目录
相关内容:
一、概览
1.1 贡献点
- 将目标检测的定位问题转化为回归问题
- 将目标检测实现为单个网络,端到端实现(单阶段目标检测模型)
- 帧率快,达到实时帧率。YOLO达到45fps,fast YOLO达到155fps
- 与SOTA(state of the art)模型相比,YOLO有更大的定位误差,但是有更少的伪正样本。
- 比DPM或者R-CNN学出更具general的representations。
1.2 背景
深度学习目标检测2013-2018单双阶段主流模型概览及详解:
https://blog.csdn.net/weixin_36474809/article/details/84172579
目标检测模型旨在从图片中定位出目标。分为单阶段目标检测模型和双阶段目标检测模型。

双阶段
一个阶段提出备选框,一个阶段对备选框进行判断。是一个两阶段级联的网络。主要为RCNN系列的网络。
- RCNN
- SPPNet(Spatial Pyramid Pooling)
- Fast RCNN
- Faster RCNN
- RFCN(Region based Fully ConvNet)
- Mask RCNN
- Light Head RCNN
单阶段
单阶段的网络,整个生成备选框的过程一体化的实现。代表有YOLO系列和SSD(single shot detector)
- DetectorNet
- OverFeat
- YOLO
- YOLOv2 and YOLO9000
- SSD(Single Shot Detector)
二、方法
2.1 Unified detection
之前的双阶段模型,如RCNN系列,将模型分为两部分,一部分给出备选框,另一部分进行备选框的预测。而YOLO将图片作为一个整体进行预测。

分格:
- YOLO将输入图片分为S*S个方格,如果目标检测的物体Object存在于方格之中,则方格负责对物体做出预测。
- 每个方格预测出B个备选框,备选框带有置信概率(confidence scores),注意此置信概率是有目标物体的置信概率,不是类别的置信概率
- 置信概率(confidence scores)定义为Pr(Object)*IOU, 即分类的物体的置信概率与标定框和网络预测框的IOU交并比。
- 每个bounding box的预测包括五个量。x,y中心点的坐标,w,h宽和高,confidence置信概率
- 每个grid预测得出C个条件概率的标签Pr(Class_i | Object)
- 测试阶段, 用条件概率算出每个格子的概率。 Pr(Class_i | Object)*Pr(Object)*IOU=Pr(Class_i)*IOU
最终,每个S*S的方格预测得出B个备选框(包含5个坐标,x,y,w,h,confidence),同时,每个方格预测得到每个C类的置信概率。最终,网络预测输出一个张量 S*S*(B*5+C). 例如在PASCAL VOC数据集上,作者采用了S=7,也就是7×7个方格,B=2,每个方格负责预测得到2个备选框,同时,因为网络是20个分类标签,是C=20,所以最终预测的张量是:S*S*(B*5+C)=7×7×(2×5+20)
2.2 网络结构设计
采用卷积神经网络的结构,卷积层提取特征,最终全连接层进行张量的预测,张量包含概率和坐标。沿用GoogLeNet的结构。用1×1的reduction layer后面跟3×3的卷积layer。

预测框被归一化为0-1之间。
激活函数:Leakey ReLU
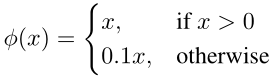
Loss函数:
由两部分构成,定位误差与分类误差。localization error与classification error, 定位误差相对于分类误差更重要一些,因此将定位误差的系数 λ_coord设为5,分类误差的系数 λ_noobj设为0.5

- 平方误差与平方根误差:定位时候,平方误差对大目标更加敏感,但是大目标与小目标同等重要,因此,定位误差由两项组成,平方误差与平方根误差。
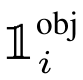 表示目标object出现在格子 i 中。所以当前格子需要对类别做出预测。
表示目标object出现在格子 i 中。所以当前格子需要对类别做出预测。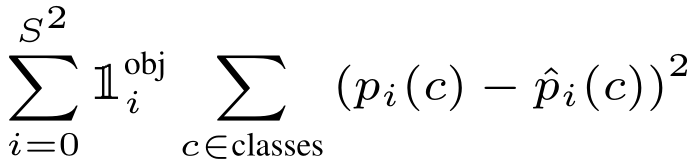 ,表示每个S*S的格子需要预测出正确的类别。
,表示每个S*S的格子需要预测出正确的类别。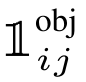 表示每个S*S生成的格子,生成了B个Boundingbox,这B个bounding box需要对目标做出预测。
表示每个S*S生成的格子,生成了B个Boundingbox,这B个bounding box需要对目标做出预测。- 目标误差与类别误差,目标误差表示B个bbox中每个出现目标。类别误差表示当前S×S的grid预测出现的类别。
2.3 缺点
小目标效果差,宽高比不规则物体效果差,IOU指标的不合理性
- 每个S×S的grid只预测得出一个类别,但是实际上每个grid可能有多个类别均在此grid之中。同时,对于小目标的检测效果较差。
- 因为对已有的数据集进行训练,当实际的备选框出现特殊的宽高比的时候(比如长条状),则检测效果就会变差。
- IOU标准的缺点,IOU是交并比,但是对于小物体,并集的面积偏小,会导致IOU偏大,因此IOU有一定的不合理性。
三、实验
在PASCAL VOC2007数据集上进行实验。并且与其他实时模型进行比较,并与双阶段模型,如R-CNN进行对比。
3.1 模型性能对比
对比相应的帧率和mAP,可以看出,实时模型中,YOLOmAP最高,且Fast YOLO速率最快。

3.2 错误样本分析
用IOU与分类作为评价标准,目标检测结果分为下列几类。
- Correct正确样本:分类正确且 IOU>0.5,
- Loc定位错误样本,分类正确且 0.1<IOU<0.5
- Sim相近样本:分类相近,且 IOU<0.1
- Other其他:分类错误,IOU>0.1
- Background背景:IOU<0.1 (贡献点中提到,YOLO可以检测出更少的background,从下面图中即可看出)

3.3 YOLO与fast-RCNN的boost
YOLO可以检测出更少的background,而fast-RCNN可以达到更高的mAP-71.8,因此,两个网络可以通过boosting的过程结合。

通过实验,YOLO对与提升RCNN的性能非常有帮助。在PASCAL2012的数据集上,YOLO与RCNN结合能够达到最高的mAP

3.4 实时检测模型对比
在三个数据集上进行对比,VOC2007,Picasso,People-art上。


四、结论及个人评价
将双阶段的目标检测模型改进为单阶段目标检测模型,非常具有开创性。并且将bounding box的坐标值预测为张量,将目标检测的定位实现为一个回归问题。
相关内容:
YOLOv3:Darknet代码解析(一)安装Darknet
YOLOv3:Darknet代码解析(六)简化的程序与卷积拆分
