快速排序
分治算法、“原地“排序、非常高效(通过微调)。
- 步骤
1.选取一个关键数据 再根据其大小把原数组分为两个子数组,第一个数组中的数比关键数据小,第二个数组中的数比关键数据大。
2.递归的处理两个子数组的排序。
3.无。 - 函数伪码
partiton(A,p,q)
x ← A[p]
i ← p
for j ← p+1 to q
do if A[j] <= x
then i ← i+1
exch A[i] ←→ A[j]
exch A[p] ←→ A[i]
return i
quicksort(A,p,q)
if p < q
then r ← partition(A,p,q)
quicksort(A,p,r-1)
quicksort(A,r+1,q)
initCall()
quicksort(A,1,n)这种基本算法适合处理无重复项的数据,有重复项的可以用Hoare算法。
- 运行时间:
- 最坏情况:
输入数据本身已经排序或逆排序,划分的一侧始终无元素。
T(n)=T(0)+T(n-1)+Θ(n)
=Θ(1)+T(n-1)+Θ(n)
=T(n-1)+Θ(n)
=Θ(n^2)(递归树法)
- 最坏情况:
- 最优情况:
每次的关键数据处于正中间 划分为两个长度相等的部分
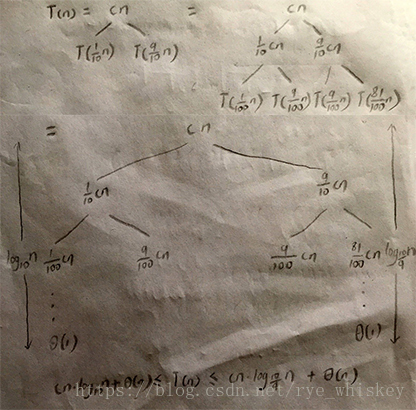
T(n)=2T(n/2)+Θ(n)=Θ(nlgn) - 特殊情况:
每次的关键数据处于特殊位置 比如划分为两个长度分别占1/10 9/10
- 交替产生特殊情况和最坏情况:
L(n)=2U(n/2)+Θ(n)(lucky)
U(n)=L(n-1)+ Θ(n)(unlucky)
Then L(n)=2(L(n/2-1))+Θ(n/2))+Θ(n)
=2L(n/2-1)+Θ(n)
=Θ(nlgn)
随机化快速排序
运行时间不依赖于输入序列的顺序
无需假设输入数据的所有排列是等可能的
没有一种特殊的输入会引起最差的运行效率
最差的情况由随机数产生器决定
随机选主元:
只需在partiton(A,p,q)确定主元之前随机选择数组中的一个元素与第一个交换。
时间复杂度为O(nlgn)
通常比归并排序快三倍以上
课外补充
Why is quicksort faster than other sorting algorithms?
One of the main sources of efficiency in quicksort is locality of reference, where the computer hardware is optimized so that accessing memory locations that are near one another tends to be faster than accessing memory locations scattered throughout memory. The partitioning step in quicksort typically has excellent locality, since it accesses consecutive array elements near the front and the back. As a result, quicksort tends to perform much better than other sorting algorithms like heapsort even though it often does roughly the same number of comparisons and swaps, since in the case of heapsort the accesses are more scattered.
Additionally, quicksort is typically much faster than other sorting algorithms because it operates in-place, without needing to create any auxiliary arrays to hold temporary values. Compared to something like merge sort, this can be a huge advantage because the time required to allocate and deallocate the auxiliary arrays can be noticeable. Operating in-place also improves quicksort’s locality.
When working with linked lists, neither of these advantages necessarily applies. Because linked list cells are often scattered throughout memory, there is no locality bonus to accessing adjacent linked list cells. Consequently, one of quicksort’s huge performance advantages is eaten up. Similarly, the benefits of working in-place no longer apply, since merge sort’s linked list algorithm doesn’t need any extra auxiliary storage space.
That said, quicksort is still very fast on linked lists. Merge sort just tends to be faster because it more evenly splits the lists in half and does less work per iteration to do a merge than to do the partitioning step.