YOLO不同于RCNN系列分为region proposal和classification,YOLO是直接输出box位置和box所属的类别,整张图都是网络的输入,是个回归问题。
YOLO的主要特点:
- 速度快,能够达到实时的要求。在 Titan X 的 GPU 上 能够达到 45 帧每秒。
- 使用全图作为 Context 信息,背景错误(把背景错认为物体)比较少。
- 泛化能力强。在自然图像上训练好的结果在艺术作品中的依然具有很好的效果。

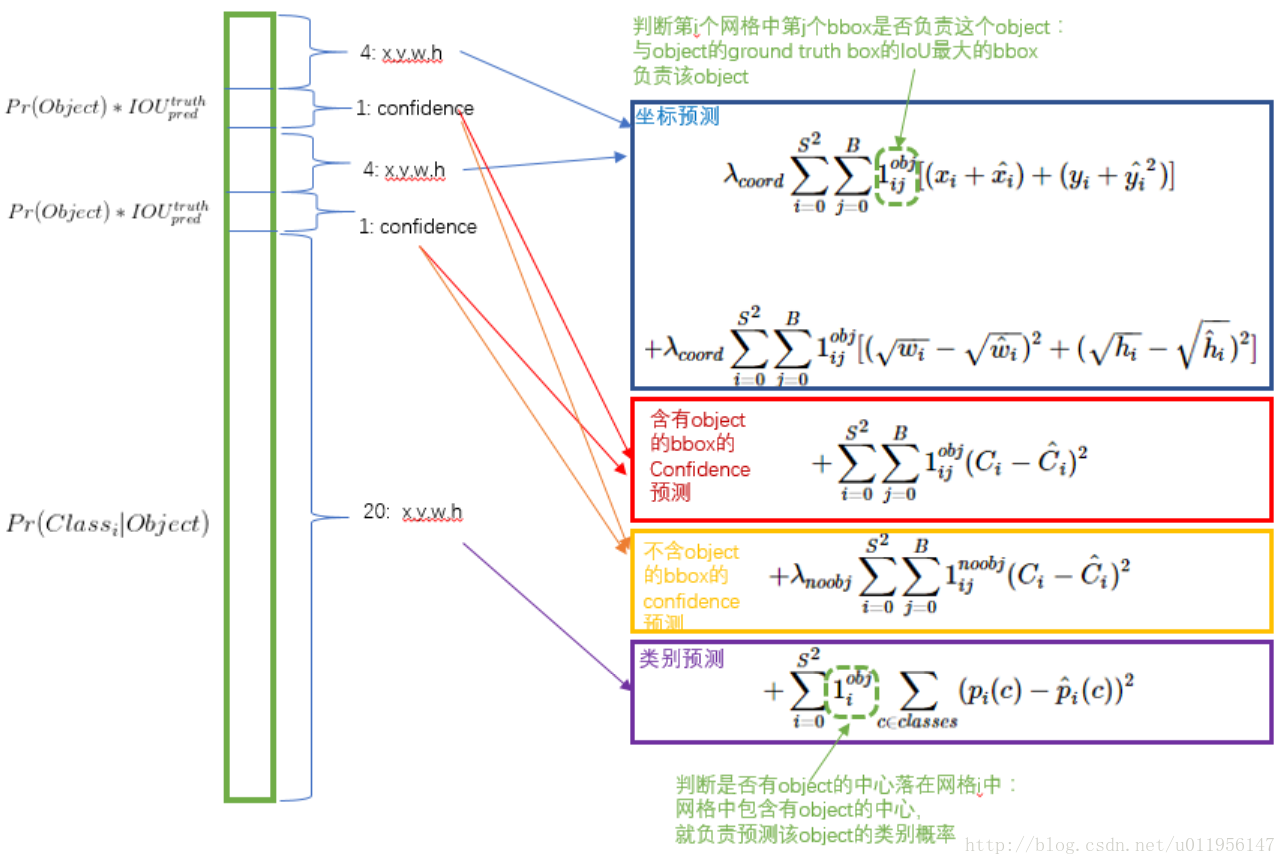
YOLO的主要思想就是把一副图片分成7x7的网格,如果某个物体中心落在网格中,这个网格就负责这个物体,在最后一层会输出一个7x7x((4+1)x2+20)维度,每个1x1 x((4+1)x2+20)代表原图中的7x7中的一个,其中4表示坐标,1表示得分,x2表示预测两个box,20表示20个类别。(4+1)的意思是每个bounding box除了要回归自身的位置之外,还要附带预测一个confidence值。这个confidence代表了所预测的box中含有object的置信度和这个box预测的有多准两重信息:
confidence=
其中如果有ground true box落在一个格子里,第一项取1,否则取0。第二项是预测的bounding box和实际的ground truth box之间的IOU值。即:每个bounding box要预测 ,共5个值,2个bounding box共10个值,对应 1*1*30维度特征中的前10个。大致流程如下:




NMS算法(非极大值抑制),主要的作用就是来抑制冗余的框,大致过程是迭代-遍历-消除。
1、 将所有的框按得分排序,选中最高分及其对应的框;
2、 遍历余下的框,如果和当前框(得分最高)的IOU大于某个阈值,便将框删除;
3、 从未处理的框中选中一个得分最高的,重复上述步骤
Yolo中的nms执行步骤大致如下:


训练策略:
该论文的训练策略,总体给人的感觉:比较复杂,技巧性比较强。可以看得出作者为了提升性能花了不少功夫。
- 首先利用 ImageNet 的数据集 Pretrain 卷积层。使用上述网络中的前 20 个卷积层,外加一个全连接层,作为
Pretrain 的网络,训练大约一周的时间,使得在 ImageNet 2012 的验证数据集 Top-5 的准确度达到
88%,这个结果跟 GoogleNet 的效果相当。 - 将 Pretrain 的结果应用到 Detection 中,将剩下的 4 个卷积层及 2 个全连接成加入到 Pretrain
的网络中。同时为了获取更精细化的结果,将输入图像的分辨率由 224*224 提升到 448*448。 - 将所有的预测结果都归一化到 0~1, 使用 Leaky RELU 作为激活函数。
- 对比 localization error 和 classification error,加大 localization 的权重
- 在 Pascal VOC 2007 和 2012 上训练 135 个 epochs, Batchsize 设置为 64, Momentum
为 0.9, Decay 为 0.0005. - 在第一个 epoch 中 学习率是逐渐从10−3增大到10−2,然后保持学习率为10−2,一直训练到 75个
epochs,然后学习率为10−3训练 30 个 epochs,最后 学习率为10−4训练 30 个 epochs。 - 为了防止过拟合,在第一个全连接层后面接了一个ratio=0.5的 Dropout
层。并且对原始图像做了一些随机采样和缩放,甚至对调节图像的在 HSV 空间的饱和度。
损失函数:
采用sum-squared error loss,做如下调整:
1、 更重视8维坐标的预测,乘以更大的loss weight,在VOC中取λcoord = 5;
2、 对于没有object的box的confidence loss,赋予更小的loss weight,在VOC中取λnoobj = 0.5
3、 对于有object的box的confidence loss和class loss的loss weight 取1。
4、 训练过程中,小的 Box 对位置回归错误比大的 Box 更加敏感,由于w和h都已经归一化到 0~1,之间,作者使用了一个 trick,不是直接使用w和h,而是使用它们的平方根,这样使得,w和h在较小时,相应的√w和√h会大一点。

5、 一个网格预测多个bounding box,在训练时我们希望每个object(ground true box)只有一个bounding box专门负责(一个object 一个bbox)。具体做法是与ground true box(object)的IOU最大的bounding box 负责该ground true box(object)的预测。这种做法称作bounding box predictor的specialization(专职化)。每个预测器会对特定(sizes,aspect ratio or classed of object)的ground true box预测的越来越好。(个人理解:IOU最大者偏移会更少一些,可以更快速的学习到正确位置)(参考:参考链接)
在方程中S取7

缺陷:
- 每个格子只预测一个类别的box,而且最后只取置信度最大的box,这就导致了如果多个不同物体(或者同类物体的不同实体)的中心在同一个网格找那个,会造成漏检(对挨着的物体和小物体检测效果不好);
- 预测的 Box 对于尺度的变化比较敏感,在尺度上的泛化能力比较差;
本文很多都是参考:
http://blog.csdn.net/surgewong/article/details/51864859
图片来源: 可能需要翻墙
本文链接:http://blog.csdn.net/u011956147/article/details/73013106