根据《机器学习实战》中国工信出版集团 人民邮电出版社 学习得到的笔记
一、决策树
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目迎合,判断其可行性的决策分析方法,是直观运行概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的树干,故称决策树。
在机器学习 ,决策树是一个预测模型,它代表的是对象属性与对象值之间的一种映射关系。Entropy = 系统的混乱程度,使用算法ID3,C4.5和C5.0生成树算法使用熵。这一度量是基于信息学理论中熵的概念。
决策树是一种树形结果,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
决策树(Decision Tree)算法主要用来处理分类问题,是最经常使用的数据挖掘算法之一,是一种监督学习。
一个决策树包含三种类型的节点:
- 决策节点:通常用矩形框来表示
- 机会节点:通常和圆圈来表示
- 终结束:通常用三角形来表示
1、决策树的构造
在构造决策树前,我们先讨论下数学上如何信息论划分数据集,然后再将理论用代码实现到具体的数据集上,最后构建决策树。
在构建决策树时,我们需要解决的第一个问题是:当前数据集哪个特征在划分数据分类时起决定性作用,即我们要如何找出最优的分类特征。为了找到决定性的特征,划分出最好的结果,我们必须评估每个特征。完成数据划分后,原始数据集就被划分为几个数据子集,这些数据子集会分布在第一个决策点的所有分支上。如果某个分支下的数据属于同一类型,即数据已正确分类,无需进一步分割。如果数据子集内的数据不属于同个类型,则需要重复划分数据子集的过程。划分数据子集的算法和划分原始数据集的方法相同(因此可用递归函数继续划分子集),直到所有具有相同类型的数据都在一个数据子集内。
构建决策树的伪代码函数createTree() 如下所示:
检测数据集中的每个子集是否属于同一分类:
If so return 类标签
Else
寻找划分数据集的最好特征
划分数据集
创建分支节点
For 每个划分的子集:
调用函数createTree()并增加返回结果到分支节点中
Return 分支节点
上面是个的伪代码是个递归函数,递归的结束条件是遍历完所有数据集的属性或每个分支下的所有实例都具有相同分类
- 在原始数据集上基于最好的特征进行划分
- 划分后得到新的数据集
- 将新的数据集后放到分支节点上去
- 接着再调用1、2、3直到不能划分为止
如何划分数据集?(如何采用量化的方法判断如何划分数据)
划分数据集的大原则是:将无序的数据变得更加有序。在划分数据集前后,信息发生的变化称为信息增益。获得信息增益最高的特征就是最好的选择。
1、信息增益(香农熵&熵)
集合信息的度量方式称为香农熵或者简称为熵。熵定义为信息的期望值。关于信息的概念:
如果待分类的事物可能会出现多个结果x,则第i个结果xi发生的概率为p(xi),那么我们可以由此计算出xi的信息熵为:
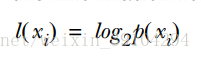
那么,对于所有可能出现的结果,事物所包含的信息希望值(信息熵)就为:
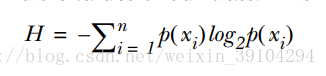
下面开始用python计算信息熵,创建一个trees.py 文件 写入下列代码(计算给定的数据集的香农熵):
代码来自于apachCN,感谢代码中的注释。求数据集中每个实例标签出现的频率,然后用这个频率 计算香农熵:
from math import log
import operator
def calcShannonEnt(dataSet):
"""calcShannonEnt(calculate Shannon entropy 计算给定数据集的香农熵)
Args:
dataSet 数据集
Returns:
返回 每一组feature下的某个分类下,香农熵的信息期望
"""
# -----------计算香农熵的第一种实现方式start--------------------------------------------------------------------------------
# 求list的长度,表示计算参与训练的数据量
numEntries = len(dataSet)
# 下面输出我们测试的数据集的一些信息
# 例如:<type 'list'> numEntries: 5 是下面的代码的输出
# print type(dataSet), 'numEntries: ', numEntries
# 计算分类标签label出现的次数
labelCounts = {}
# the the number of unique elements and their occurance
for featVec in dataSet:
# 将当前实例的标签存储,即每一行数据的最后一个数据代表的是标签
currentLabel = featVec[-1]
# 为所有可能的分类创建字典,如果当前的键值不存在,则扩展字典并将当前键值加入字典。每个键值都记录了当前类别出现的次数。
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
# print '-----', featVec, labelCounts
# 对于label标签的占比,求出label标签的香农熵
shannonEnt = 0.0
for key in labelCounts:
# 使用所有类标签的发生频率计算类别出现的概率。
prob = float(labelCounts[key])/numEntries
# log base 2
# 计算香农熵,以 2 为底求对数
shannonEnt -= prob * log(prob, 2)
# print '---', prob, prob * log(prob, 2), shannonEnt
# -----------计算香农熵的第一种实现方式end--------------------------------------------------------------------------------
# # -----------计算香农熵的第二种实现方式start--------------------------------------------------------------------------------
# # 统计标签出现的次数
# label_count = Counter(data[-1] for data in dataSet)
# # 计算概率
# probs = [p[1] / len(dataSet) for p in label_count.items()]
# # 计算香农熵
# shannonEnt = sum([-p * log(p, 2) for p in probs])
# # -----------计算香农熵的第二种实现方式end--------------------------------------------------------------------------------
return shannonEnt接着构建一个测试用的测试数据集
def createDataSet():
"""DateSet 基础数据集
Args:
无需传入参数
Returns:
返回数据集和对应的label标签
"""
dataSet = [[1, 1, 'yes'],#最后一列出现不同标签的数量越高,则熵越大,代表无序程序越高,我们在数据集中添加的分类就越多
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
# dataSet = [['yes'],
# ['yes'],
# ['no'],
# ['no'],
# ['no']]
# labels 露出水面 脚蹼
labels = ['no surfacing', 'flippers']#在这里,数据集是针对标签的,第一个数据对应第一个标签,最后一个数据代表判断标签
# change to discrete values
return dataSet, labels在Python命令提示符下输入下列命令,得到这份数据的香农熵:
>>> reload(trees)
>>> myDat,labels = trees.createDataSet()
>>> myDat
[[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
>>> labels
['no surfacing', 'flippers']
>>> trees.calcShannonBnt(myDat)
>>> trees.calcShannonEnt(myDat)
0.9709505944546686熵越高,则混合的数据也越多,数据也越混乱,例如在数据集中添加更多的分类,观察熵的变化情况。这里增加第三个名为maybe的分类,测试香农熵的变化:
>>> myDat[0][-1] = 'maybe'
>>> myDat
[[1, 1, 'maybe'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
>>> trees.calcShannonEnt(myDat)
1.3709505944546687得到熵之后,我们可以按周获取最大信息增量的方法划分数据集。
2、划分数据集
学习了如何度量数据集的无序程度,分类算除了需要测量信息熵,还需要划分数据集,度量划分数据集的熵,以便判断当前是否正确地划分了数据集。我们将对每个特征划分数据集的结果计算一次信息熵,然后判断按照哪个特征划分数据集是最好的划分方式。
在trees.py文件中添加下列的代码(按照给定的特征划分数据集):
"""
Function:
按给定特征划分数据集
Parameters:
dataSet——待划分的数据集
axis——划分数据集的特征
value——特征的返回值
Return:
retDataSet——划分好后的数据集列表
Modify:
2017-11-29
"""
def splitDataSet(dataSet, axis, value):
retDataSet = []
#创建返回数据列表对象
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
#去掉axis特征
reducedFeatVec.extend(featVec[axis+1:])
#将符合条件的添加到返回的数据里表中
retDataSet.append(reducedFeatVec)
return retDataSet
#返回划分后的数据集这里要特别提醒下python语言列表类型知道的extend()和append()方法,这两个方法功能类似,但是在处理多个列表时,这两个方法处理得到的结果是完全不一样的。这里借用apachCN中的内容解释两者的区别
extend和append的区别
list.append(object) 向列表中添加一个对象object
list.extend(sequence) 把一个序列seq的内容添加到列表中
1、使用append的时候,是将new_media看作一个对象,整体打包添加到music_media对象中。
2、使用extend的时候,是将new_media看作一个序列,将这个序列和music_media序列合并,并放在其后面。
result = []
result.extend([1,2,3])
print result
result.append([4,5,6])
print result
result.extend([7,8,9])
print result
结果:
[1, 2, 3]
[1, 2, 3, [4, 5, 6]]
[1, 2, 3, [4, 5, 6], 7, 8, 9]
我们可以在前面的简单样本数据上测试函数splitDataSe(),在python shell 中输入命令:
>>> reload(trees)
<module 'trees' from 'trees.py'>
>>> myDat,labels = trees.createDataSet()
>>> myDat
[[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
>>> trees.splitDataSet(myDat,0,1)
[[1, 'yes'], [1, 'yes'], [0, 'no']]
>>> trees.splitDataSet(myDat,0,0)
[[1, 'no'], [1, 'no']]接下来我们将开始遍历整个数据集,循环计算香农熵和splitDataSet()函数,找到最好的特征划分方式。在trees.py文件中输入下列带代码(选择最好的数据划分方式)
"""
Function:
选择最优特征
Parameters:
dataSet——数据集
Return:
bestFeature——信息增益最大的(最优)特征的索引值
Modify:
2017-12-14
"""
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1
#特征数量
baseEntropy = calcShannonEnt(dataSet)
#计算数据集的最初香农熵
bestInfoGain = 0.0;
#信息增益
bestFeature = -1
#最优特征的索引值
for i in range(numFeatures):
#iterate over all the features 开始遍历数据集中的所有特征
featList = [example[i] for example in dataSet]
#获取dataSet的第i个所有特征
#create a list of all the examples of this feature 使用列表推导来创建一个新的列表,将数据集中的所有第i个特征值或者可能存在的值写入这个新list中
uniqueVals = set(featList)
#创建set集合{},元素不可重复
#get a set of unique values
newEntropy = 0.0
#经验条件熵
for value in uniqueVals:
#计算信息增益
subDataSet = splitDataSet(dataSet, i, value)
#subDataSet划分后的子集
prob = len(subDataSet)/float(len(dataSet))
#计算子集的概率
newEntropy += prob * calcShannonEnt(subDataSet)
#根据公式计算经验条件熵
infoGain = baseEntropy - newEntropy
#信息增益
#calculate the info gain; ie reduction in entropy
if (infoGain > bestInfoGain):
#compare this to the best gain so far
#计算信息增益
bestInfoGain = infoGain
#更新信息增益,找到最大的信息增益
#if better than current best, set to best
bestFeature = i
#记录信息增益最大的特征的索引值
return bestFeature
#返回信息增益最大的特征的索引值list和set的不同之处在于集合类型中的每个值互不相同。从列表中创建set集合是python语言得到list列表中唯一元素值的最快方法。遍历当前特征中的所有唯一属性值,对每个特征值划分一次数据集,然后计算数据集的新熵值,并对所有唯一特征值得到的熵求和。信息增益是香农熵减少或者是无序度的减少。比较所有特征中的信息增益,返回最好的特征划分索引值。
下面开始测试以上代码的输出结果,在python shell 中输入下列代码:
>> reload(trees)
<module 'trees' from 'trees.py'>
>>> myDat,labels = trees.createDataSet()
>>> trees.chooseBestFeatureToSplit(myDat)
0
>>> myDat
[[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]代码运行结果显示,第0个特征为最好用于划分数据集的特征。为了检验这个结果的正确性和实际意义,我们对应前面列出的数据表和myDat中的数据。
如果我们按照第一个特征属性划分数据,也就是说第一个特征是1的放在一个组,第一个特征是0的放在一个组,按照这个方法划分数据集:第一个特征为1的海洋生物分组将有两哥属于鱼类,一个属于非鱼类;另一个分组则全部属于非鱼类。如果按照第二个特征分组:第一个海洋动物分组将有两个属于鱼类,两个属于非鱼类;另一个分组则只有一个非鱼类。不难看出,按照第一个特征分组的正确率高。
3、递归构建决策树
回顾一下工作原理:从数据集构造决策树算法所需要的子功能模块,其工作原理如下:得到原始数据集,然后基于最好的属性值划分数据集,由于特增值可能多于两个,因此可能存在大于两个分支的数据集划分。第一次划分之后,数据将被向下传递到树分支的下一个节点,在这个节点上,我们可以在此划分数据。因此,可以采用递归的原则处理数据集。
递归结束的条件是:程序遍历完所有划分数据集的属性,或者每个分支下的所有实例都具有相同的分类。下图展示划分数据集是的数据路径,如果所有实例具有相同的分类,则得到一个叶子节点或者终止块。
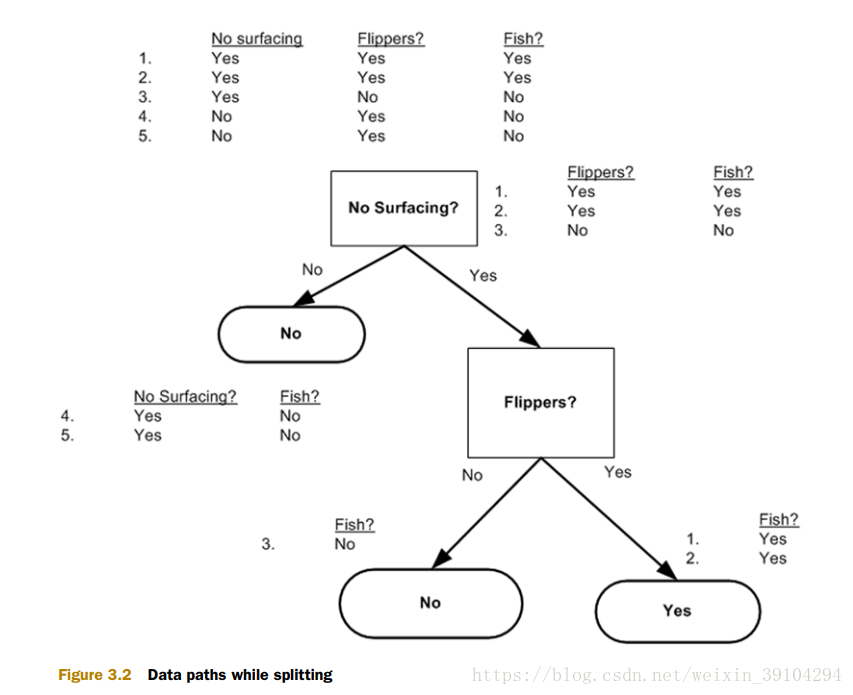
图1 划分数据集是的数据路径