目标检测系列:
目标检测(object detection)系列(一) R-CNN:CNN目标检测的开山之作
目标检测(object detection)系列(二) SPP-Net:让卷积计算可以共享
目标检测(object detection)系列(三) Fast R-CNN:end-to-end的愉快训练
目标检测(object detection)系列(四) Faster R-CNN:有RPN的Fast R-CNN
目标检测(object detection)系列(五) YOLO:目标检测的另一种打开方式
目标检测(object detection)系列(六) SSD:兼顾效率和准确性
目标检测(object detection)系列(七) R-FCN:位置敏感的Faster R-CNN
目标检测(object detection)系列(八) YOLOv2:更好,更快,更强
目标检测(object detection)系列(九) YOLOv3:取百家所长成一家之言
目标检测(object detection)系列(十) FPN:用特征金字塔引入多尺度
目标检测(object detection)系列(十一) RetinaNet:one-stage检测器巅峰之作
目标检测(object detection)系列(十二) CornerNet:anchor free的开端
目标检测扩展系列:
目标检测(object detection)扩展系列(一) Selective Search:选择性搜索算法
目标检测(object detection)扩展系列(二) OHEM:在线难例挖掘
目标检测(object detection)扩展系列(三) Faster R-CNN,YOLO,SSD,YOLOv2,YOLOv3在损失函数上的区别
前言
Faster R-CNN,YOLO和SSD在通用目标检测领域有着奠基一般的作用, 而YOLOv2和YOLOv3由于其灵活易用的特性,在工业界一直很受欢迎,下面这篇文章主要想从损失函数的角度集中讨论下这几个主流框架的区别。
分类损失
分类在目标检测任务中的作用是确定一个目标到底应该属于哪个类别。
- Faster R-CNN
需要注意的是,这里的Faster R-CNN讨论的是RPN的损失,所以在分类损失中,Faster R-CNN的RPN用的是二值交叉熵,因为RPN分类是区分当前的区域是不是个目标的二分类问题。 - SSD
SSD,是one-stage的结构,没有区域建议,它的分类损失是交叉熵,如果是针对VOC数据集,那么类别应该是20类,针对COCO数据集,类别是80类。
此外还有一个小区别是,SSD有背景类,比如COCO数据集上,SSD要区域81类。 - YOLO,YOLOv2
YOLO和YOLOv2是one-stage的结构,没有区域建议,但是YOLO和YOLOv2做分类的时候用的L2 loss,是将分类问题当作回归任务来处理。 - YOLOv3
YOLOv3和YOLOv2、SSD都不同,它的分类损失既不使用softmax+交叉熵来做,又没有用L2,而是使用n个二值交叉熵来做,比如在COCO上,使用一个80类的交叉熵是可以实现的,但是YOLOv3用了Logistic+二值交叉熵处理,将一个80分类问题转化为80个二分类问题。
回归损失
回归在目标检测任务中的作用是确定一个和Ground Truth重合度尽量高的边界框,即 , , 和 。下面提到的区别包含了边界框的表示和损失函数,为了表达起来方便,我们把它拆成三个部分,分别是边界框的中心 ,边界框的尺寸 和损失函数 。
边界框的中心点
- Faster R-CNN和SSD
Faster R-CNN的RPN和SSD在处理边界框的中心点时采用的是相同的思路,并且它们都有Anchor,其实是SSD借鉴了RPN,最后一层特征图上的点决定了预设的中心点,RPN和SSD要预测的是Ground Truth对中心点的offset,并除Anchor的宽高后的结果,假设预设框为 ,ground truth为 ,从公式中可以看出来, 和 都表示中心点坐标。那么转换后的ground truth坐标 依照下面方式求取:
- YOLO,YOLOv2和YOLOv3
YOLO系列的结构中,YOLO是没有Anchor的,YOLO只有格子,YOLOv2和YOLOv3带Anchor,但是这并不影响它们边界框中心点的选择,它们的边界框中心都是在预测距离格子左上角点的offset,这一点和Faster R-CNN与SSD是不同的。
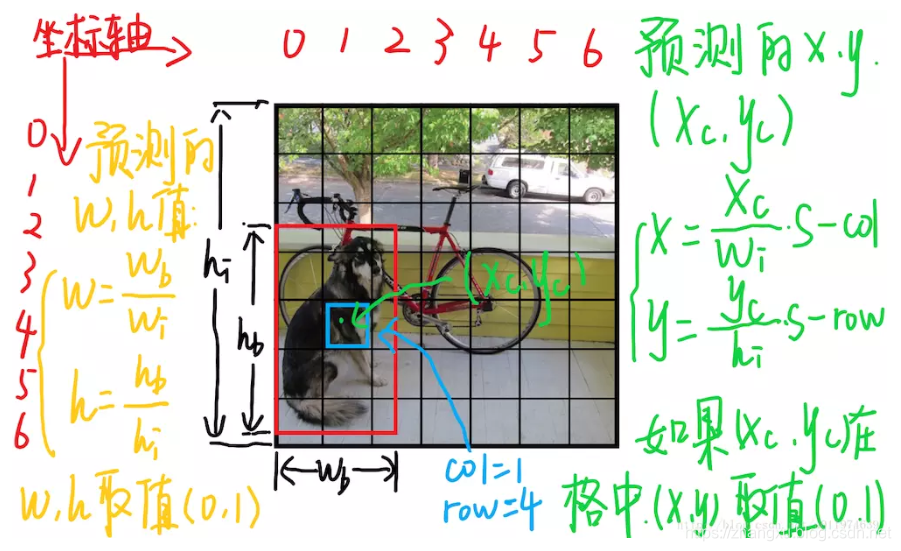
特别说明,上图来自《YOLO文章详细解读》
对于上图中蓝色框对应的格子(坐标为 ),假设它预测的输出是红色框的bbox,设bbox的中心坐标为 ,那么最终预测出来的 是经过归一化处理的,表示的是中心相对于单元格的offset,计算公式如下。其中 是格子的数量, 和 是图片的宽高。
边界框的尺寸
-
YOLO
在边界框尺寸这个方面,YOLO显得非常孤立,因为它是这5个结构中唯一无Anchor的,由于没有先验,所以YOLO在表达 时非常的简单粗暴,就是相对于整个图片的比例做了归一化。
特别说明,上图来自《YOLO文章详细解读》 -
Faster R-CNN,SSD,YOLOv2和YOLOv3
Faster R-CNN,SSD,YOLOv2和YOLOv3都带Anchor,所以它们对于 的处理是一致的,就是根据Anchor,用对数函数,对预测值和ground truth去重新编码。
下面是SSD中用Anchor编码的ground truth例子:假设预设框为 ,ground truth为 ,从公式中可以看出来。那么转换后的ground truth坐标 依照下面方式求取:
这里使用的是 ,其实可以看做 。
在YOLOv2中这个形式会变一下,但是本质上是一样的,总结来看,根据边界框预测的4个offset ,可以按照下列公式计算出ground truth在特征图上的相对值 。
上式中把 除过来,然后两边取对数,就和SSD一样了。
所以这就是为什么Faster R-CNN,SSD,YOLOv2和YOLOv3中都有log,就是为了根据Anchor对预测值和ground truth去重新编码。
损失函数
- Faster R-CNN和SSD
SSD可以说在边界框回归问题上完全参考RPN,包括损失函数,所以它们都用smooth L1损失。 - YOLO,YOLOv2和YOLOv3
YOLO系列在边界框回归损失上用的是L2,并没有参考RPN。
其他损失
最后就是除了分类损失和回归损失外的其他损失函数,主要是起到辅助作用。
- Faster R-CNN和SSD
PRN和SSD是没有其他损失函数的,因为RPN只有两类,其中包含了负类,SSD的类别中也包含背景类。 - YOLO,YOLOv2和YOLOv3
YOLO系列在最后的类别输出上是不包含背景类的,所以它在输出上加上了一个confidence,所以YOLO系列处理基础的分类损失和回归损失外,还需要有一个confidence损失,去评价当前的区域是object还是no object。
