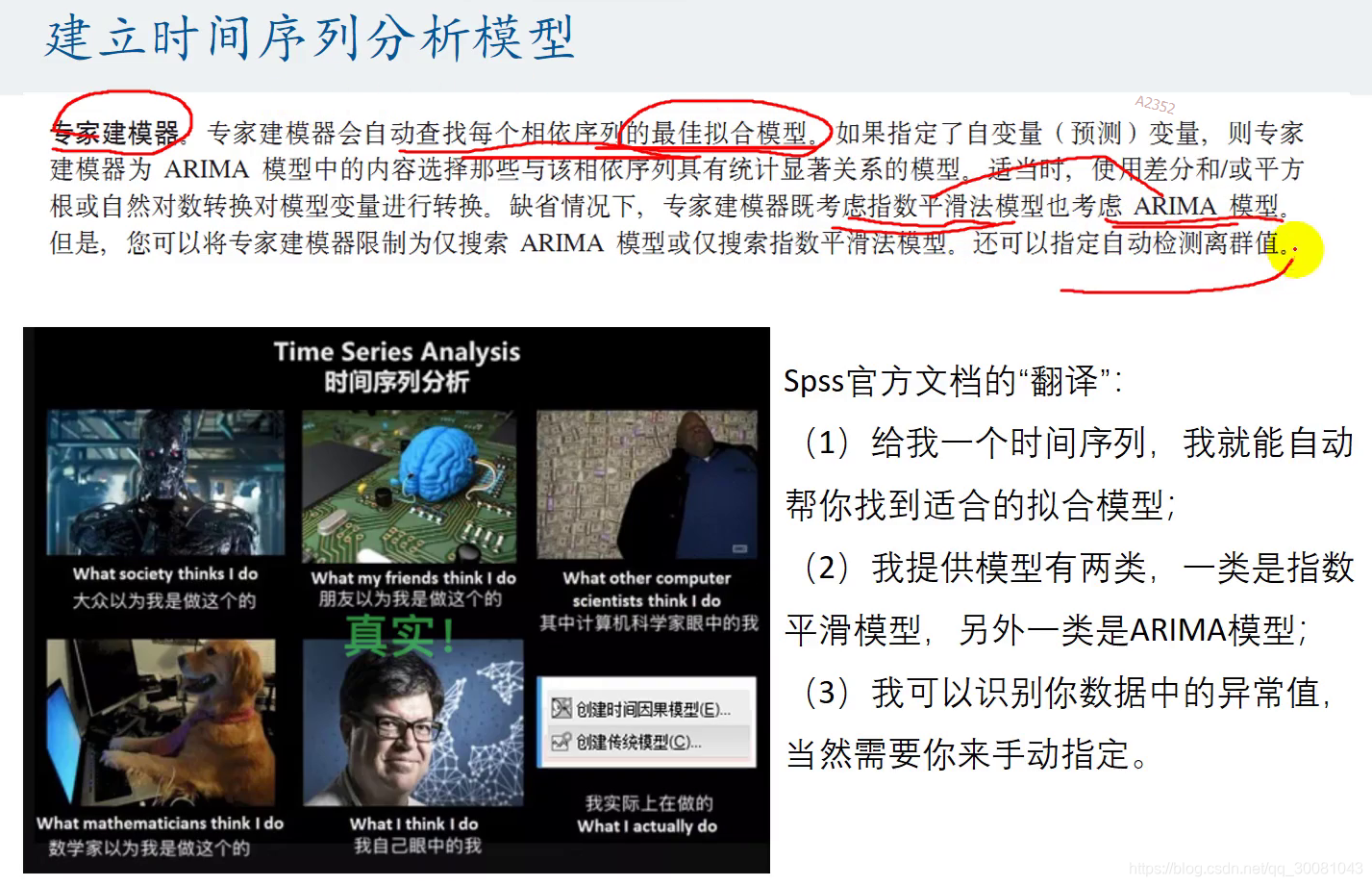
第2部分_SPSS中七种指数平滑方法的简单介绍
simple模型

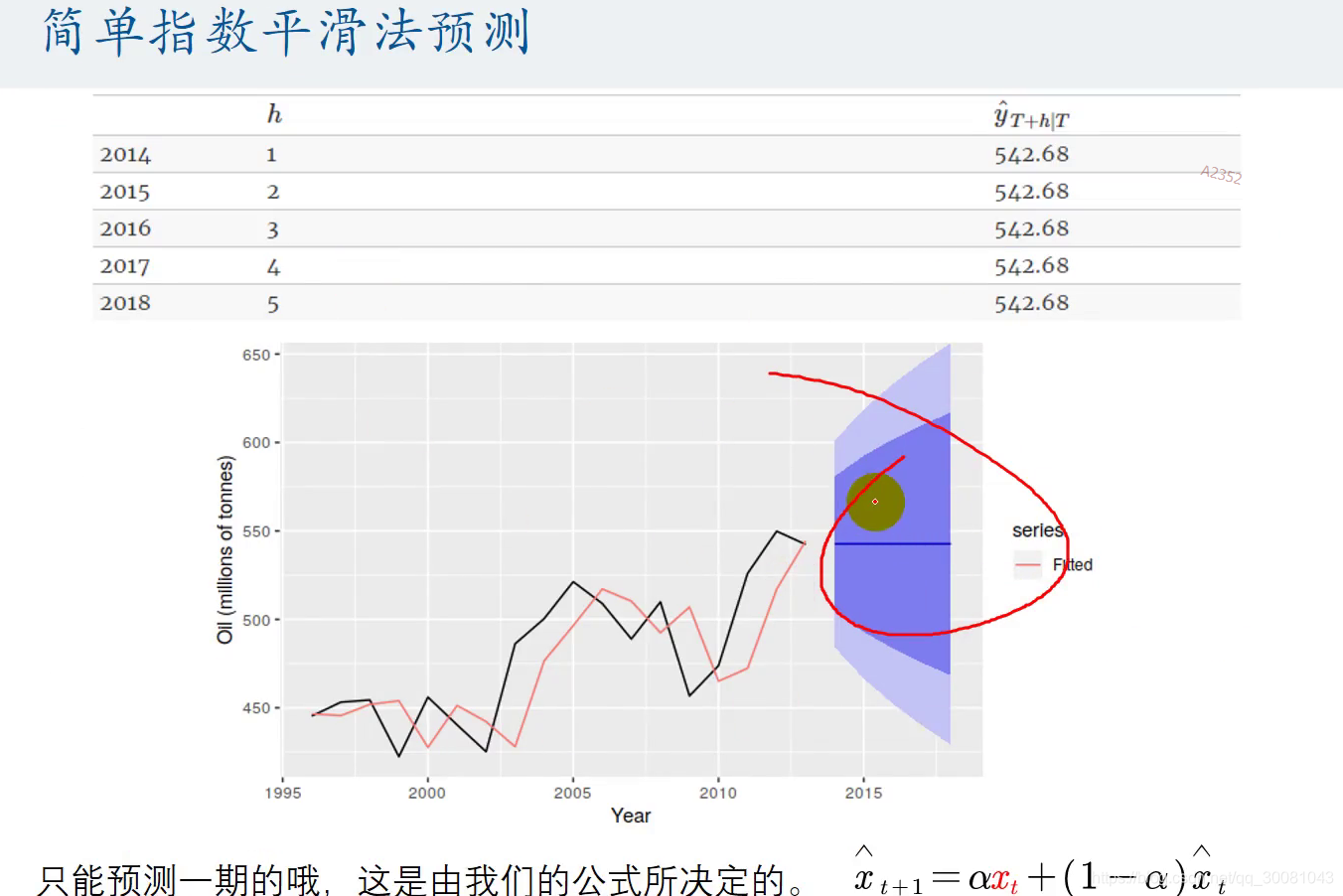
预测的系数都是相同的,这是因为我们公式所决定的。
线性趋势模型

如果选择了线性趋势模型,spss就会给我们一个α和β
不含季节成分
布朗是霍特的特例。
阻尼趋势模型

线性趋势减弱,不含季节。
φ影响着曲线,如果φ等于1,那么阻尼就 是霍特。
如果最后spss给的是阻尼趋势模型,那么就将这三个公式和3个参数放在论文中,然后再进行解释即可
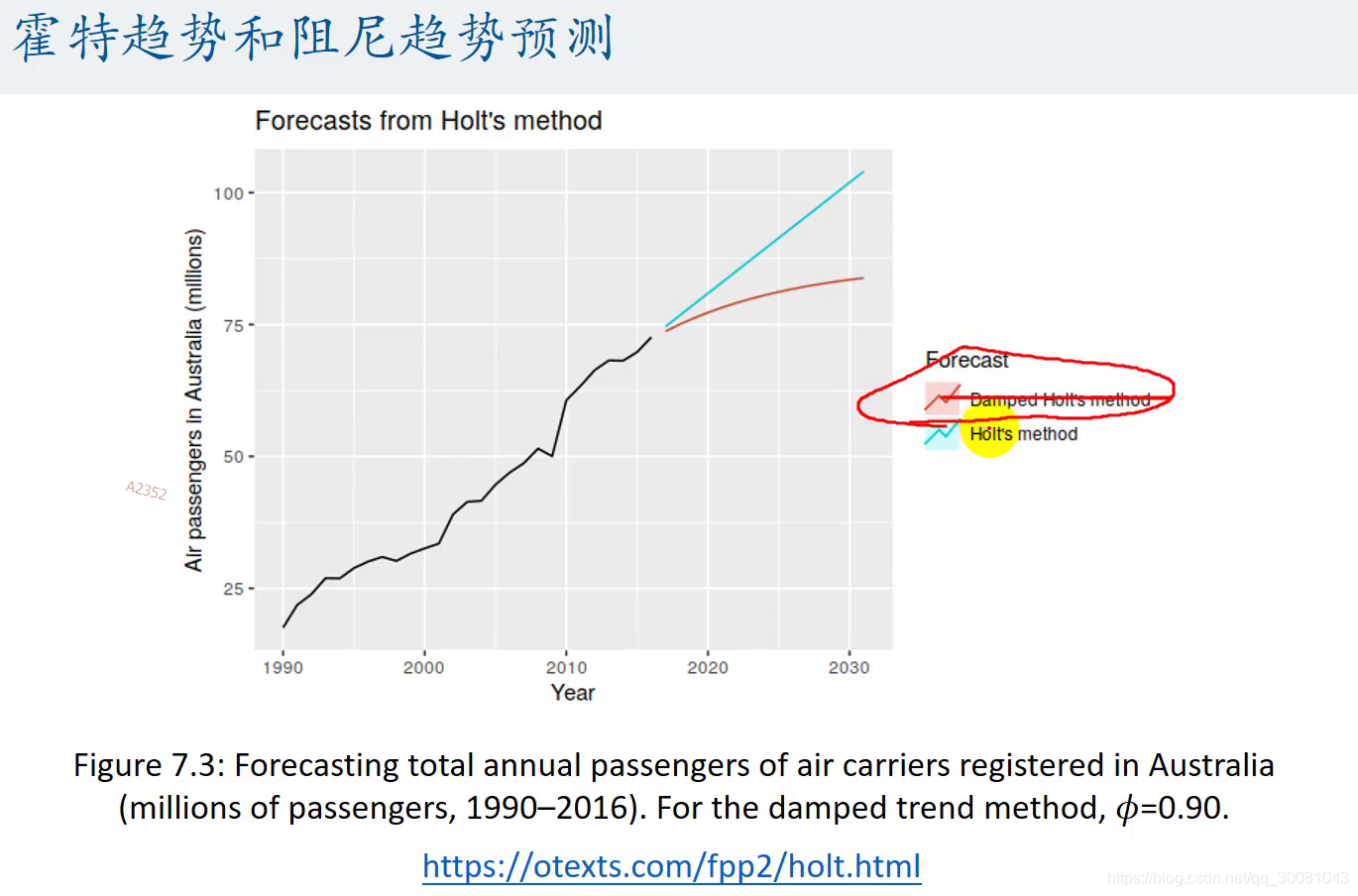
阻尼是在霍特的基础上引入了阻尼效应,使曲线更平缓。
简单季节性

不含趋势,有稳定季节成分。
原来的趋势平滑方程,变成了,季节平滑方程。
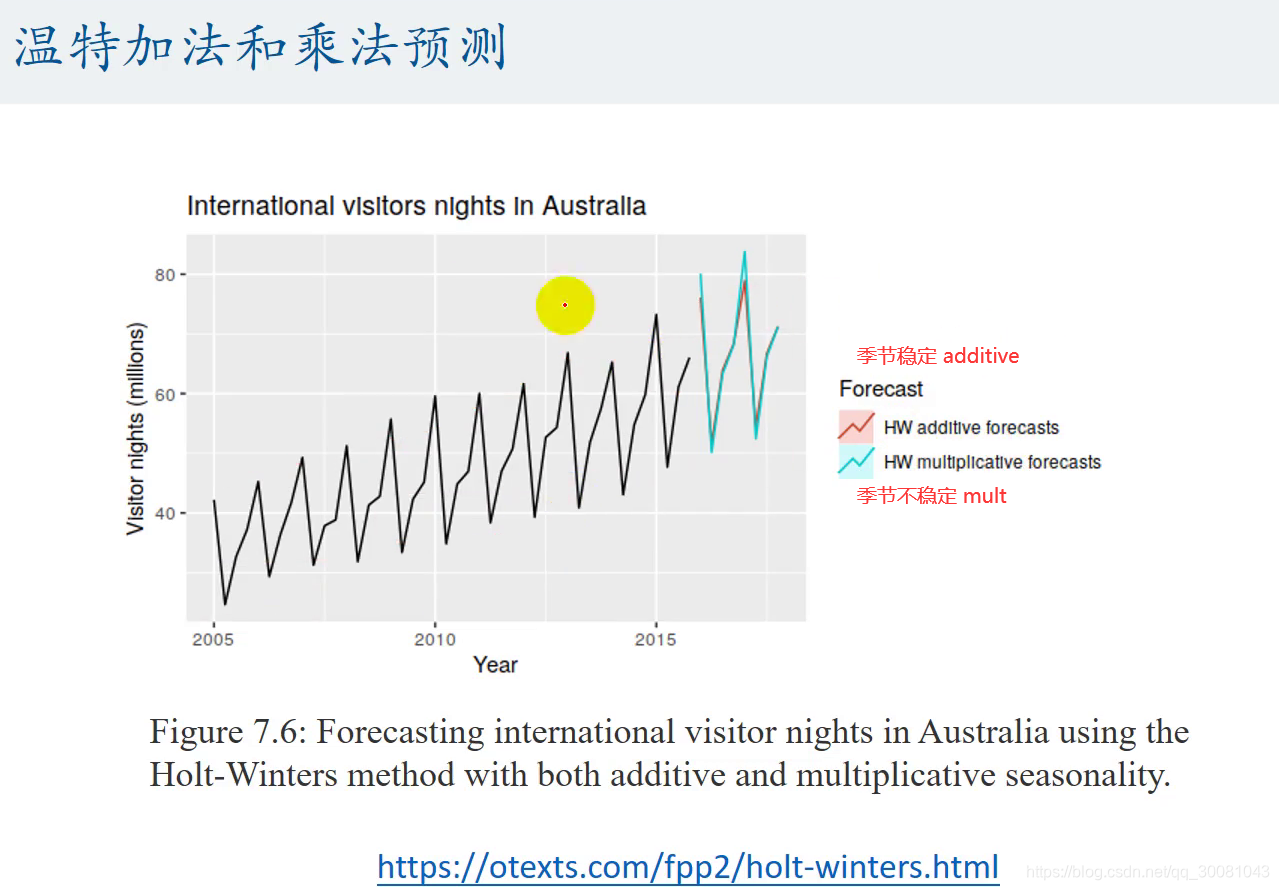
温特加法模型

线性趋势+稳定季节成分
温特乘法模型

线性趋势+不稳定季节成分
第3部分_与ARIMA模型相关的十大知识点(了解即可)
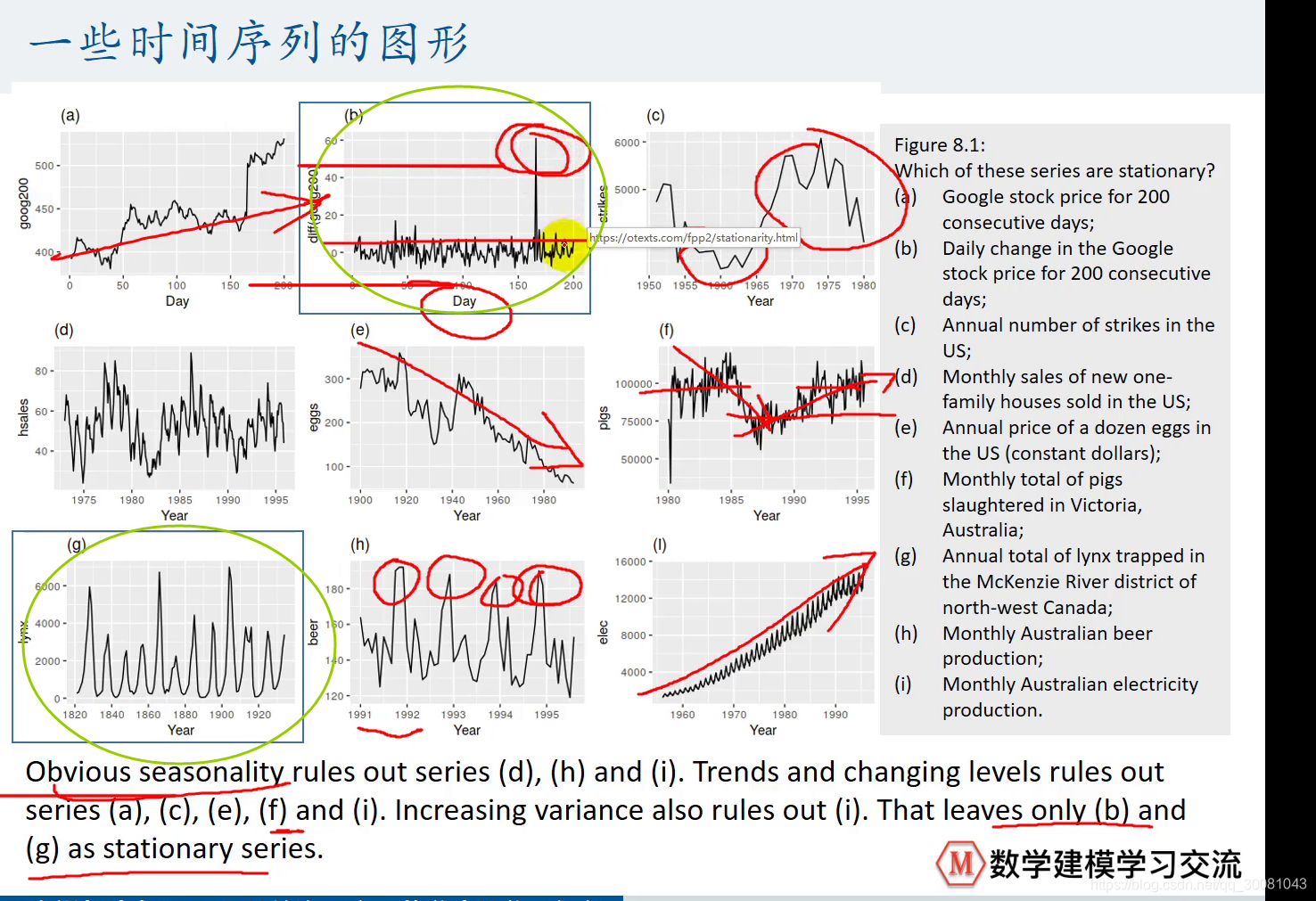
平稳时间序列

协方差平稳。

白噪声序列

扰动项一般都被假设为白噪声序列。
差分方程

红色字体的就是它的齐次部分

滞后算子

- 常数滞后,还是它本身
- 满足乘法分配
- 多次滞后
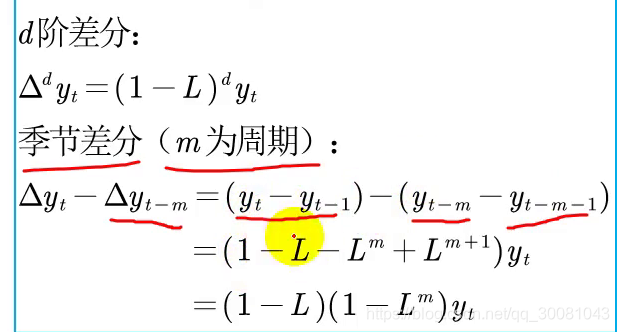
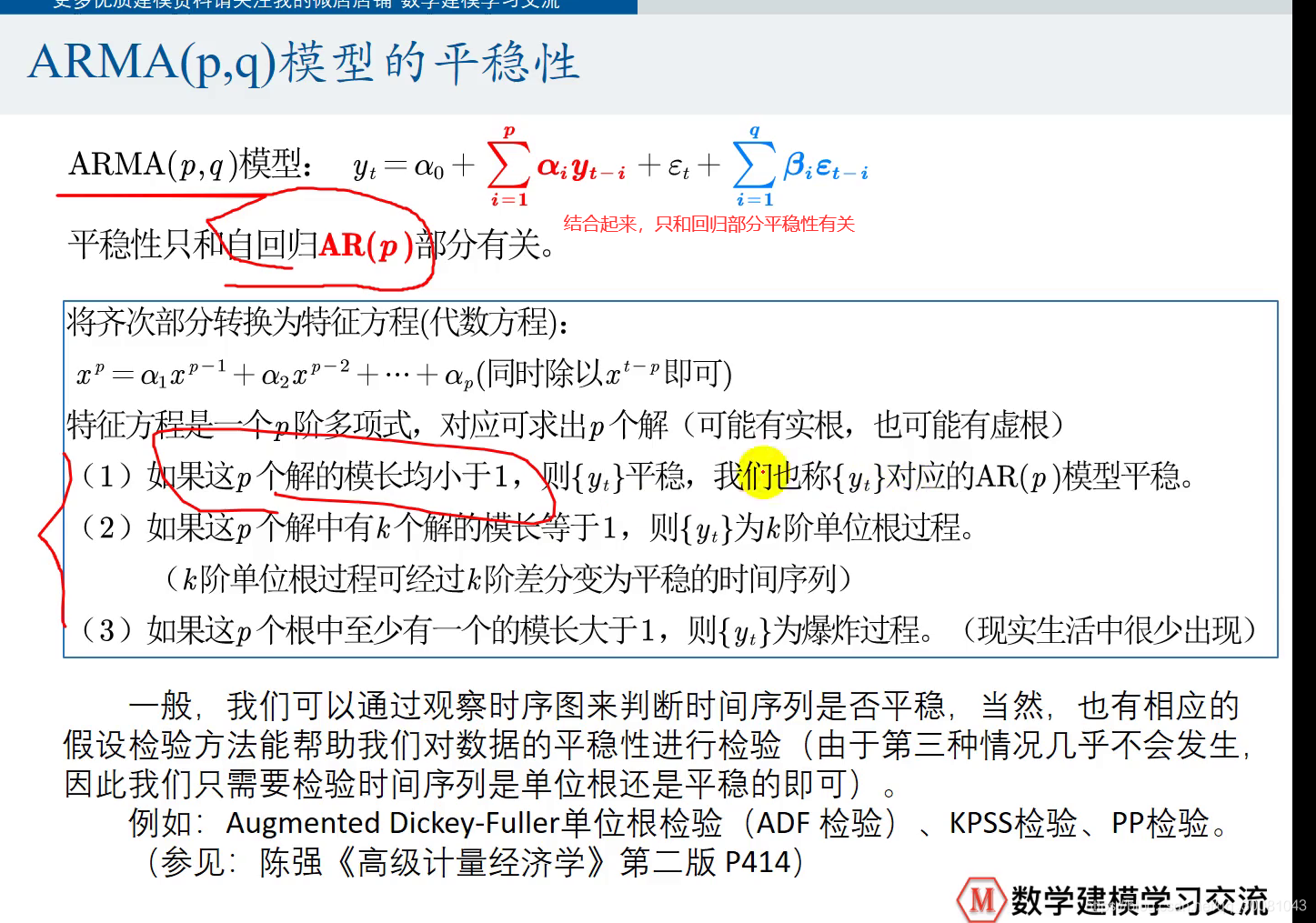
AR(p)模型
一定是平稳的,如果不平稳,要先转换为平稳的。
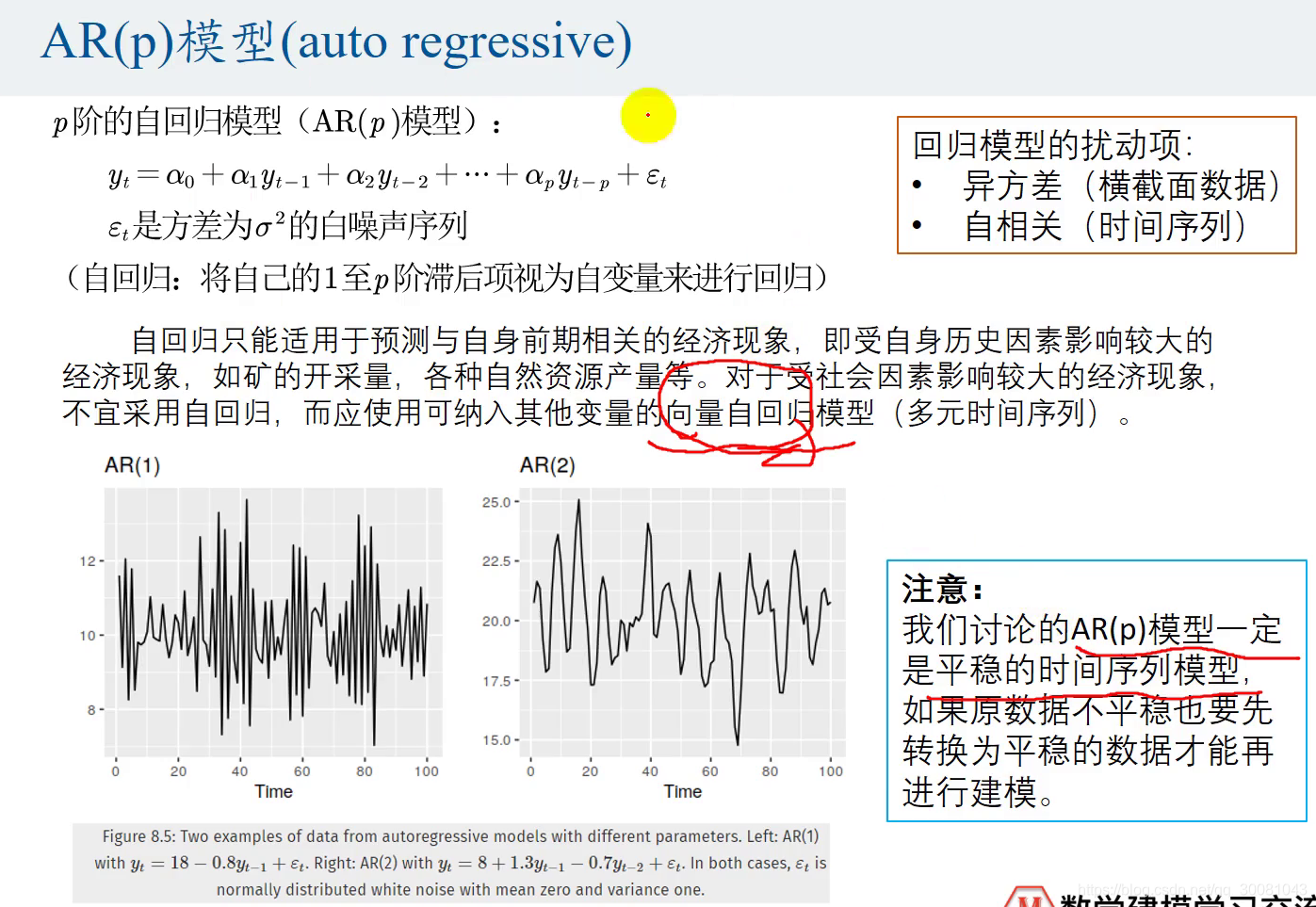
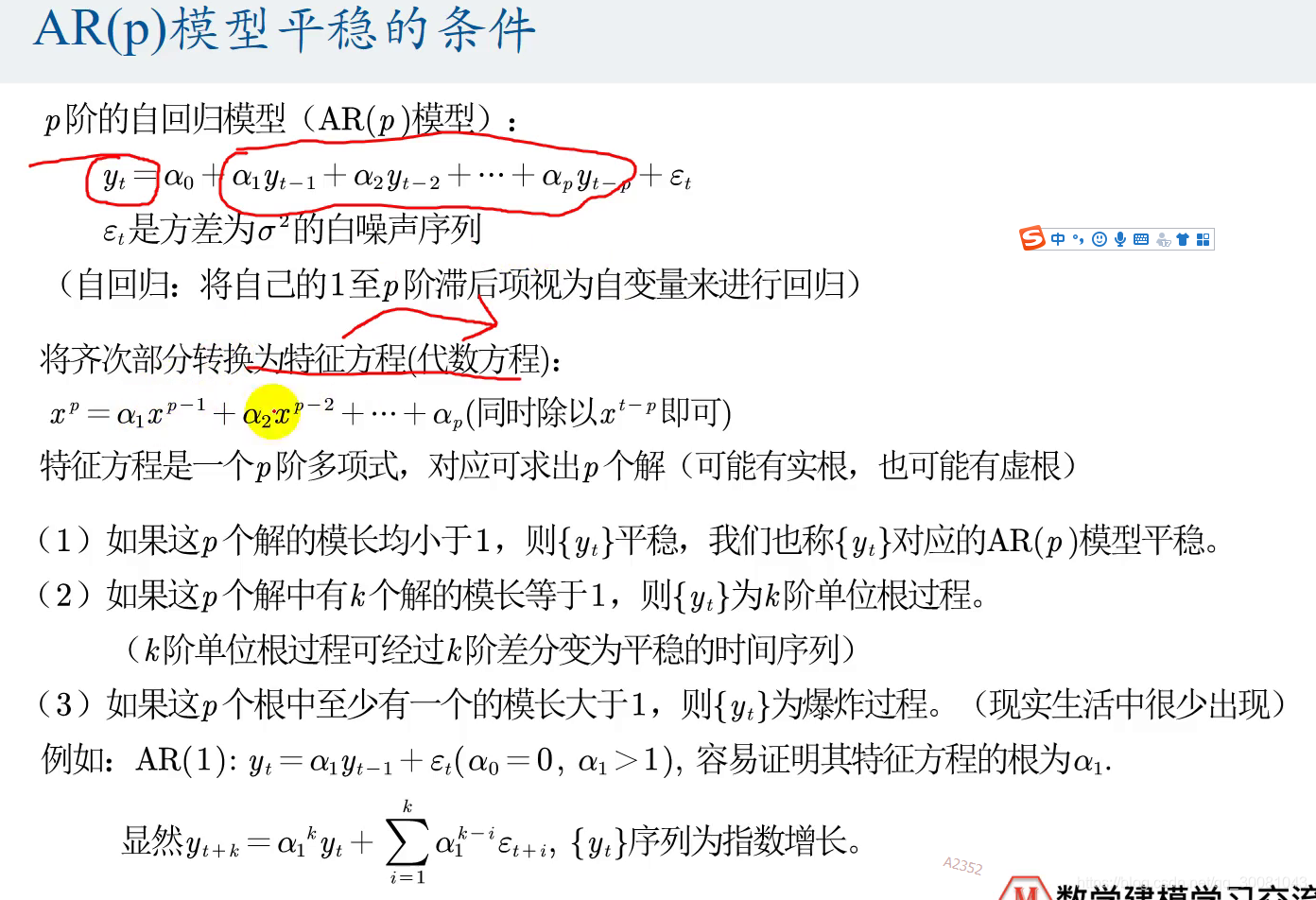
齐次部分转换为特征方程(即p阶多项式),对应可求出p个解。可能有实根,也可能有虚根。
经过k阶的差分可以让它变成平稳的时间序列 。

1,2 常见,3 的情况很少。
AR(p)模型 例子

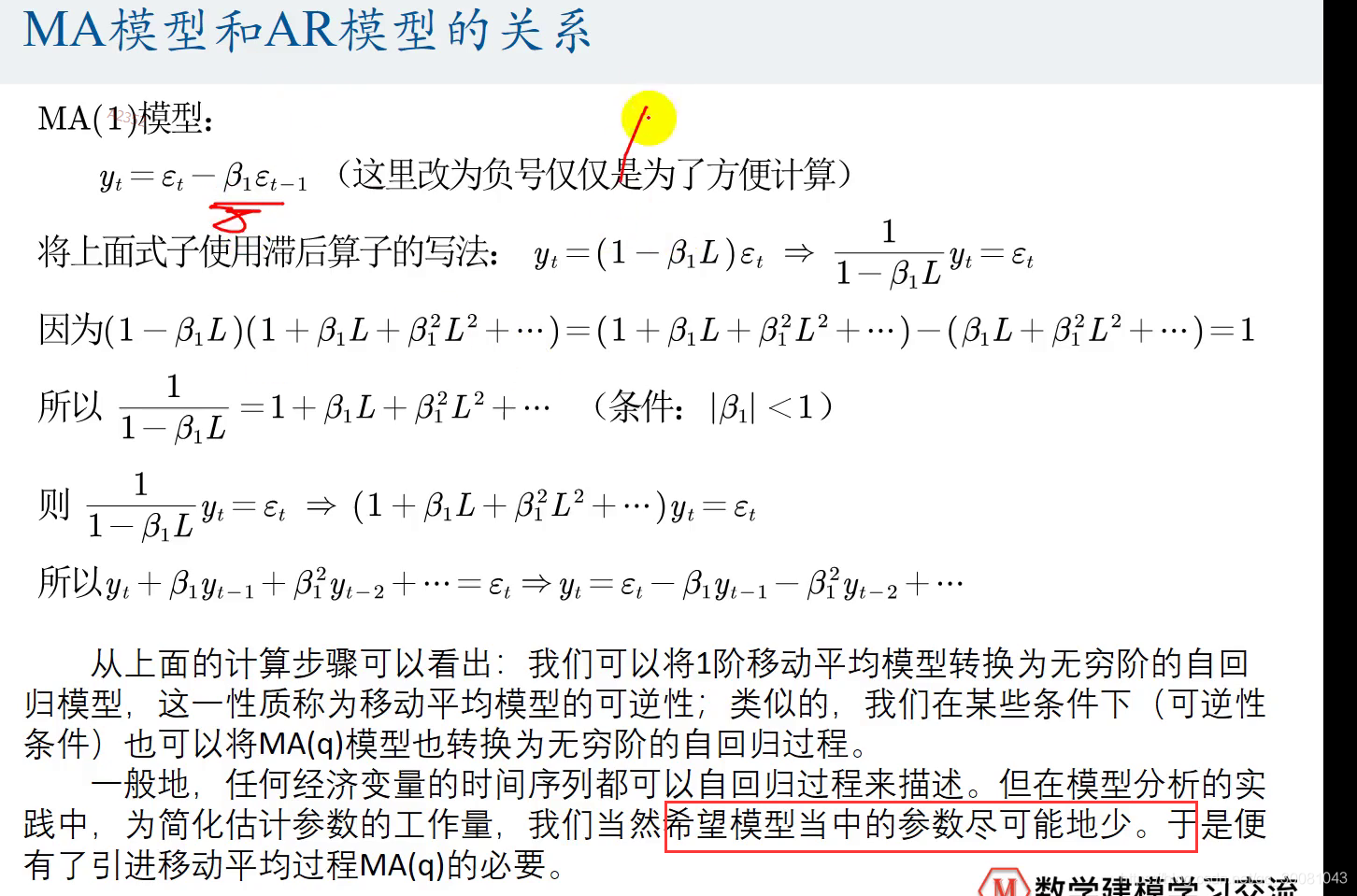
MA( q) 模型


平稳性要求,方差存在且有界。
q是常数,一定平稳
MA模型和AR模型的关系
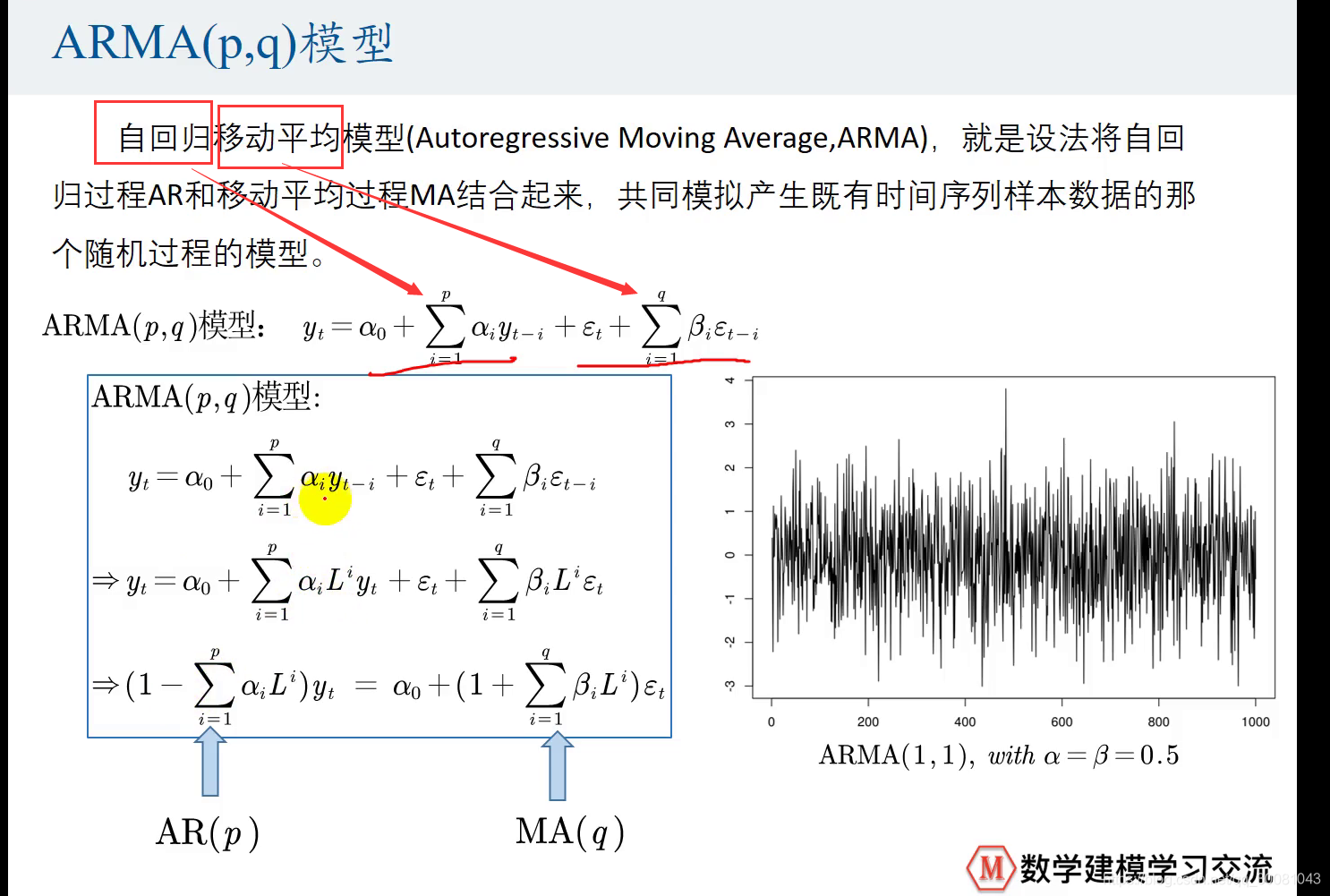
ARMA(p,q)模型 --自回归移动平均模型
自相关系数ACF

偏自相关函数 PACF
前提是平稳
pdf 49-52
ARMA模型的识别
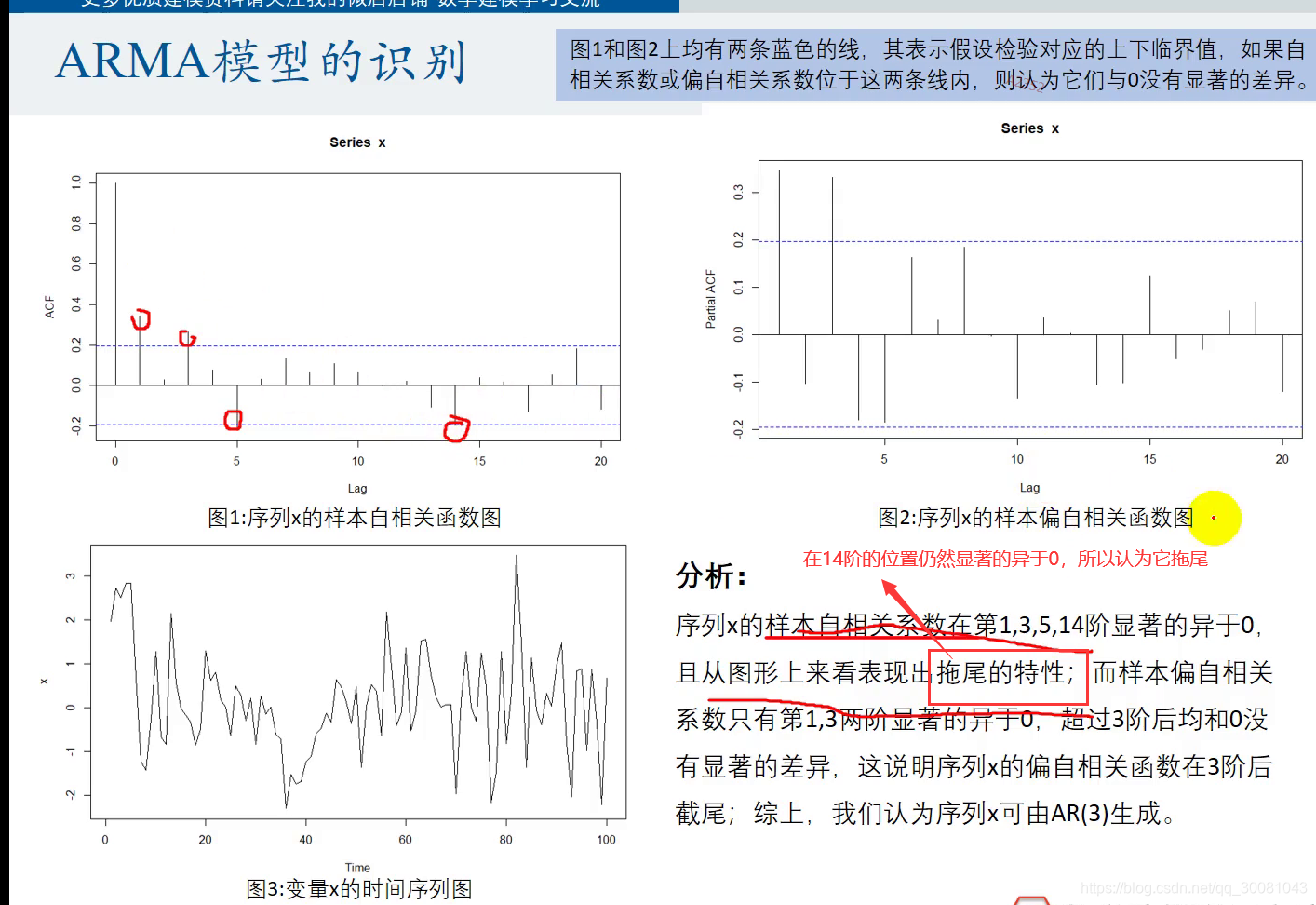
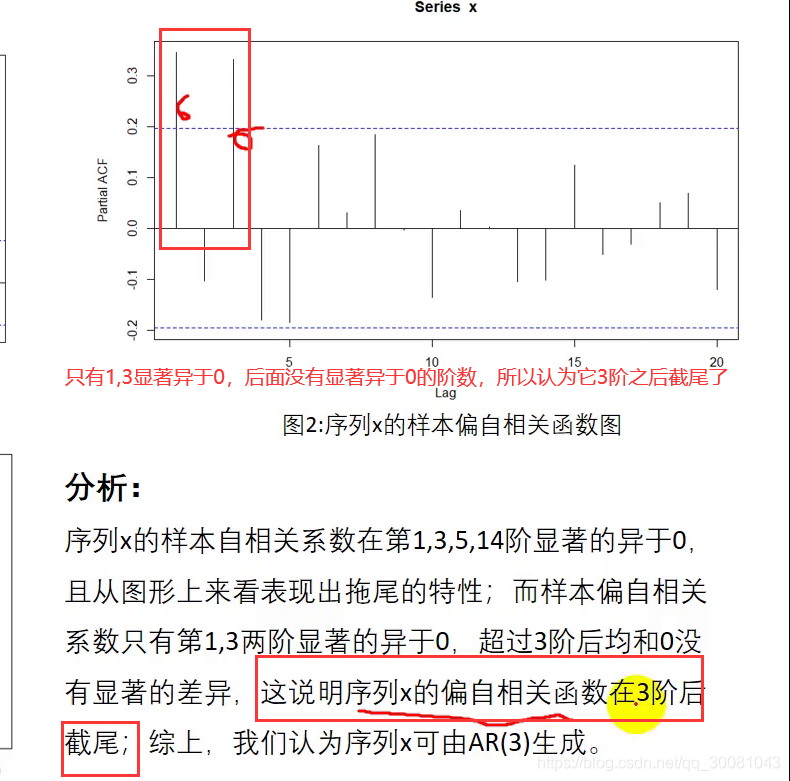
AIC和BIC准则 (选小原则)

BIC 选择的模型更加简洁。
检验模型是否识别完全 q检验


APIMA(p,d,q) 差分自回归移动平均模型

SAPIMA – 季节性的APIMA模型

第4部分_实例1销量数据预测和实例2人口数据预测
SPSS时间序列建模的思路

1.查看数据是否缺失,如果在开头或者结果可以直接删除。如果出现在中间,使用SPSS填充。
生成时间变量,并画出时间序列图。(参考标题 :SPSS软件定义时间变量)

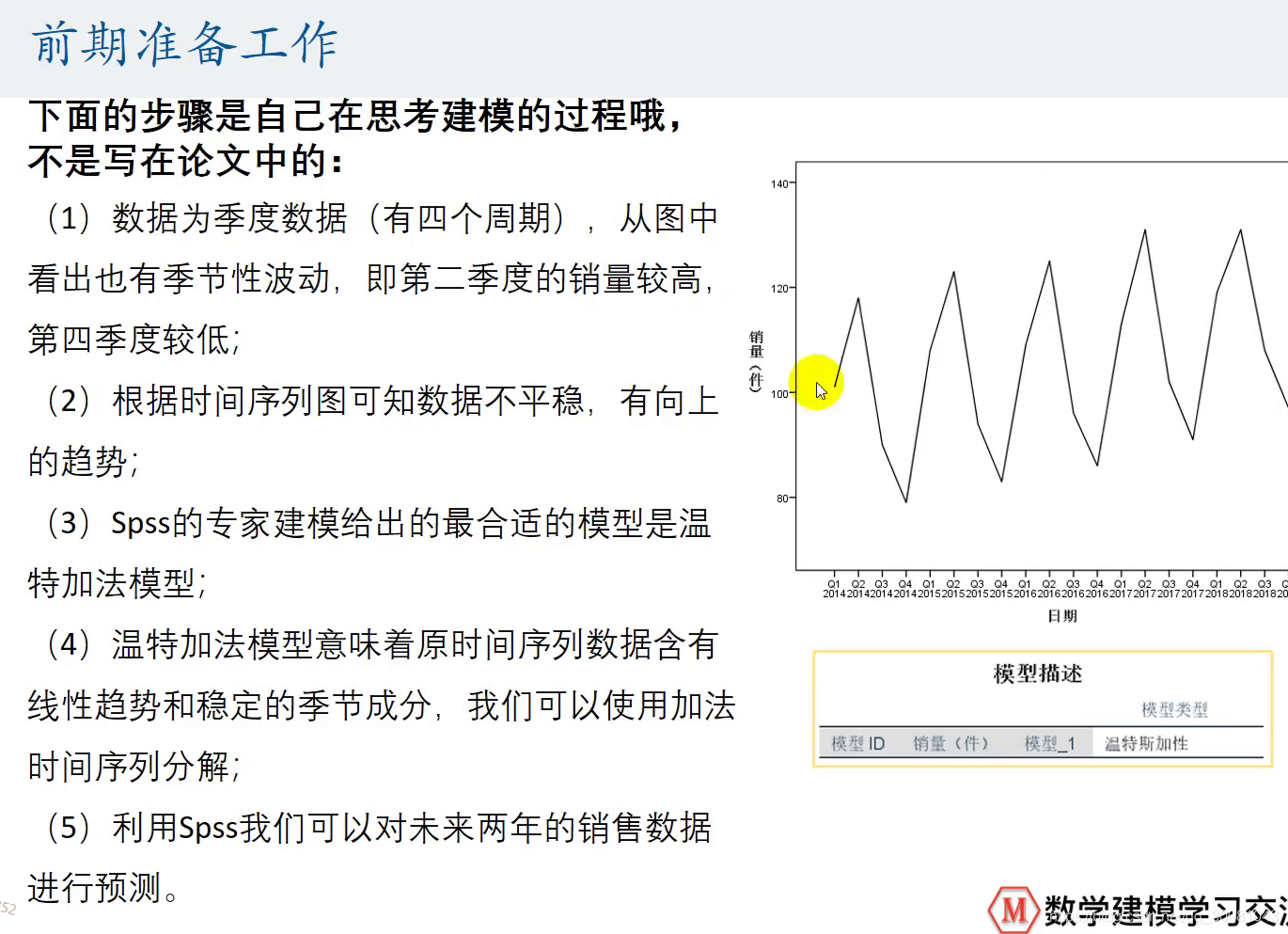
2.肉眼看数据是什么样的结构,就是看时间周期。看是不是季度或者月份数据(至少2个完整的)。
如果是的话,则看一下这个时间序列有没有季节性波动,如果有的话,可以对时间序列进行分解,(加法或乘法分解),用什么取决于这个图啥样。(有累加趋势的,应该用加法)

3.看这个时间序列图是不是平稳的序列。比如ARMA模型是建立在平稳的基础之上的。
如果在明显上升或下降趋势,就用ARIMA
如果数据围绕均值上下波动,没有趋势和季节性,就可以认为它是平稳的



ARIMA(p,1,q) 先进行一阶差分,然后平稳了,才能用ACF和PACF图形分析。
如果得到的结果与季节相关,可以考虑使用时间序列分解。
变量部分:
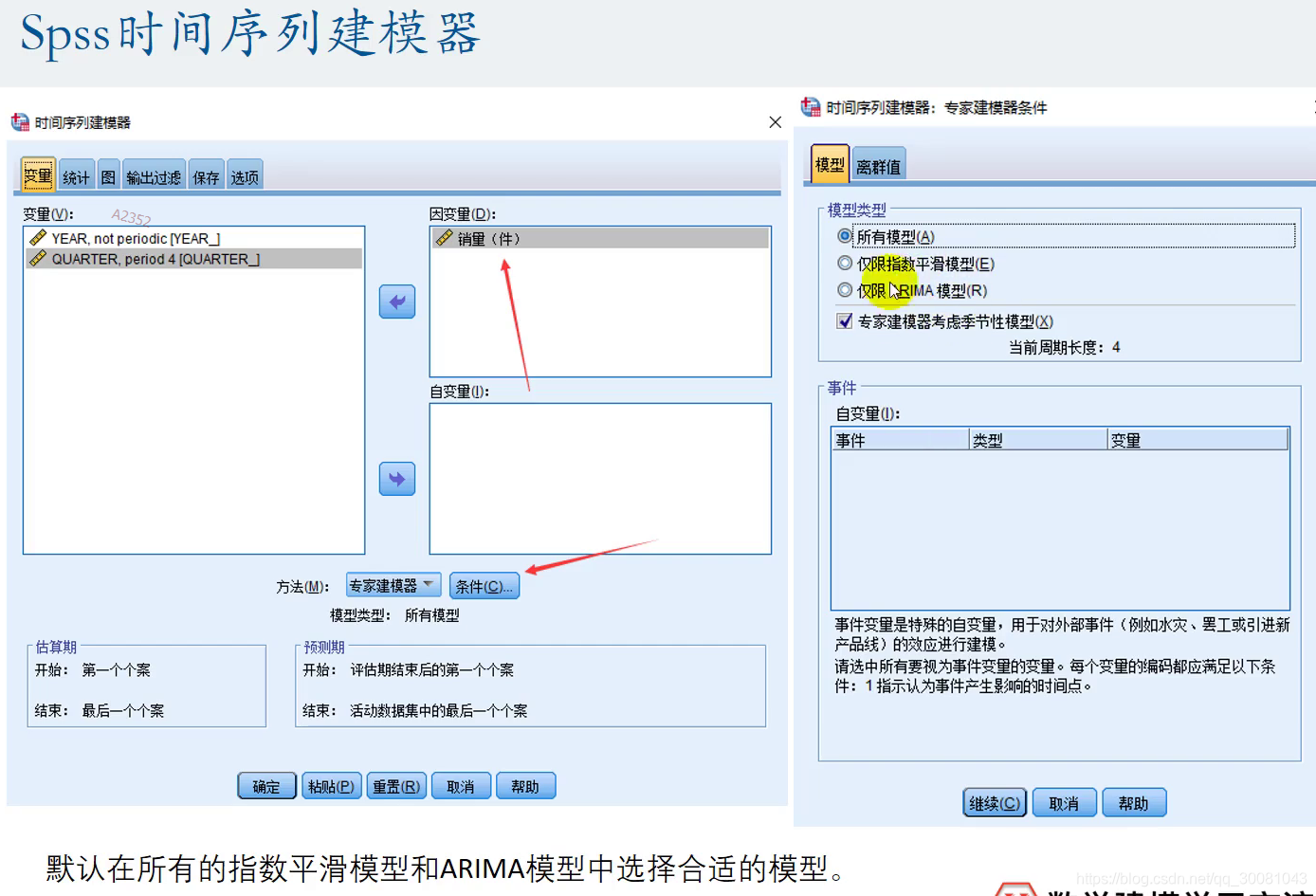
统计、图:
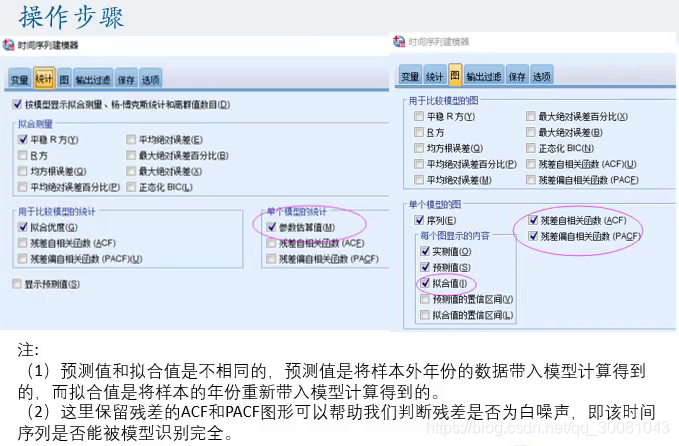
如果需要预测,则多勾选预测值的置信区间和拟合值的置信区间(但是可能最后的图会很糟糕。)
保留残差的ACF和PACF 判断残差是否为白噪声
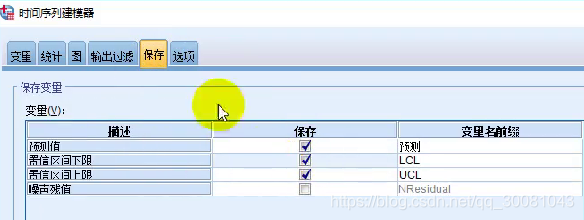
保存:
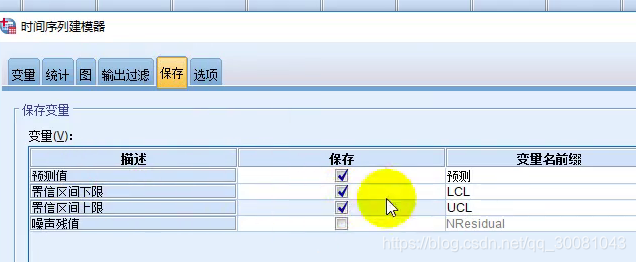
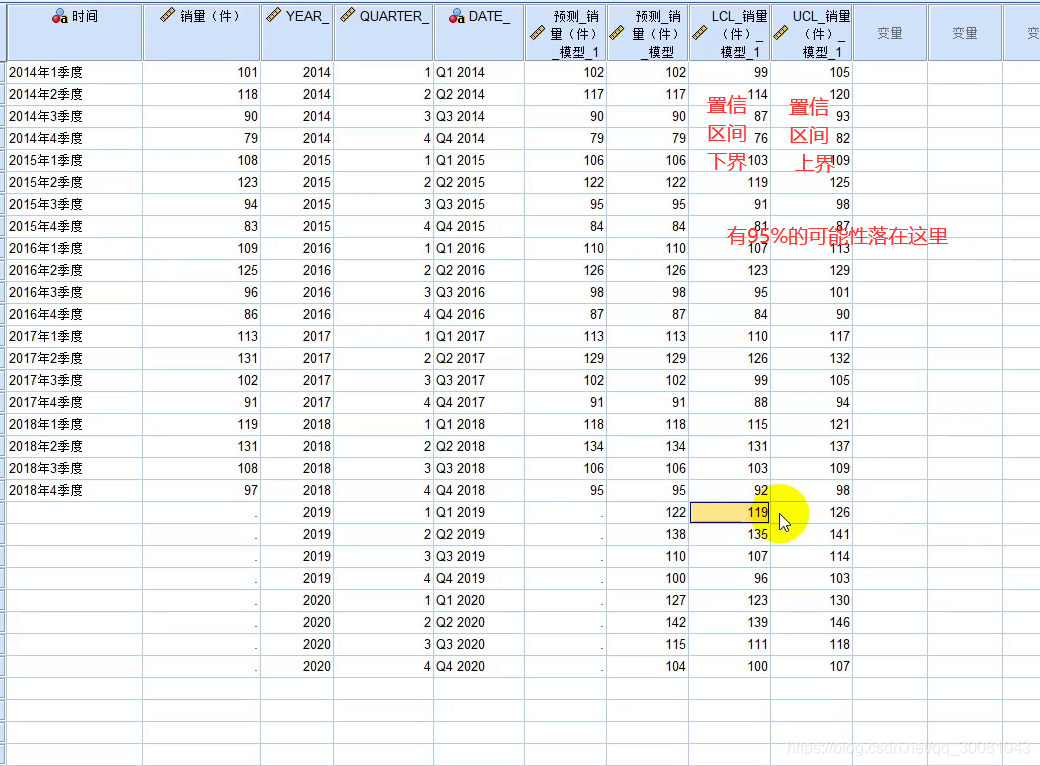
如果需要预测,则多勾选上下限
选项:
指定预测到哪一年哪一季度
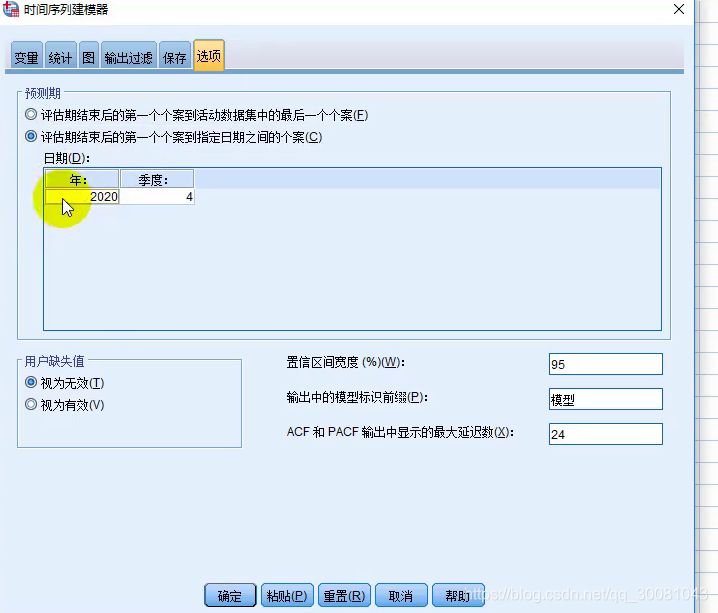
常用的评价指标
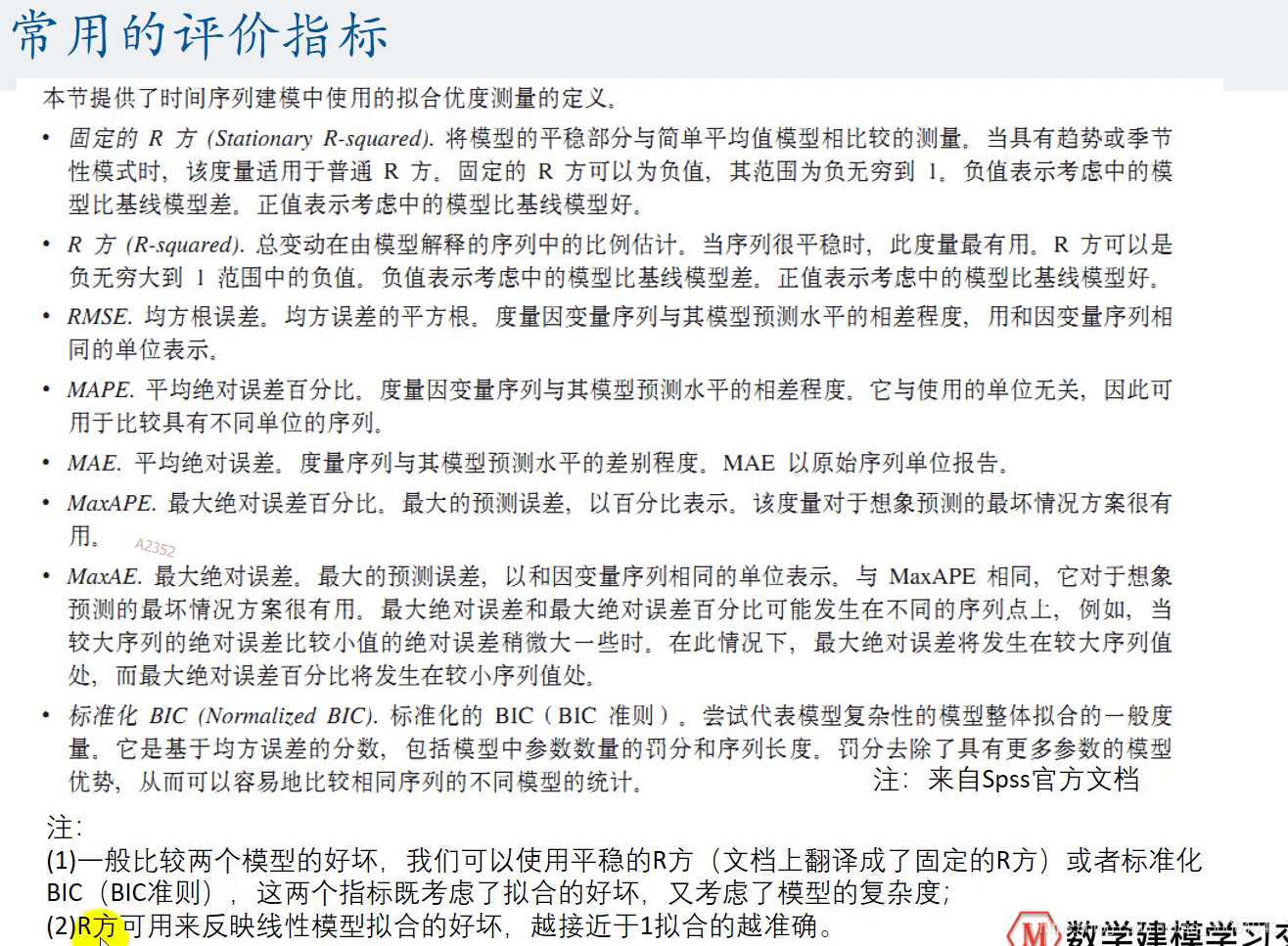
SPSS结果
SPSS选择了温特斯加性

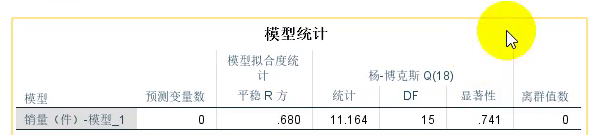
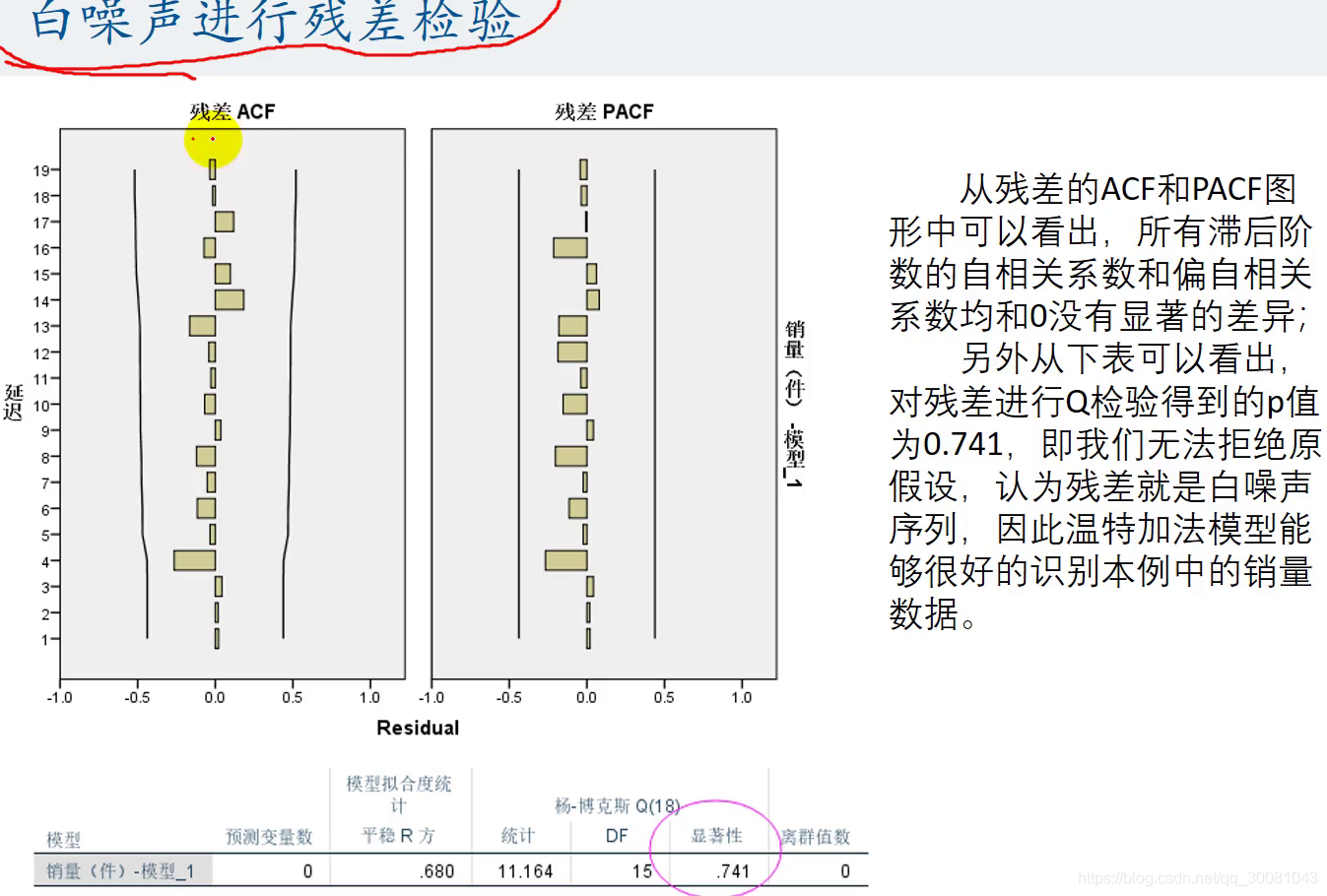
Q检验:
显著性就是我们的P值,大于0.05 ,则不能拒绝原假设,则残差是白噪声,是白噪声则认为我们这个模型能完全识别出我们的时间序列。
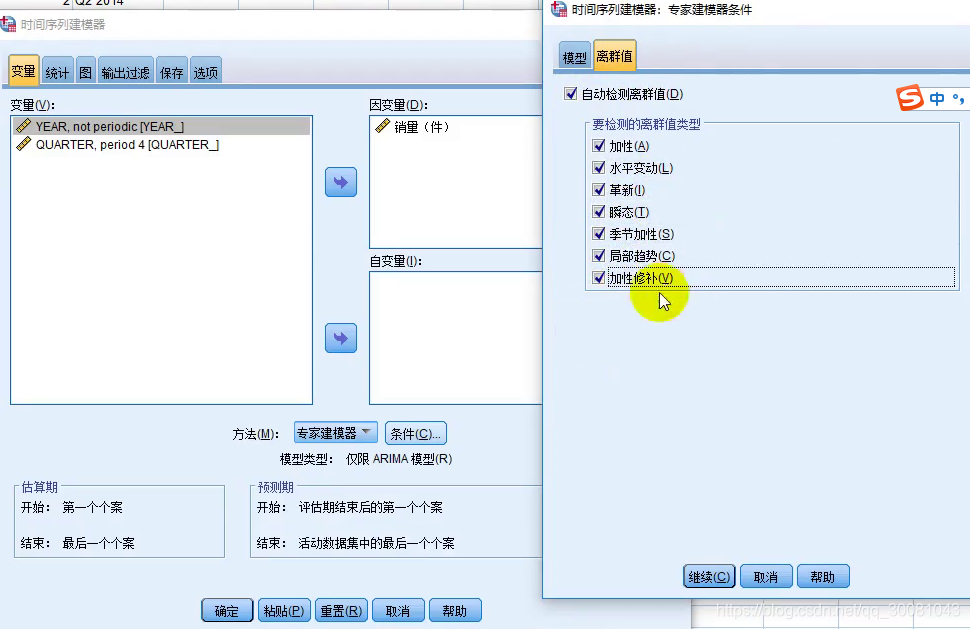
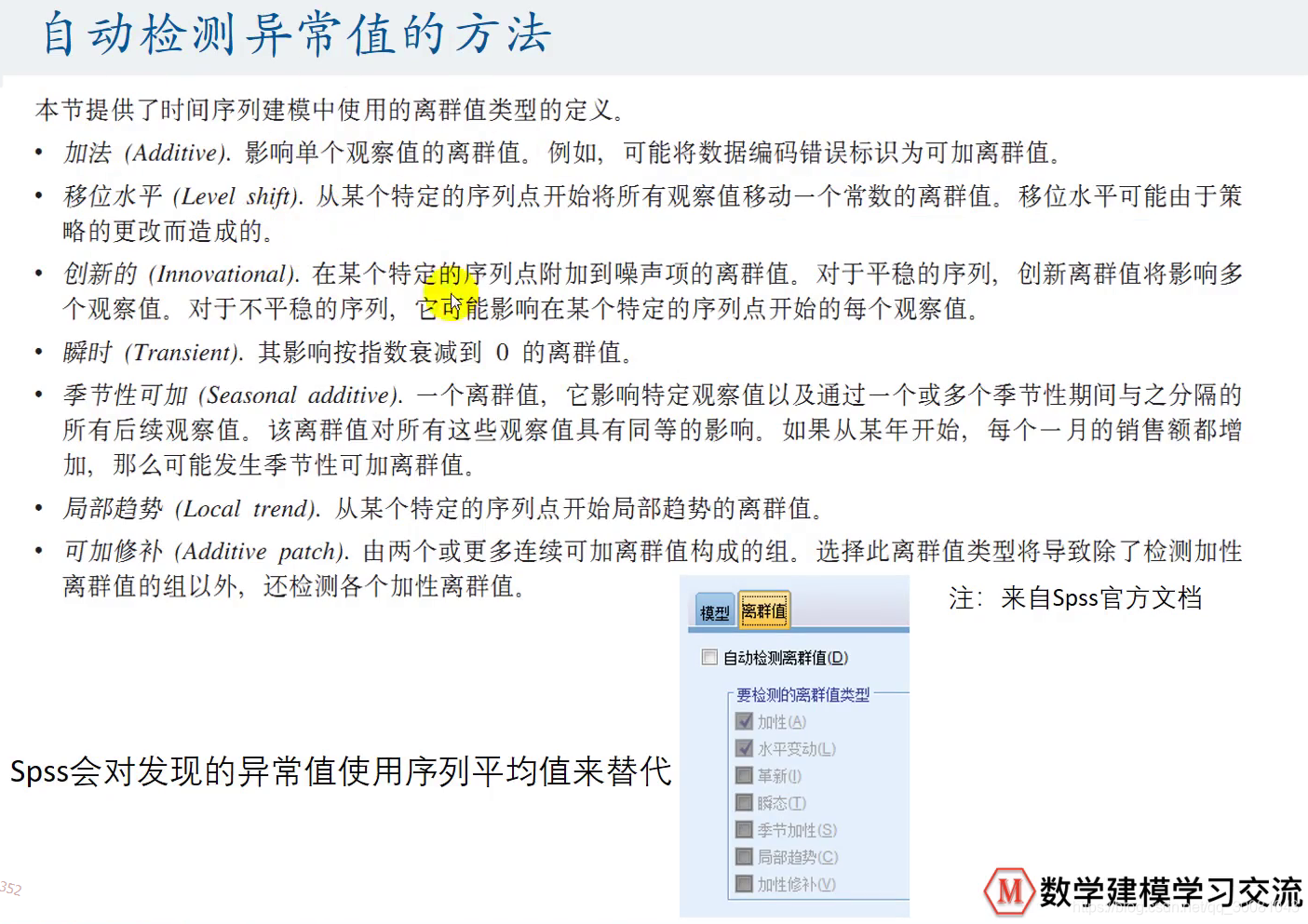
离群值数为0,则我们没有离群值
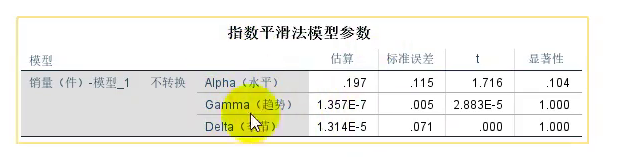
我们勾选的,对于系数的估计值
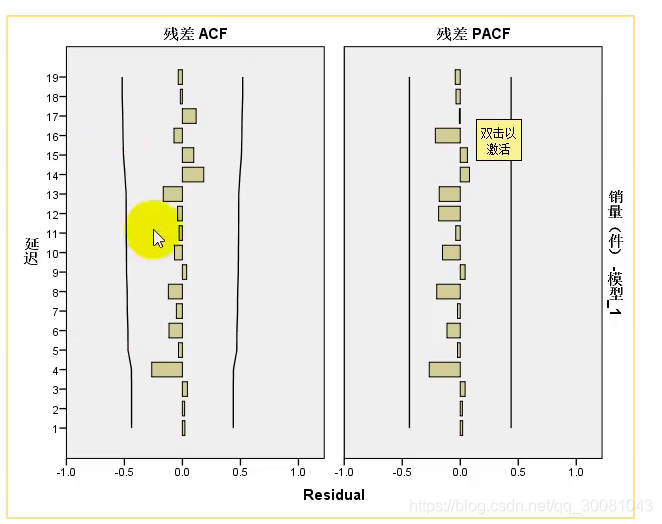
所有的ACF和PACP都在两条线之内,则认为它和0没有显著差异,认为我们的模型能完全识别时间序列(与q检验的结论一致。)
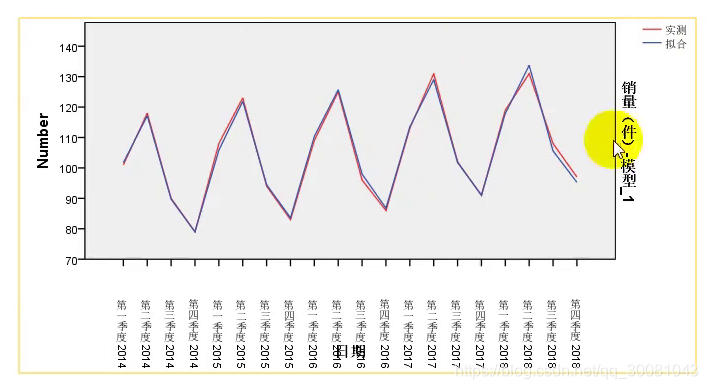
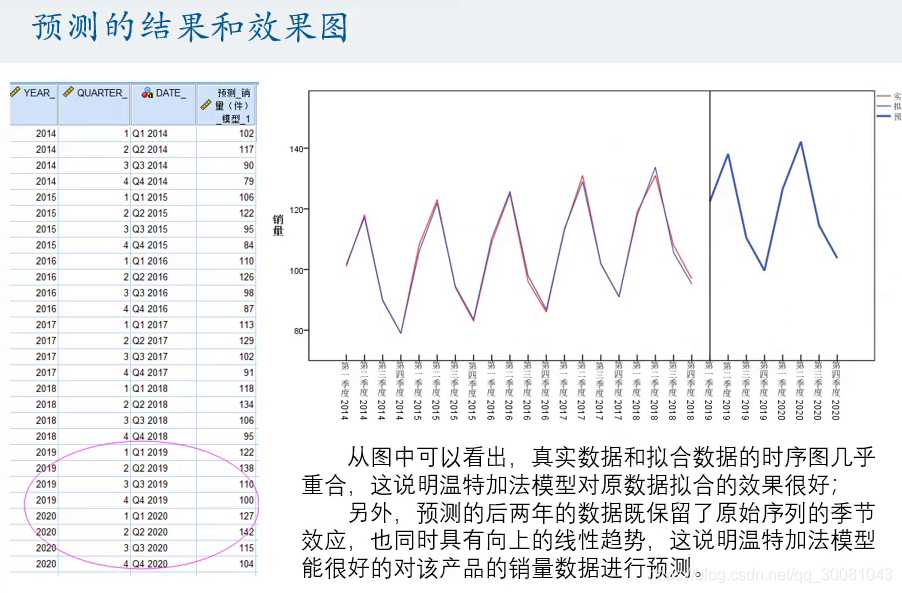
通过观察,拟合的效果较好。
SPSS温特加法模型 -论文写法

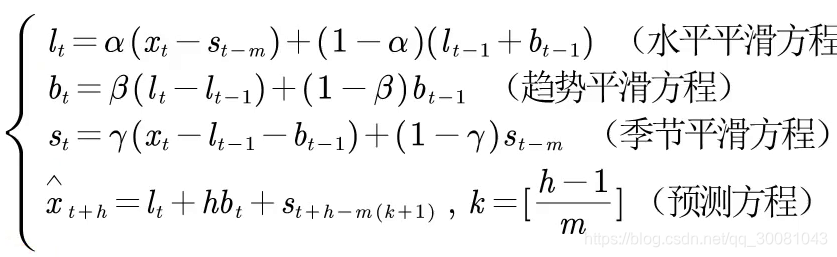

1.把4个式子搬上去,再解释4个变量是什么意思?
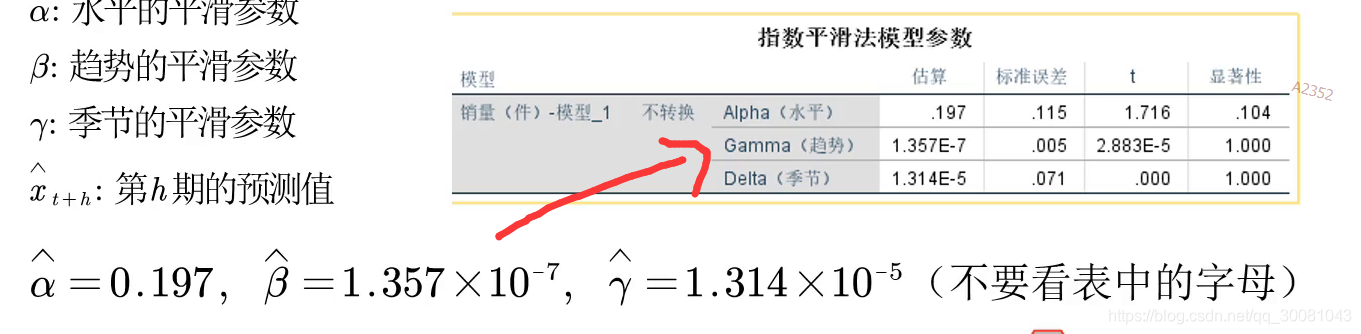
2.再把SPSS的结果估计的三个参数放上去。

3.再把Q检验的统计量放上去。
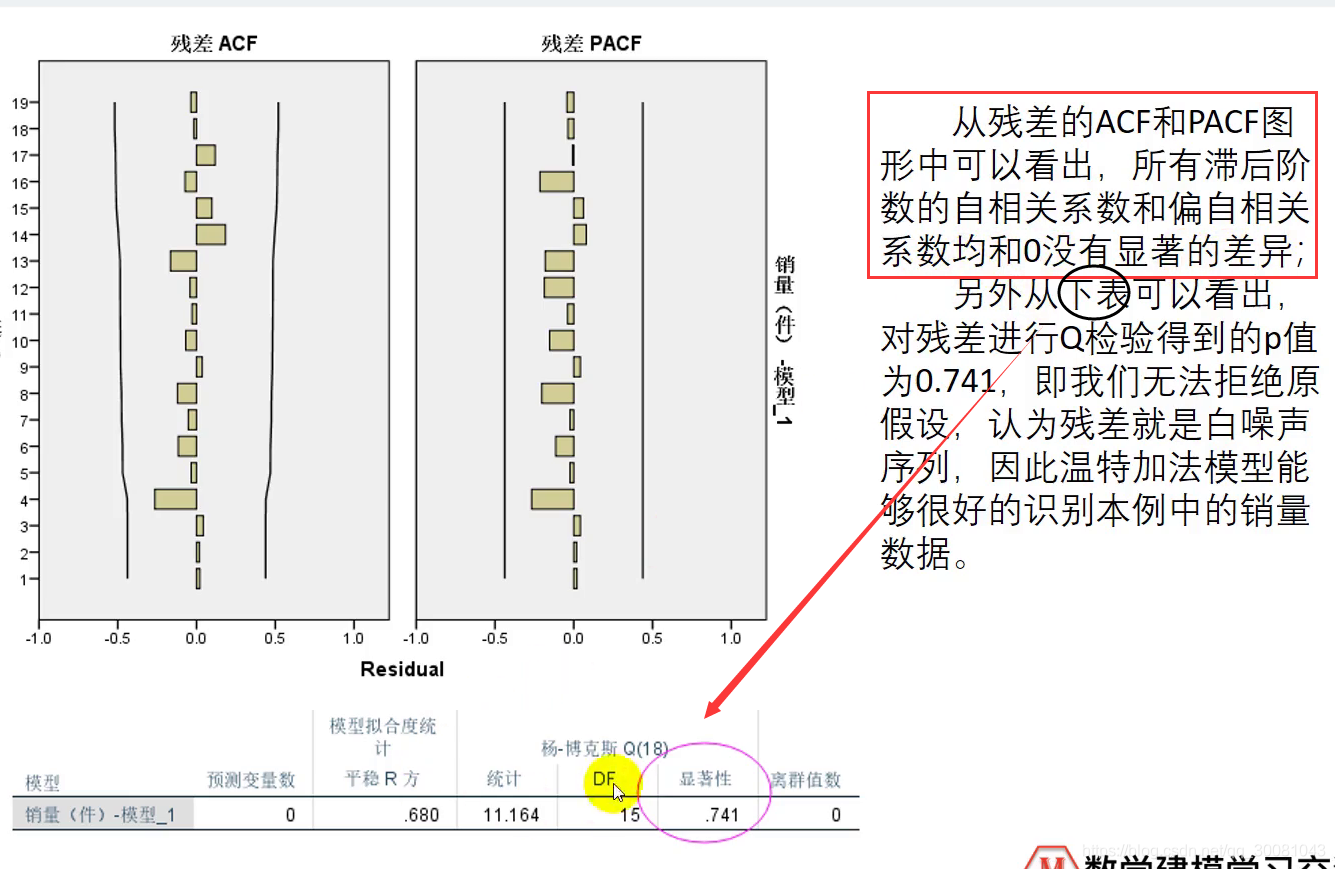
4.再放残差ACF和残差PACF 图形,然后再加上以上几句话。
带预测的时间序列
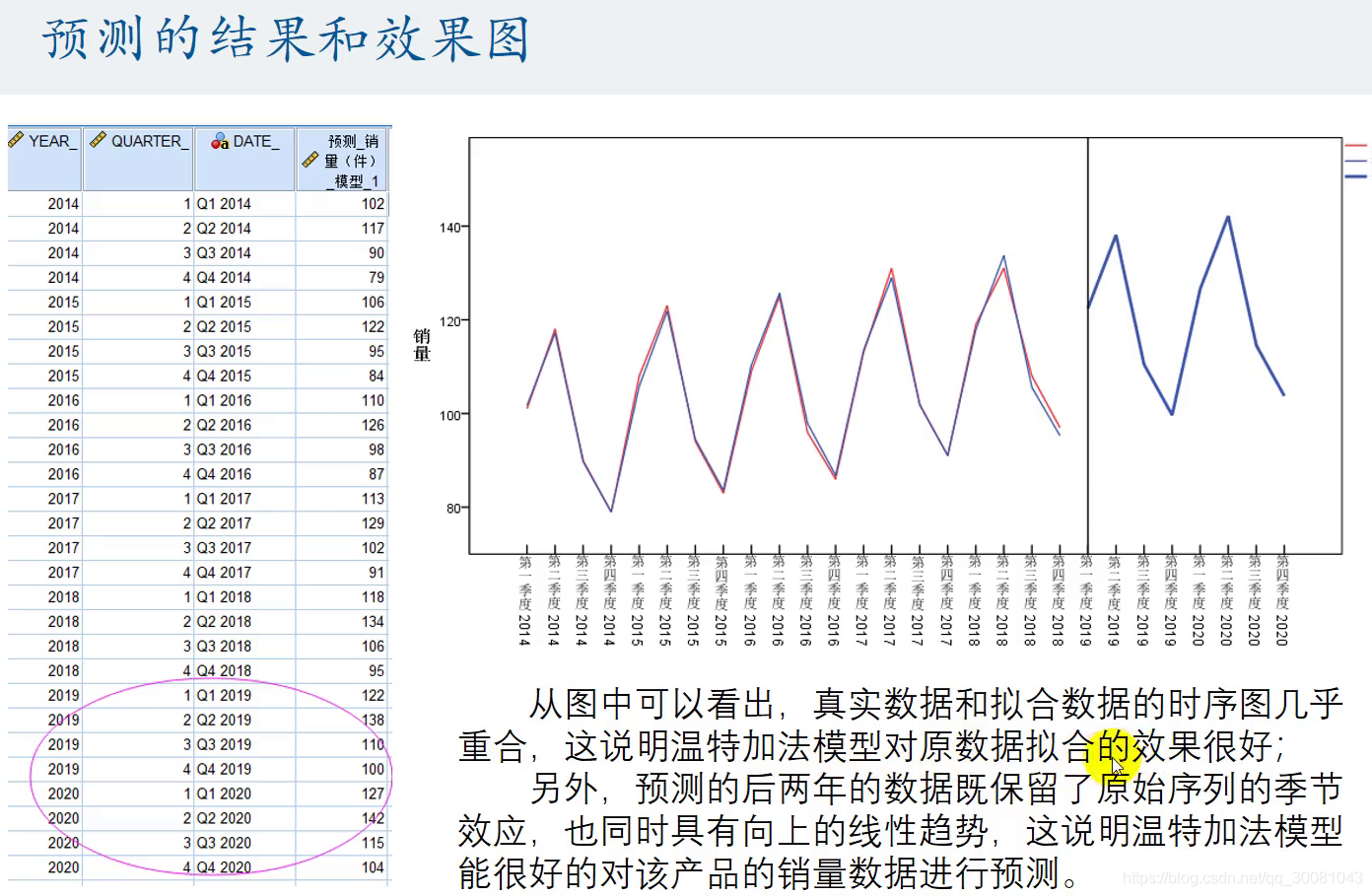
温特加法模型对数据拟合效果很好。既有向上的线性,也有季节效应。
论文
1.由于我们的数据是完整的,不存在缺失值,数据为季度数据,我们可以做出它的时间序列图。
2.然后就做出时间序列图。然后分析一下时间序列图。如:我们的销量数据有明显的上升趋势,而且销量数据有明显的季节波动,那我们就可以考虑时间序列分解。
3.因为它是平稳的,我们就可以使用加法的时间序列分解。然后对结果进行解读(参考 标题 :结果解读)
4.然后我们利用SPSS软件的专家建模器。把专家建模器的工作原理说明一下。 专家建模器会为我们选择一个很合适的模型。SPSS的专家缄默期给出的最合适的模型是 XXX 模型。
5.然后再解释一下 XXX 模型 。如下图的公式和参数说明

6.然后SPSS给我们估计出来的3个参数也可以写在我们的论文中,使用了指数平滑法模型来估计参数。
7.然后我们对白噪声进行残差检验,可以通过图形来判断,也可以通过q检验。把结果的图形和文字放在我们的论文中
8.我们设置了95%的置信水平,在95%的置信水平下,我们得到了如下这些预测值。
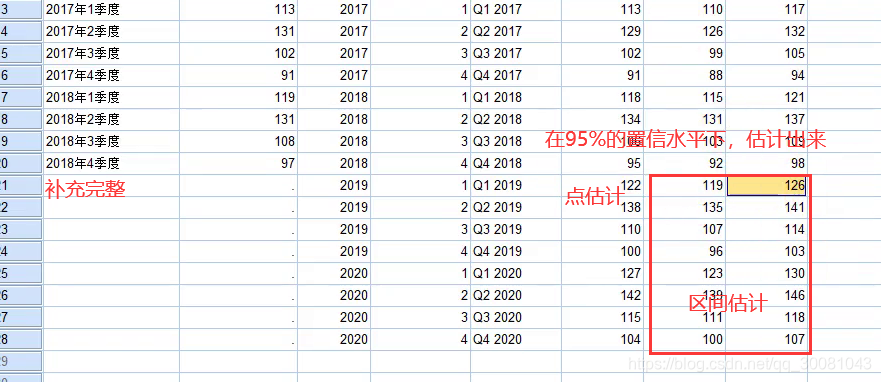
9. 把评价指标平稳的R方放入论文,越接近1说明拟合越好。还有标准化BIC,代表模型复杂性的模型整体拟合的一般度量。
例题2:人口数据预测
用来预测的话,拟合用得比较多,插值基本不用。
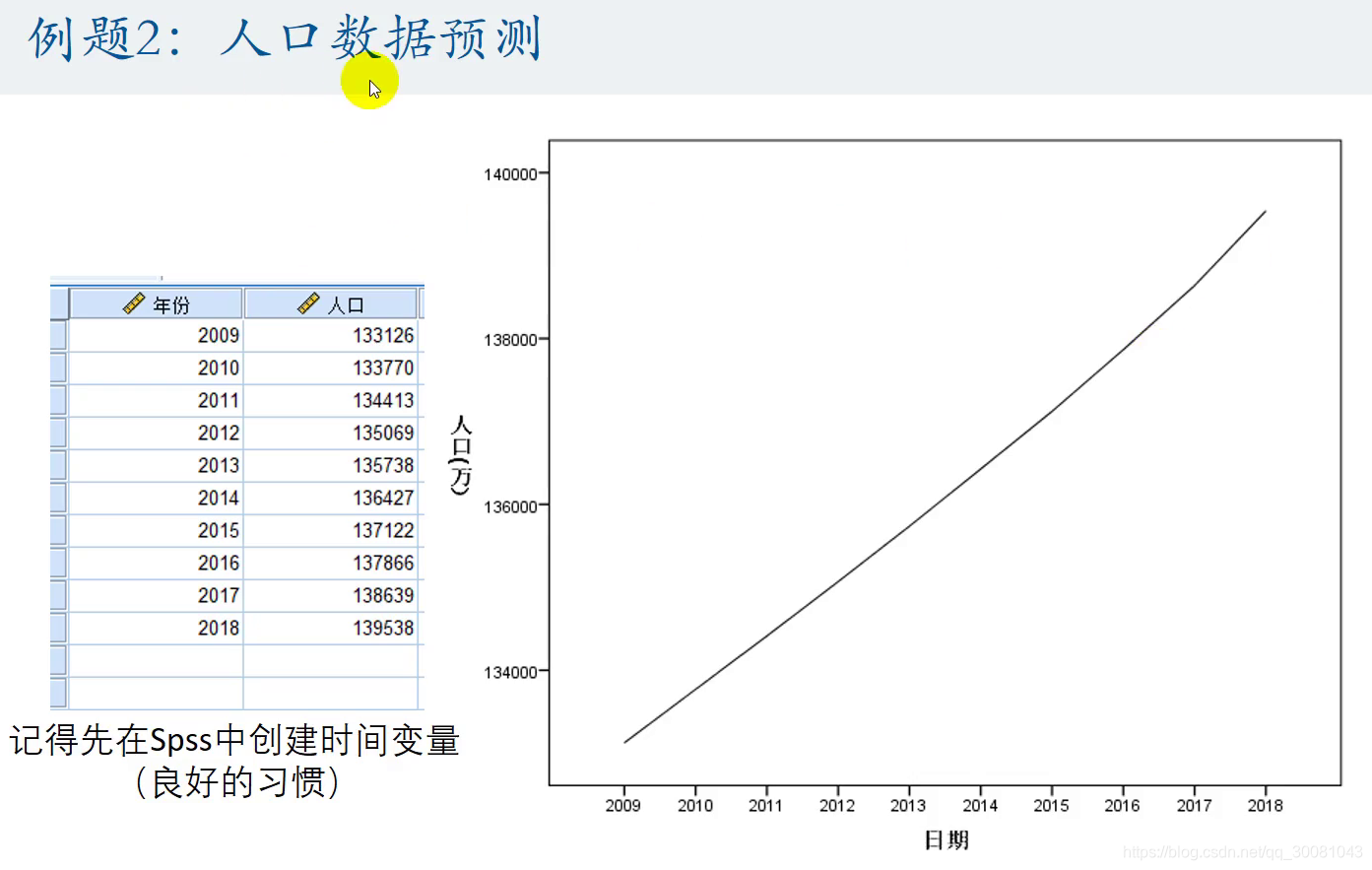
1.定义日期。
数据-定义日期
2.分析-时间序列预测-序列图
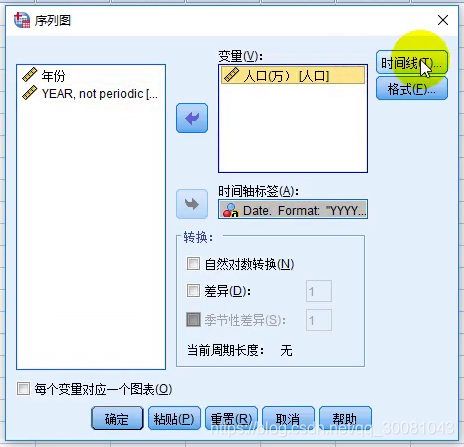
3.生成图(可以对图进行一些美化)
4. 分析-时间序列预测-时间序列建模器
然后在切换到统计,勾选参数估算值
再切换到图,勾选残差自相关函数和残差偏自相关函数和拟合值
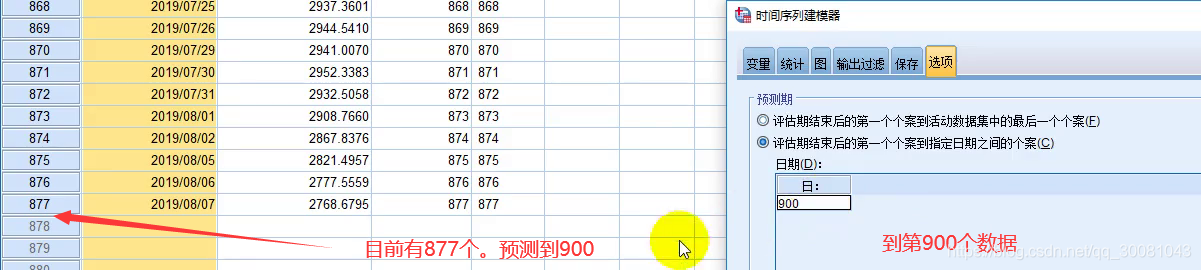
再切换到选项,预测到2025
再切换到保存 - 勾选 置信区间下界和上界
SPSS结果


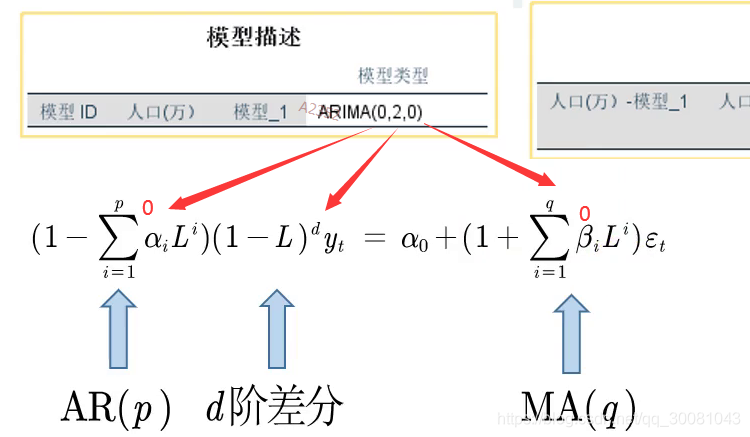
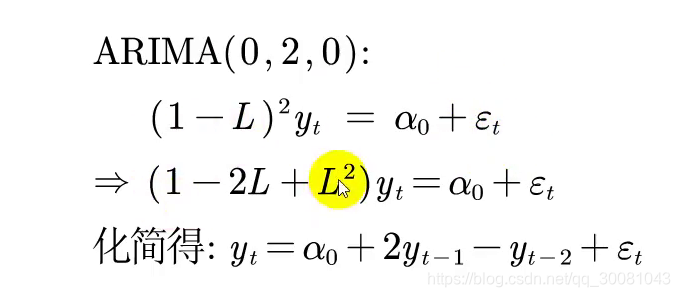

化简过程,参考滞后算子公式,可以得到!
α_0 = 估算 = 31.875

算出来的结果即SPSS给我们预测出来的。
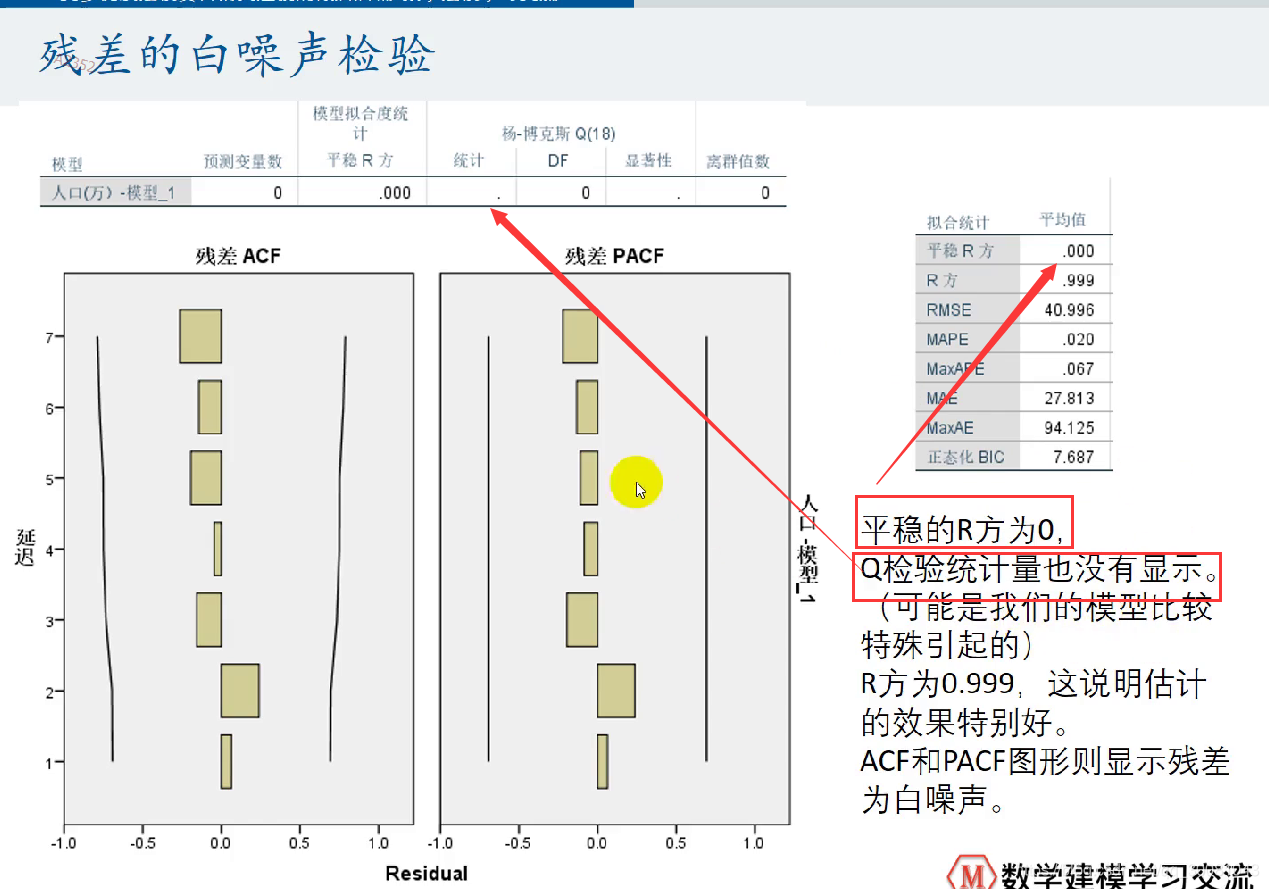
因为我们的模型特殊造成的,ARIMA (0,2,0),都为0,所以会这样。
R方为0.999则说明预测效果非常好
ACF和PACF的值都在两条线之内,没有显著异于0(或者说,和0没有显著的差异),所以残差为白噪声。
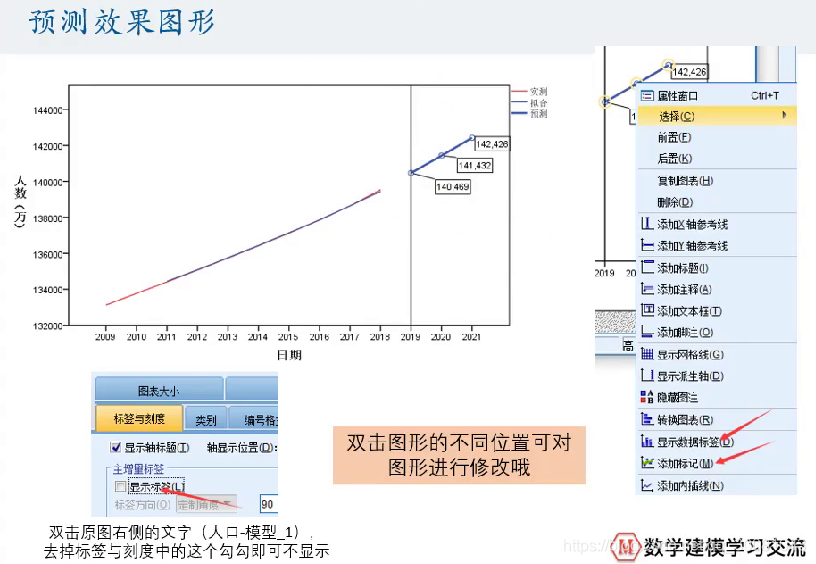
第5部分_实例3:上证指数预测和实例4GDP增长率预测
上证指数预测 (股票)
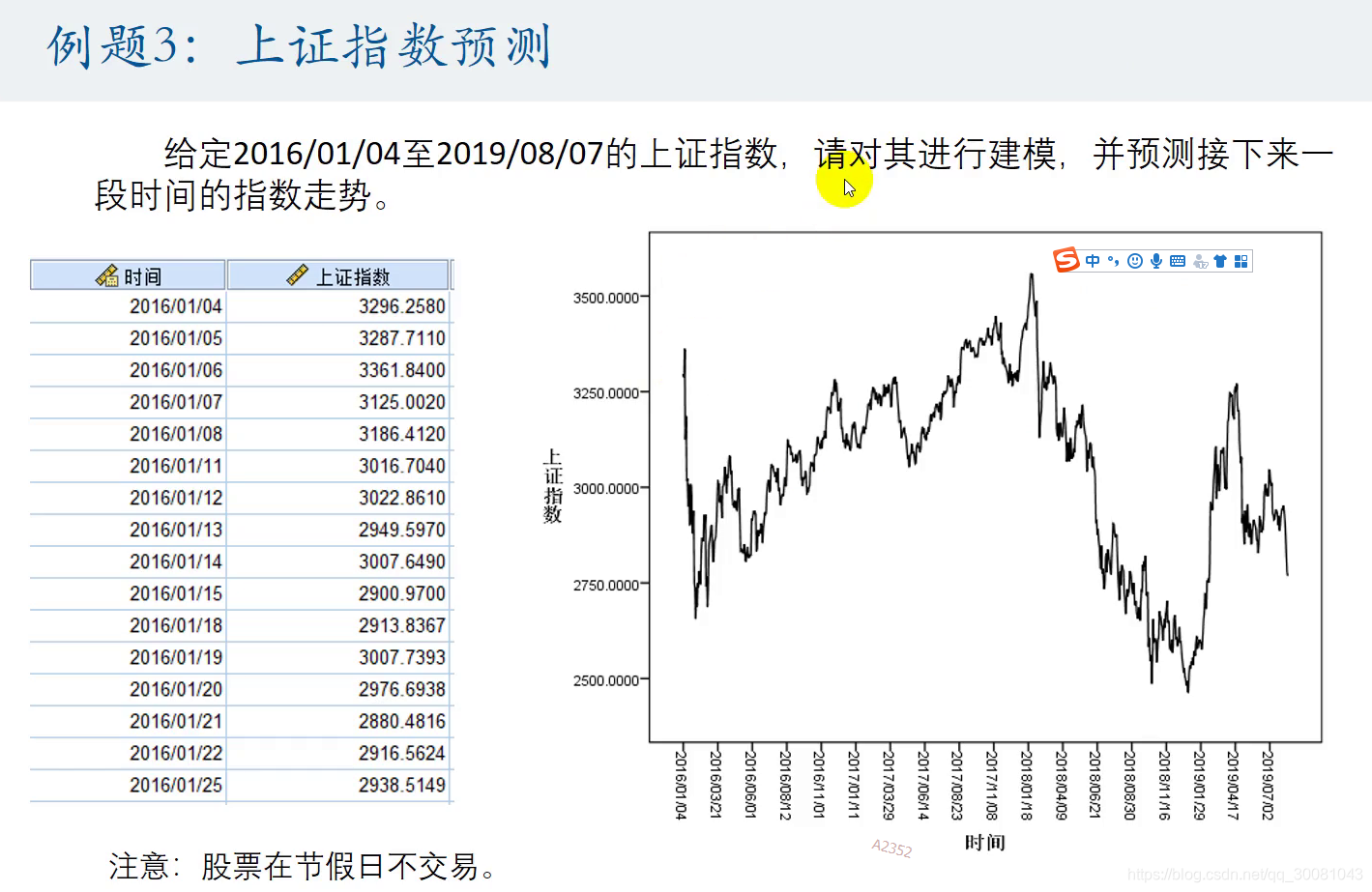
1.定义日期为天。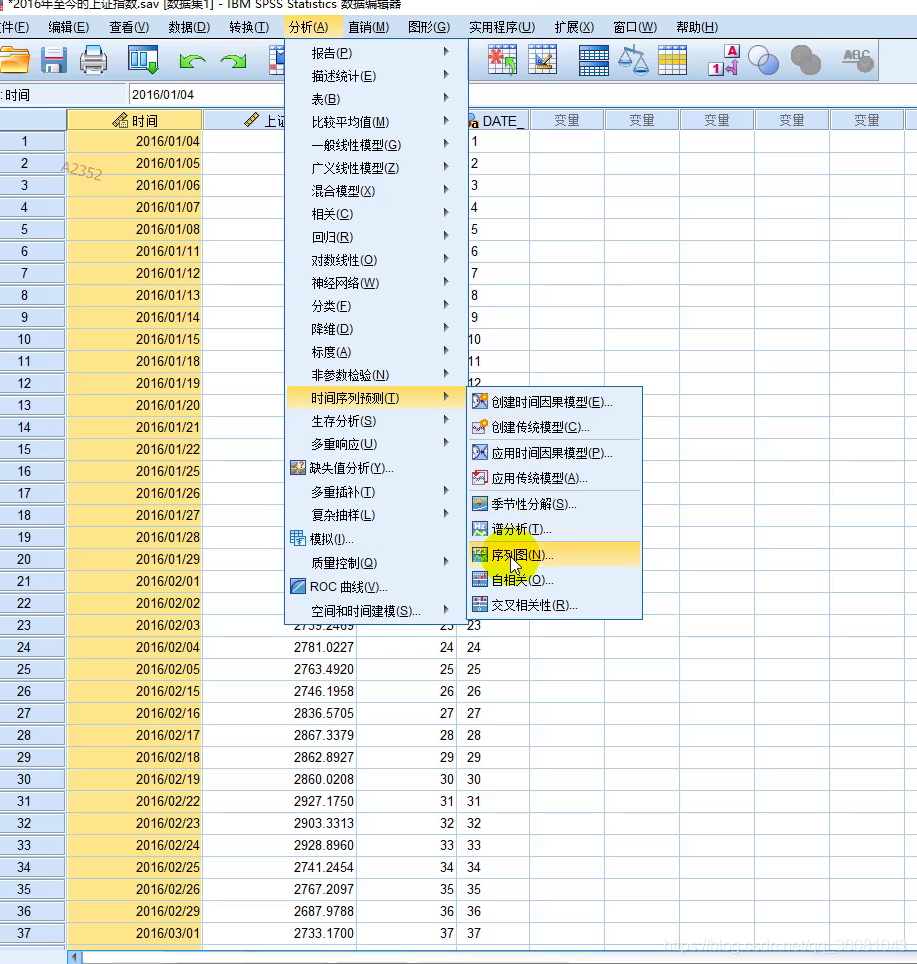
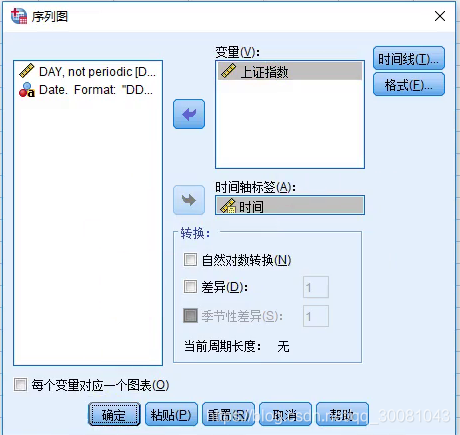
2.作序列图。
3.创建传统模型。

SPSS结果

简单的指数平滑模型。
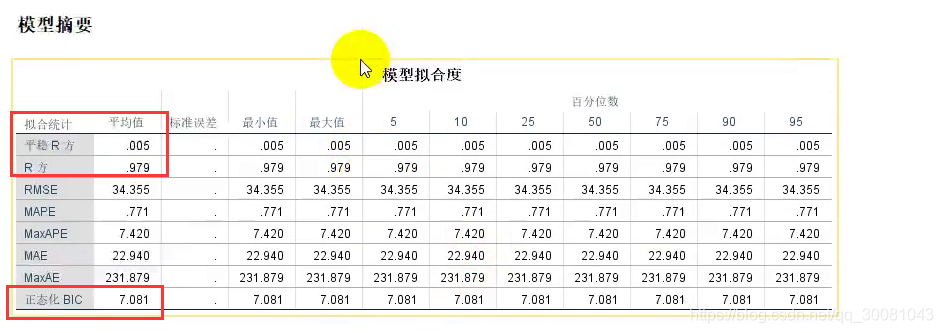
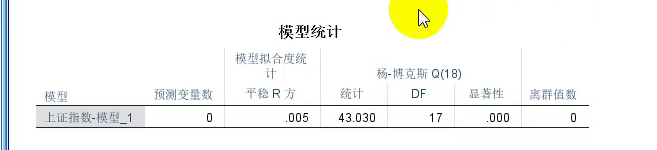
q检验的p值(显著性)为0,说明拒绝原假设。
说明我们的残差不是白噪声。说明简单指数平滑模型没有把我们的时间序列估计完全。
说明模型存在问题。模型可以存在异常值
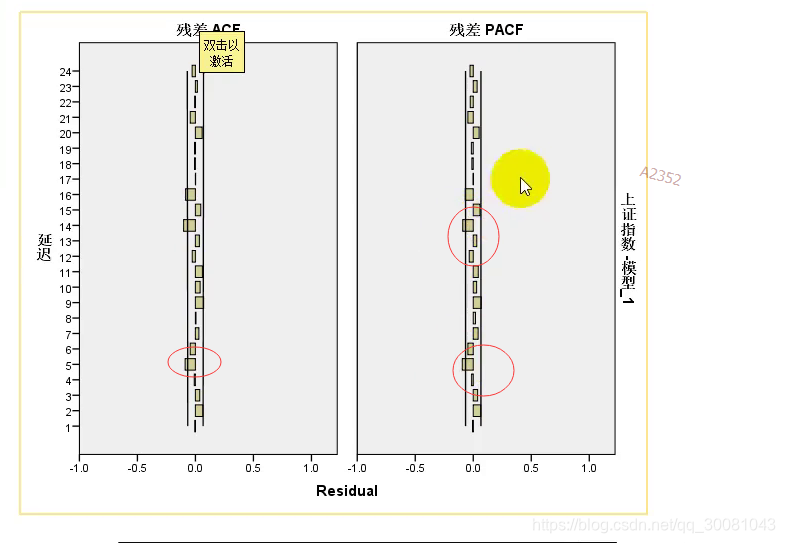
残差ACP,PACF存在显著异于0的地方,通过图,也可以得到我们的残差不是白噪声。
这个模型没有完全的识别出这个时间序列的特性。

指数平滑模型的估计值为0.933
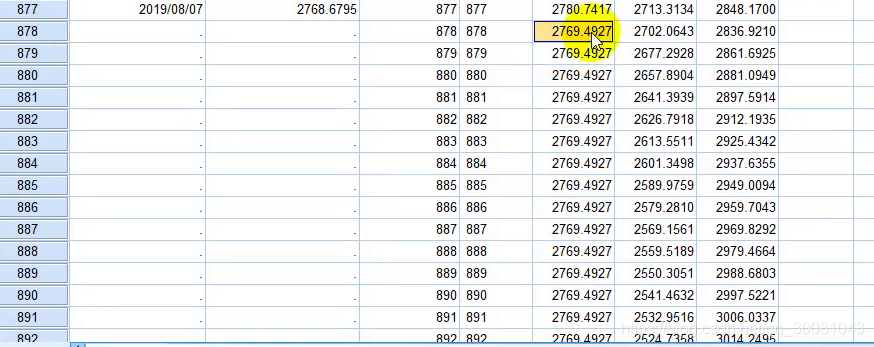
878到900都是2769.4927,置信区间的上下界在扩大。
简单的指数平滑模型只能预测一期。后面的数据都是一样的。
剔除异常值重新建模
新增一样东西,然后重新建模。
分析-时间序列预测-创建传统模型-时间序列建模器-变量-时间-条件-离群值-自动检验离群值-然后全选
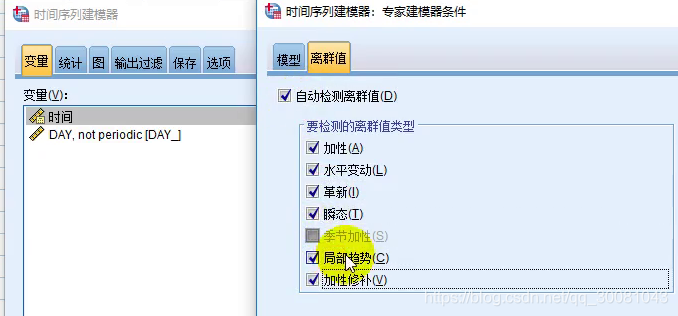
模型改变了。变成了ARIMA(0,1,14)
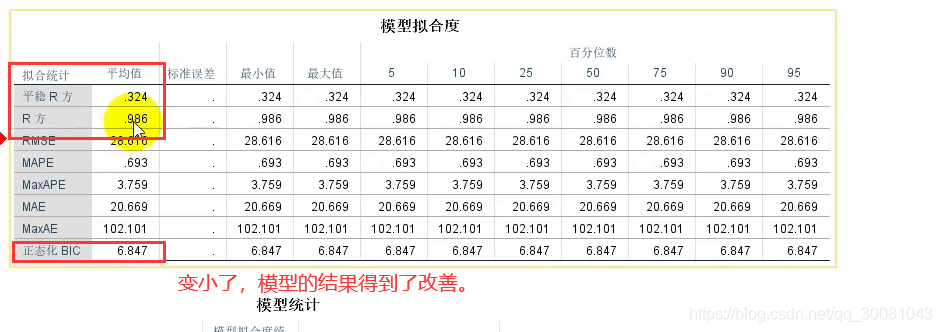


说明了模型是能很好估计出我们的数据的。
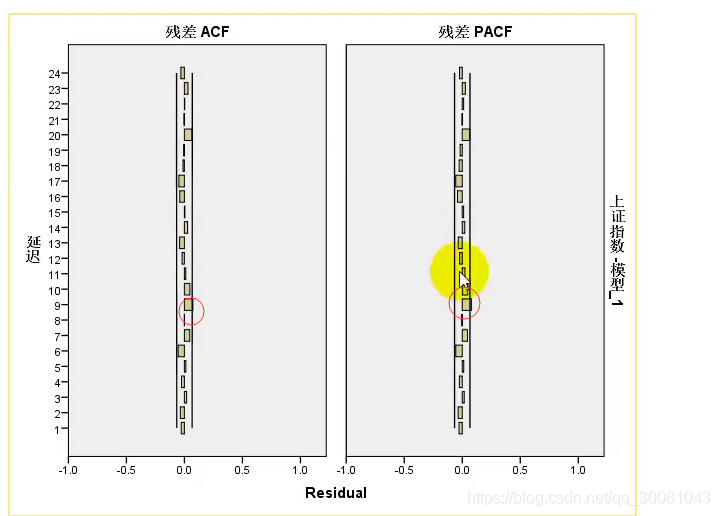
基本上都在线以内,通过q检验就可以知道残差是白噪声。
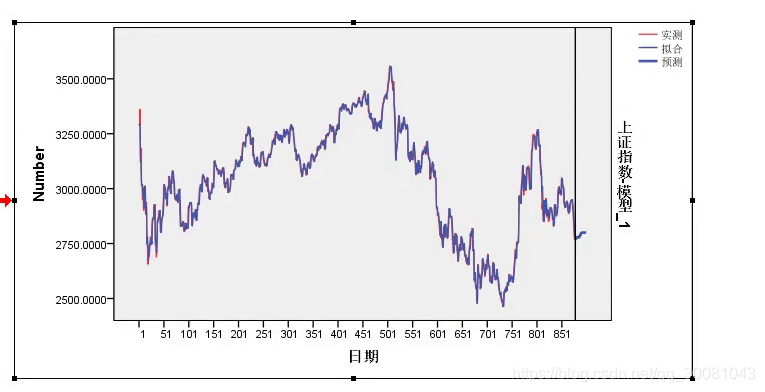
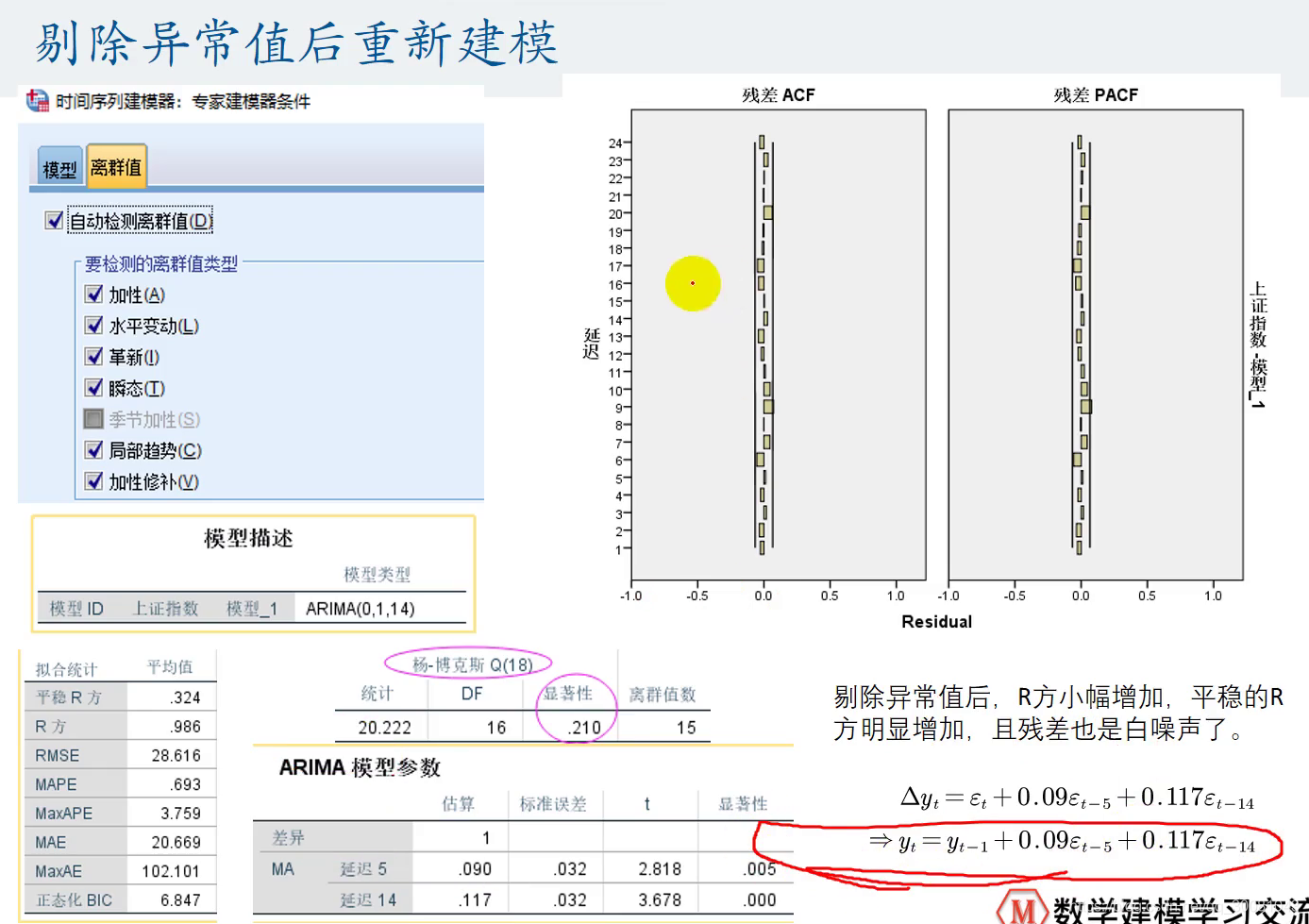
论文中需要把等式放上去。即上图,右下角。(与滞后算子公式相关的,需要手算出来。)
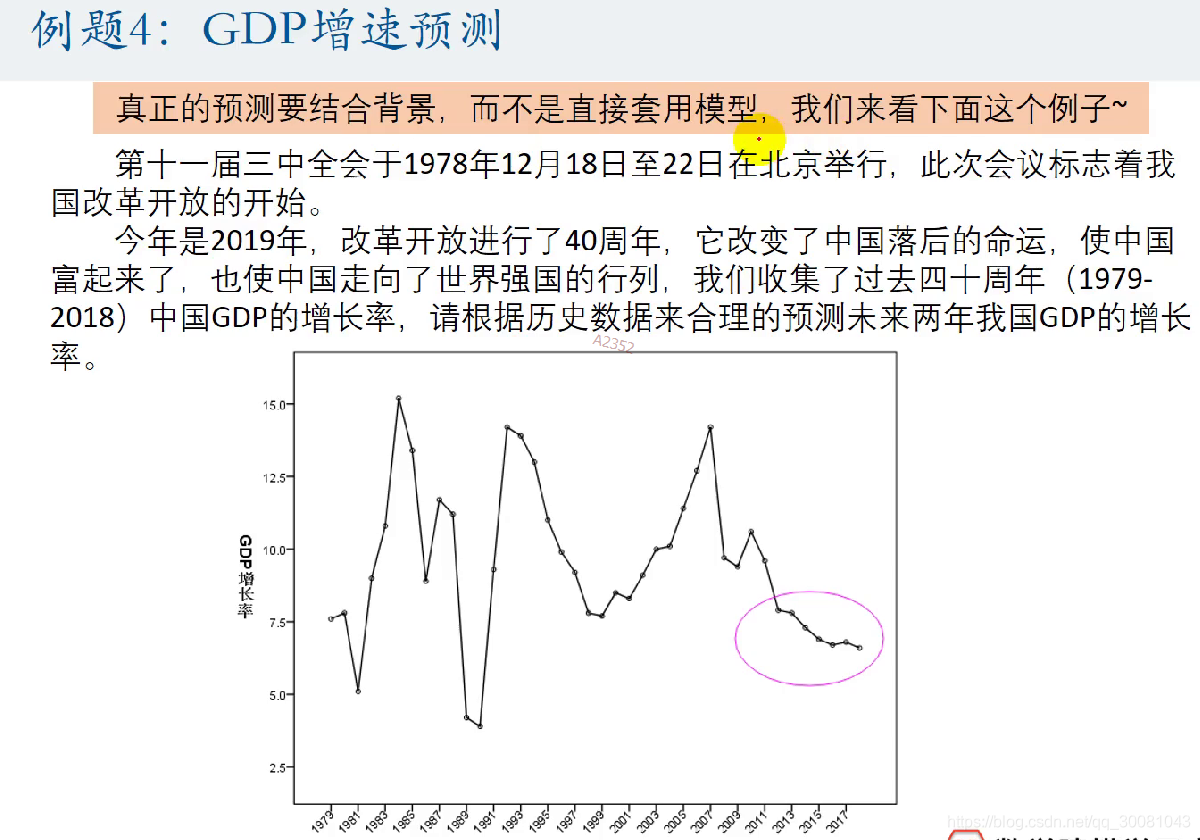
4GDP增长率预测
直接套模型的结果
1.定义时间
2.画时间序列图
3.对图进行简单分析。例如波动很大,近几年怎么样了。
4.创建模型,图,选项
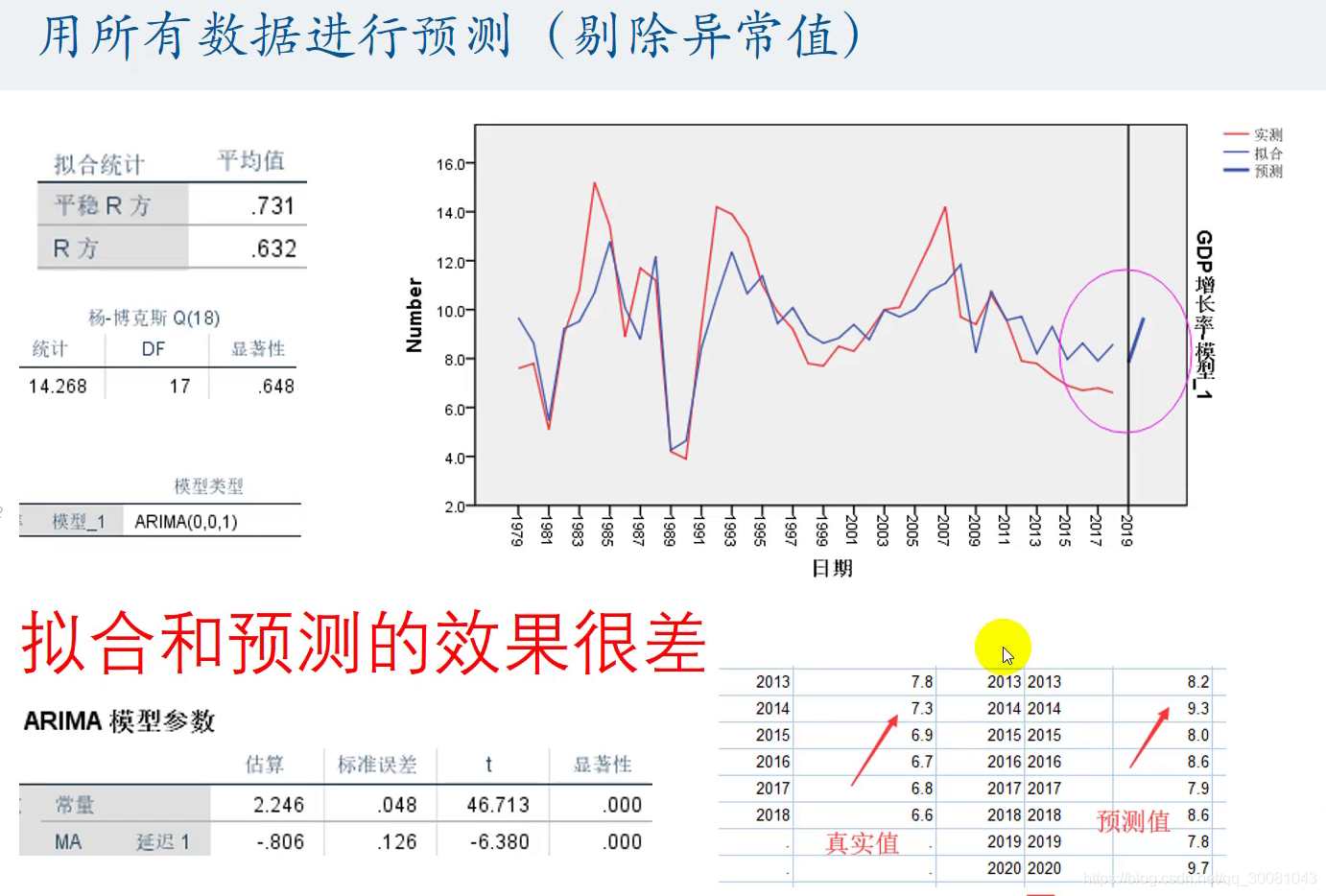

预测:结合背景,合理假设。
禁止:硬套模型
不要套模型,要结合背景。
不要不过解释,spss给出的模型,要进行解释。
比如:温特加法模型具有很强的季节性。
本例需要加入阻尼系数,让模型变得平缓。
###课后作业